Win32下的Perl,无用的select,停滞的Tk,结束吧....
 2010年3月25日
2010年3月25日
最近写了一个tcltk的rpc脚本,用来远程执行tcl脚本。基本上的思路就是,客户端发出一连串的脚本命令,只要是tcl的都行,函数啊什么的;服务
器端接受后,检测一下,没有语法错误的话,就把运行结果返回给客户端,同时清空缓冲区并等待接下来接收的命令。具体的解释以后再说,也可能不写了。我的想
法是把这个脚本安在一个服务器上,作为一个以tcl脚本为基础的通用服务,执行来自不同客户端的各个任务。
大抵这种两端跑的程序,写的时候没什么,测试的时候就颇为麻烦了。开两个cmd,一边一个server,另一边client,完了为了停下来还得两头按
Control-C,真是一个手忙脚乱啊!
我想这样的测试,一般都是起了服务端,再客户端发一些命令,然后看接受效果就差不多了。完全可以搞在一起,把测试弄成一个脚本来执行,完了一起退出。当然
服务器端脚本和客户端脚本要在不同的环境中运行。这里有两个选择,要么建两个interp,要么用多线程。前段时间用interp用得有点腻味,包括这个
rpc脚本也是用interp来处理不同的客户端连接的,所以这次换用多线程。具体的脚本如下,存为test_in_thread.tcl文件:
package require Thread
package require ltools
foreach file $argv command {server_commands client_commands} {
set $command "source $file"
}
set serv_thread [thread::create $server_commands]
set cli_thread [thread::create $client_commands]
after 5000 {
leach [list $::cli_thread $::serv_thread] [@ {thread} {
thread::release $thread
}]
set delay 1
}
vwait delay
其实很简单,执行的参数包含两个脚本名,分别是服务器端和客户端的;接着,起两个线程,程序等待在delay变量上,5秒之后重设delay并完成退出。
这样以后测试socket程序就方便多了。如上面说的rpc程序,写完之后运行:tcl86 test_in_thread.tcl rpc.tcl
rpc_test.tcl,看看结果就行了。
附件下载
2010年3月15日
Tcl
中没有闭包,但是以字符串为基础的构建使得类似功能的实现并不是一件很困难的事情。在平时的
coding
中倒是经常为一些
Tcl
的规则所困扰。比如说,需要一个用过即丢弃的功能,由于
Tcl
并没有匿名函数一说,为此不得不建立一个命名函数,这个随无伤大雅但在代码的结构上看来却有点扎眼,很让人不爽。
我没有对闭包做深入的研究,所以对于类似闭包功能的使用,仅仅实现了以下的几个功能。第一,一个容易读懂的代码段;第二,具备上下文环境的信息;第三,可在运行时接收参数。
这里所谓容易懂的代码是指不用双引号包围的字符串,虽然使用双引号可以很方便地融入上下文环境中,但是由于转义和执行等情况的存在,不仅不易于编写而且更不容易读明白,因此最好还是用花括号来包围。
第二个问题比较麻烦。对于在花括号中定义的字符串,一般可以使用
subst
来做一些替换工作,但事实上
subst
除了提供延时替换以及
nobackslashes
、
nocommand
控制特征之外,与双引号没有本质上的区别,有些时候甚至不如双引号方便。而即使是用双引号包围了的代码段,依然可能在不经意间造成错误。假设有以下一个程序:
set a jack
set code “ set a mike; puts $a “
在全局环境中,定义了一个值为
jack
的变量
a
;接着,又定义了一个名为
code
的字符串,其中也定义了变量
a
,但是由于存在转义,事实上这个
code
变成了:
set a mike; puts jack
也就是说,如果用
code
来实现闭包的功能,那么将无法在定义与全局中同名的变量。这显然不是很方便,当在类闭包中定义了一个变量的时候,它的作用域应该是属于当前的,而与外层的环境无关,只有没有显式定义的参数我们才需要将其置换为上下文环境中定义的值。
到这里就涉及到一个如何引入上下文环境的问题了,一种就像上面所写的,直接进行变量替换,但是这样做存在副作用;另一种办法是,添加参数定义,即搜索类闭包中的参数,之后在类闭包的开始处添加使用上下文环境的值的定义。还是上面那个例子,使用这个办法,
code
将变为:
set a jack
set a mike; puts $a
倘若
code
中没有
a
的显式定义,则是:
set a jack
puts $a
由于添加的定义永远先于类闭包中代码段的内容,所以无论是否定义同名参数,都不会影响到实际的执行效果。这是一种本地优先的规则,类闭包中没有定义的变量将使用全局替换,而定义了的变量,即使是上下文环境同名变量,依然会使用类闭包中定义的值。
显然作为后一种方法,是恰好能满足我们需要的,不过也面临一个问题,即找出在类比包中的变量名。我用了一个正则判断来得到所有的变量,之后进行筛选以剔除重复并使用
info
函数来验证的确存在该变量。
set unique_vars {}
foreach w [regexp -all -inline {\$[:\w]+} $code] {
foreach u $unique_vars {
if {$u == $w} { continue }
}
lappend unique_vars $w
}
set buf {}
foreach w $unique_vars {
set w [string trimleft $w
\$]
if [uplevel 1 info exists
$w] {
upvar 1 $w var
set buf "$buf set
$w $var;"
}
}
最终得到的
buf
将被放置在
code
之前,实现上下文环境对类比包的作用。
第三问题说明,这个类闭包可以接收传入参数,比如一个类闭包被赋值给名为
lambda
的变量,那么它支持形如
”yield lambda $var”
形式的调用。至于支持传入几个参数,就像
proc
一样,在定义类闭包的时候需要显式说明。
参数传入的实现,在原理上与第二个问题的解决办法类似,但这里的关键在于在与生成的类闭包对象。事实上,该对象包含了两个部分,分别是传入参数的定义和代码段。当执行类闭包的时候,传入的值将和定义的参数结合,被放置于
code
的前端。
最后为了方便使用,我将创建和运行类闭包的命令
fenbie
定义为“
@
”和“
~
”。以下是一个例子:
if 1 {
set name1 jack
set name2 mike
set lamb [ @ {{id 1}} {
if {$id == {}} {
puts {nothing to
puts}
return
}
while {$id > 0} {
puts "hello,
$name1 and $name2"
incr id -1
}
} ]
~ $lamb
puts {}
foreach id {1 2 3} {
puts "$id
time(s):"
~ $lamb $id
puts {}
}
}
closure包下载
2010年2月24日
又重新开始读了《Programming Erlang》,也就又读到了第六章中的makefile,结合学习中的具体情况,略作了修改如下:
.SUFFIXES: .erl .beam
OUT = ./beam
.erl.beam:
erlc -W $< ; mv $@ ${OUT}
ERL = erl -boot start_clean
MODS = kvs
all: compile
compile: ${MODS:%=%.beam}
# application:
# ${ERL} -s application start ARG1 ARG2
clean:
rm -rf *.beam erl_crash.dump
跟书里有的一点不同是,我把编译之后的文件转移到了beam文件夹里了,所以为此,在“~/.erlang”中也添加了该路径:
path_addz("./beam").
这样,就方便载入自己编写的模块。最后还是要对以上的makefile稍作解释,以便以后忘了可以看看。
.SUFFIX声明要用到的或者将生成的文件的类型;.erl.beam是指.beam依赖于.erl,紧接着下一行一个tab之后的是一段有关于这种生成关系的具体命令,我也就是在这里把beam文件移动到./beam文件夹里的;MODS和OUT都是定义的变量,方便重复使用(虽然这里没有再用到,但是至少看起来很清楚);application这个替换被注释掉了,因为我几乎用不到,但也可能以后会用到,除了编译之外,它还负责运行编译之后的模块函数;clean就是删除当前文件夹下的beam文件。
2009年12月21日
ATS for windwos下载 (别放在桌面运行,程序对中文路径支持不好)
最近很不想写随笔,其实是怕写出来丢人。以前啥都不懂的时候,什么都敢写,也不怕出洋相,而现在却害怕拿出来丢人了,就像我现在写文章没
5000
字也不敢出去发。某种意义上说,算是水平有点了吧,虽然这个说法很是贻笑大方。
今天,我把前段时间做的一个用于开发
TclTk
的
IDE
工具用
TDK
打了个包,传上来。从做完到修掉大多数
bug
,之间隔了一段时间,一个原因是做完之后精神一下子放松下来了,没有了干劲;第二个,毕竟是一个人的作品,很难做到面面俱到,不过我也算是尽力而为了。目前的作品是可以拿出来用的,至少我自己是用它来写程序的,一面修改一些
bug
。这次打包的程序中,除了对
Tcl
的支持,还有对
python
的语法着色和缩进支持,但只是很简略的,主要还是为了
Tcl
。
接下来,有空的时候,我会再给它增加几个菜单栏,至少要让它有模有样起来。其实一开始我是打算先做菜单的,因为这个我有经验。相反地对于工具栏我没有什么信心,也不知道该放点什么功能上去,于是花了大力气在这方面,最后反而冷落了菜单的设置。我想这个不难,只是要花点功夫。另外,就以前写的一个提词软件,感谢崔姓同学的建议和提供的国外软件样本,有时间我会改写的。
前段时间,我还参与了联汇公司的
link pro
音频工作站测试和部署工作。逻辑功能是比较完善,不过
UI
乱且不说,简直惨不忍睹,国内的软件普遍有这个坏毛病。不过,把管理站建立在
web
中,我个人认为是一个好的方向,以后可以考虑更多一点的富客户端应用,甚至把整个系统都搬到
web
上去,这也不是不可能,而且无论从安全性还是性能、外观都会上一个台阶。不过,就目前的这个管理站的
ASP.Net
开发水平,这些开发员怕还是不够看。
年终将近,铁塔的工程牵扯了我大半的精力,到目前为止竣工已经不再是遥遥无期的事情了,但还需要加把劲争取在年前完成。以前很喜欢听
911
的歌,后来
coldplay
,间或一直在听
sting
的歌,现在变得只能听班得瑞了
…
人啊总是在朝一个方向走的,什么都拉不住
…
下午的天气很好,休息,休息一下
….
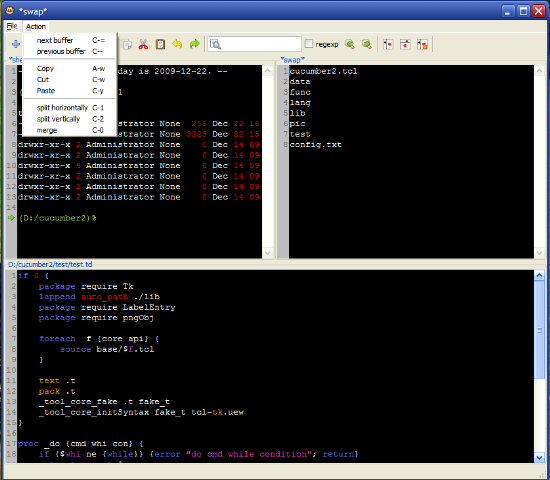
2009年9月29日
其实也并非
Emacs
专有,像
Vim
或者
UE
也有类似的功能,只是我用
Emacs
比较多,所以才取了这个题目。总之,就是将在编辑的一个文本框分割为垂直或者水平的两个相同大小的文本,对于同一个编辑目标,两者保持相同的内容变更,但两者又可分别显示不同的编辑对象,被分割出来的两个文本框又可自行再次分割,以此类推。如果看的迷糊的,自己试试
Emacs
去,“
Control x 2
(
3
)”就行。
这么做的好处在于可以同时观察到两个相关的代码段,有助于查找需要的信息,或者其中一个编辑另一个执行某个如
tclsh
的命令,等等。差不多就是一个多任务的形式,思维比较活跃的人多是喜欢这样开好几个窗口干活。
这个看似简单易用的玩意儿,实现起来却有点让人无从下手。首先,要让两个同编辑目标的文本框保持同步更新;第二,同一个文本框中切换不同编辑对象时,需要保证如语法渲染之类的操作不影响切换速度;第三,保证分割出来的文本框不会改变父窗体的大小。也许还有别的问题,但这三个是让我有点茫然的东西。
经过一番思量,对于第一个问题,应该可以用
rename
注入代码完成。这在我之前写的文章里有很多涉及,这里就具体不讲。只是需要判断一下两个文本框的编辑对象是否一致。如此一来,对于第二个问题,则需要在每次切换的时候将涉及到渲染或者计算的部分以一定结构的数据形式将结果存储起来以备后用,比如将用于作色渲染的
tag
标记都
dump
出来,还有复制内容,当前插入点等等。
不过,在这里我采用了另一种更加优雅的方式,其实是使用了在
Tk8.5
中新加入的
text
组件命令:
peer
,在
actovetcl
的
demo
中也可以看到相关的例子。就是对于一个已建的
text
组件,通过
peer
命令生成它的镜像对象,这两个对象是完全相同的,对任一个的才做都会影响其他对象的变现。事实上,对于一个新建的文本编辑对象,我都首先生成了一个不被
geometry
的
text
对象,用术语说就是
buffer
,再针对这个
buffer
来
peer
出所有需要显示的文本框窗体。那么对于第二个问题,就不是某个
text
组件中内容之间的切换了,而是不同
text
组件之间的切换,可以通过
forget
来完成。这么做的好处在于,我肯本不用考虑切换时状态存储,而且
peer
可以更好地保证编辑对象的一致性要求。
而第三个问题的解决让我对
geometry
中的
place
命令有了全新的认识。众所周知,
geometry
的三种方法中,最被广泛使用的是
pack
,其次是
grid
,最后才是
place
。无论那本介绍
Tk
的书籍,都是按照这个顺寻来编写的。也许是应为
pack
的命令最短,也更通俗易懂一些。但在这里,我不得不使用
place
。对于一个需要被分割的文本框,以下的代码很难控制父窗体的大小。
package require Tk
text .t1
text .t2
pack .t1 –fill both –expand 1
pack forget .t1
pack .t1 .t2 -side left –fill both –expand 1
事实上,这么做的结果是使父窗体加宽了一倍。即使你小心地设定了
text
组件的
width
,一旦
fill
开来就面目全非了。在这里只能使用
place
,结合相对起点与相对长宽,精确设定分割窗体大小。以下是一个实现类以上所讲到和没讲到的功能的完整
demo
,有兴趣的可以看看。其中还包含了切换和关闭
buffer
的快捷键。
split.tcl文件下载
2009年9月25日
有时候重定向是得到执行信息的必要手段,比如我在调试某个程序时需要将调试的输出结果存放到某个文件中以便于日后查看。
1.close stdout
2.set stdout [open out.txt w]
我关闭并重定义了
stdout
,使其成为某个被打开文件的
channel
,那么执行
puts
事实上是完成了对于文本的写操作。在还有一些情况中,是将
stdout
的结果显示到比如
text
这样的
Tk
组件上,以上的办法显然是无能为力了。作为
stdout
本身必须是一个
channel
,它不能作为一个变量或者其他什么的,所以一个替代的办法是使用
Memchan
模块,以下是在
tcl
的
wiki
上的一段代码。
1.package require Tk
2.package require Memchan
3.
4.text .t
5..t tag configure stdout -font {Courier 10}
6..t tag configure stderr -font {Courier 10} -foreground red
7.pack .t
8.
9.# install new stdout
10.close stdout
11.set stdout [fifo]
12.fileevent $stdout readable ".t insert end \[read $stdout\] stdout; .t see end"
13.
14.# install new stderr
15.close stderr
16.set stderr [fifo]
17.fileevent $stderr readable ".t insert end \[read $stderr\] stderr; .t see end"
18.
19.# test it
20.puts "this is stdout"
21.puts stderr "this is stderr"
通过
fileevent
,以上程序提供了一个非常优雅的重定向办法,但是带程序的作者还附加了一句话。事实上,这段代码是无法正确执行的,因为重定义的
stdout
并没有被创建,而且该
bug
似乎至今没有被修复。
warning: the current distribution has a bug, I have submitted a patch to the author
在
cucumber1.1.1
的
tclsh
中需要将
puts
的内容如同
return
的结果一样写入
text
文本组件中,但考虑到循环打印的情况,又不能仅仅将
puts
当做
return
来对待,从而导致执行代码的中止。我的解决办法依然是使用
rename
,在
puts
之前注入代码。
1.con eval {
2. rename puts _puts
3. proc puts {args} {
4. putsstdout $args
5. }
6.}
7.interp alias con putsstdout {} putsstdout
8.proc putsstdout {msg} {
9. .console insert end "$msg\n"
10. .console see end
11.}
模拟
tclsh
的过程是发生在名为
con
的子解析器里的,需要使用
alias
将子解析器中的数据交由主解析器中的函数来更新
.console
中的显示。以上代码中的第
4
行便是重定向的关键所在,当然我们还可以将数据以传统形式输出到
stdout
中,这就看具体情况而定了。事实上,这种办法并不算是真正意义上的重定向,但是得到了相同的效果。
如果用过
Python
的
idle
或者之类的文本型命令行编辑器,你就会发现使用这类工具的可以随意复制黏贴的好处,这比传统的命令行工具方便了很多。但是,传统的优势在于,已执行的命令及得到的返回结果是只读的,不必担心因为误操作破坏历史记录,而这点在
Tk
的
text
组件很难实现。就是说,
text
天然并不支持在一个文本框对象中实现部分只读,而另一部分可写的状态。
text
的
state
选项只能是整个对象处于只读或者可写的状体。那么像
idle
这样的工具是怎么实现局部只读的呢?特别是
idle
本身即是用
Tk
写成的。最初我认为这可能是使用了
canvas
组件里实现类
text
功能,但之后我还是使用了
rename
办法在
text
的
insert
和
delete
命令前注入代码,从而实现这一功能。
1.proc init_region_readonly {text} {
2. rename $text fake
3. proc $text {args} {
4. switch [lindex $args 0] {
5. "insert" {
6. if [fake compare insert >= $::com_region_readonly] {
7. uplevel 1 fake $args
8. }
9. }
10. "delete" {
11. if [fake compare insert > $::com_region_readonly] {
12. uplevel 1 fake $args
13. }
14. }
15. "default" {
16. uplevel 1 fake $args
17. }
18. }
19. }
20.}
在第
6
行和第
11
行里,我增加了对于输入点的判断,也就是说只有当输入点的
index
处于以一个名为
com_region_readonly
的全局变量所指定的位置后时,输入才是有效的,否则将丢弃本次操作。这被应用于
cucumber1.1.1
中所集成的
tclsh
命令行工具中,当然这个工具实现的不仅仅模拟
tclsh
,还有类似于
vim
的文本操作命令,这是基于几个
alias
给子解析器的命令实现的,以后再作介绍。
2009年9月24日
在写代码的时候,不应该仅仅追求完成某件功能,而是需去寻找一个尽量优雅的方法解决。我不单是这么想,而且也的的确确这么做的。在处理
cucumber
的语法高亮模块时,我思考了很久。最后选择了
rename
办法,即是通过
rename
和重载原命令来得到命令参数,实现代码注入。举个例子:
1.package require Tk
2.text .t
3.pack .t
4.rename .t t
5.proc .t {args} {
6. # injected code
7. uplevel #1 t $args
8.}
对于复杂的对象,处于简化使用或者其他的目的,往往会隐藏一些底层的方法,而仅仅提供高级的抽象功能。比如
text
组件的剪切功能,将删除、赋值和标记设定等命令以一定的方式顺序组合在一起,对程序员提供一个指令来完成这一系列的事件。以上的办法为在执行这些底层命令前提供了捕获控制的机会。在高亮的解决方案中,通过这种机制,介入所有的
text
组件指令,筛选出
insert
、
delete
、
mark set
和
see insert
这四个指令,完成当发生包括输入,黏贴、删除,剪切、撤销和重做等事件时的文本高亮渲染。
在这个基本思想的基础上,
cucumber1.1.1
版本实现了关键词、变量、注解和引号语句的高亮,但如在实现顺序上有错疏忽,虽然可能不会对破坏的渲染结果,但是会极大影响大文本渲染的效率。为什么单指大文本,因为对于文本输入一般包括键盘输入和大段文本的载入如打开文件或者黏贴。与电脑的处理相比无论打字速度多快,其中的间歇都是足够渲染处理打入的单个符号的上下文环境;而大文本的载入首先是一次操作完成的,与下一个操作之间只有一次间隔,第二需要渲染的内容很多,这么一来渲染效率的瓶颈边出现在大文本处理上了。所以,我所说的效率可以理解为特指大文本渲染效率。在第二个版本里我是使用了以下的一系列优化代码。在这里我首先通过一下函数完成捕获
1.proc _tool_core_fake {cucumber fake} {
2. set ::$fake [regsub
{(.*)\..+$} $cucumber {\1.linumColumn}]
3. rename $cucumber $fake
4. eval "proc $cucumber
{args} {
5. after idle
\[_tool_core_sortMap $fake \$args\]
6. uplevel 1 $fake
\$args
7. }"
8.}
_tool_core_fake
第
2
行是设置了一个与当前
text
文本相对应的行号显示组件变量,这里就不再多说了。真正的高亮渲染注入发生在第
5
行,通过以下的函数返回需要执行的指令集。
1.proc
_tool_core_sortMap {fake args} {
2. eval "set args $args"
3. switch -glob -- $args {
4. insert* {
5. set from [$fake index [lindex $args
1]]
6. set to "$from+[string length
[lindex $args 2]]c"
7. return "
8. _tool_core_hiContent $fake $from
$to;
9. _tool_incrLinum $fake;
10.
_tool_core_hiLine $fake
11. "
12. }
13. delete* {
14. set from [$fake
index [lindex $args 1]]
15. return "
16. _tool_core_hiContent $fake $from $from;
17. _tool_decrLinum
$fake
18.
_tool_core_hiLine $fake
19. "
20. }
21. {mark set insert*} {
return "_tool_core_hiLine $fake" }
22. {see insert} {
return "_tool_core_hiLine $fake" }
23. }
24.}
_tool_core_sortMap
第二行的作用是消除字符串外的大括号,将如“
{insert end nihao}
”变化为“
insert end nihao
”。之后使用
glob
匹配的
switch
来筛选命令参数。在
1.1.1
版本的筛选函数中,首先我没有加入用于筛选高亮当前行显示的
insert
标记判断,而是在单独的模块中通过绑定事件来完成,这显然是累赘的;第二,最初使用
none
函数来处理非匹配的指令,这个自以为保证代码一致性的手法在事后证明是一个画蛇添足的举动,因为即使是一个空函数,也存在执行消耗,而大量累加执行的结果就是拖慢渲染的速度,这在
1.1.1
中已经被删除了;另外,在处理
insert
和
delete
时,存在值得商榷的渲染级别。在目前代码中可以看见,事实上渲染发生在以上代码的第
8
行和第
16
行里的
_tool_core_hiContent
函数里。顺便提一下,在该函数以下的两个命令,跟行号和当前行指示有关,这里不做详解。
1.proc _tool_core_hiContent {fake from to} {
2. set temp $from
3. set temp
[_tool_core_hiWord $fake $temp]
4. while {[$fake compare
$temp <= $to]} {
5. set temp
[_tool_core_hiWord $fake $temp]
6. }
7. _tool_core_hiQuoteContext
$fake
8.
_tool_core_hiCommentContext $fake $from $to
9.}
_tool_core_hiContent
在
_tool_core_hiConetnt
的文本渲染函数中,包含了三个同层次的渲染,分别是处于
index
位于
from
和
to
之间的单词循环渲染和各行注解渲染,以及一次全文引号渲染。这么安排的道理在于,一般情况系关键词和变量都是以单词的形式出现的,可以统一在
_tool_core_hiWord
中处理;注解可能占据一行或者后半行,与其在每次单词渲染时判断是否存在注解起始符,不如在处理完所有的单词之后统一检索当前文本段,前者是单词数量级的运算,而后者是行数量级的运算,显然后者更为高效;引号数量的单双数变化,会造成全文渲染范围的颠倒,但考虑到引号数量与单词相比可能相差两三个数量级,因此这种全文渲染变化是很快速的,尤其是我更引入了延迟渲染的机制,消耗更是可以忽略不计。以下是这三个函数。
1.proc
_tool_core_hiWord {fake id} {
2. if [_tool_ifInWord $fake $id] {
3. set head [_tool_indexWordHead $fake $id]
4. set end
[_tool_indexWordEnd $fake $id]
5. foreach hi {
6. _tool_core_hiTextContext
7. _tool_core_hiVariableContext
8. } { $hi $fake $head $end}
9. return "$end +1c"
10. }
11. return "$id +1c"
12.}
_tool_core_hiWord
1
.
proc
_tool_core_hiCommentContext {fake from to} {
2. set f [_tool_linum $fake $from]
3. set t [_tool_linum $fake $to]
4. while {$f <= $t} {
5. $fake tag remove Com "$f.0"
"$f.0 lineend"
6. if {[$fake search -regexp
$::hi_comment_regexp "$f.0" "$f.0 lineend"] != {}} {
7. $fake tag add Com [$fake search
-regexp $::hi_comment_symbol "$f.0" "$f.0 lineend"]
"$f.0 lineend"
8. }
9. incr f
10. }
11.}
_tool_core_hiCommentContext
1.proc
_tool_core_hiQuoteContext {fake} {
2. after cancel [list _hiQuoteContext $fake]
3. after
1000 [list _hiQuoteContext $fake]
4.}
5.proc
_hiQuoteContext {fake} {
6. if {[$fake get 1.0] == "\""}
{ set rid [list 1.0] } else { set rid {} }
7. set qid [$fake search -nolinestop -overlap
-all -regexp {[^\\]\"} 1.0 end]
8. foreach id $qid { lappend rid [$fake index
[$fake index "$id + 1c"]]
}
9.
10. if ![set e [llength
$rid]] {return}
11. set now [lindex $rid 0]
12. $fake tag remove Quo 1.0
$now
13
.
14. set i 1
15. while {$i < $e} {
16. set old $now
17. set now [lindex $rid
$i]
18. if [expr $i % 2] {
19. $fake tag add
Quo $old "$now +1c"
20. } else {
21. $fake tag remove
Quo "$old +1c" $now
22. }
23. incr i
24. }
25.
26. if [expr $e % 2] {
27. $fake tag add Quo
"$now +1c" end
28. } else {
29. $fake tag remove Quo
"$now +1c" end
30. }
31.}
_tool_core_hiQuoteContext
2009年9月21日
最近一直在做cucuber的第二个版本。为什么要做第二个呢?这是因为,在对cucuber做了大量修改之后,目前稳定的版本是1.1.1版,基本上应付日程的代码编写已经没有什么大问题了,支持包括语法高亮、自动补全、自动缩进和正则查找等,但是还是存在一些问题。比如说,绝大多数的函数直接使用了Tk的组件路径,于是乎除非重写所有函数,不然无法支持多文档显示。另外,应该更清晰地割离不同语言的语法高亮,包括关键词,注解,变量等。还有一个最重要的待改进环节就是提升高亮的渲染速度。在早些时候写目前高亮引擎的时候,我采用了高亮的过程与快捷键绑定的方式,导致了代码非常臃肿且结构混杂。基本上就是一个打补丁的过程,哪个事件的高亮不对就修改哪个,虽然目前看来确实是对高亮支持地很好,但是代码已经面目全非,另外注解和字符串渲染的时机也有些问题,导致了很多重复的操作,降低了整体速度。现在在赛扬D3.33G、512兆内存的环境下,打开一个20k左右的文件,渲染速度约为4秒,即使对于TclTk这样的脚本,这个时长也是很难让人满意的。
所以这次工程的目标就此确定,重写所有函数为可复用,提高渲染速度,重新编写工程架构为可扩展多文档显示,最后添加一个整理代码的工具。目前的渲染部分代码工作基本完成,速度提高了4-5倍,对于小文件基本上做到载入即可渲染完成,80k左右的代码也只需4秒。
Cucumber1.1.1代码下载
2009年8月16日
最近在看
WebOS
和
Android
的相关资料,也算是学习吧,虽然并没有作进一步的深入开发的打算。
WebOS
的资料很少,现在能看的除了官网的
document
之外,只有一本《
Palm WebOS
》,我看的是
Rough Cut
版本的。
Android
的书籍就比较多了,甚至国人也有些的,这里要提醒切勿上当的的是一本宝岛某人写的,纯
Java
介绍加官网
Doc
,很春哥。我现在看的是一本叫《
Beginning Android
》的书,除了不多久,而且由浅入较深。这里说是较深,是因为较本书的目的来说是为了入门,所以不能算深;但是仔细读完这本书,我相信对
Android
的开发肯定能得心应手,至少能自己解决一些问题了,所以算是深的范围里了,综上所述用较深。一向来,我是很喜欢这种书的,因为学习效率高,文笔好的,更是看着如沐春风。至于《
Palm WebOS
》,我只能用痛苦来形容。举个例子吧,其中大量引用了一个提供每日信息的类似于
RSS
的
News
案例。应该说,这算是开发中的一个综合性高级应用了,最好是将它单独立为一章,在书的最后几个章节种。可本书,从第二章开始开始介绍,写了一个基本框架。第三章,在介绍
list
组件的时候,又拿了出来,改了一些数据之后,一讲到底,连
Ajax
都顺便说完了,这是很不好的。首先,其中有很多概念还没涉及到,你就拿出来讲,读者看不懂;第二,看不懂,可还得硬着头皮看,因为有很多细节他是穿插在里面的,不看,以后就更看不懂了;第三,这样就增加了学习的难度,无异于拔苗助长,看过去了,恭喜你,但更多人会将此书束之高阁了。我的做法是两本书一起看,一本卡住了先看看另外一本,等心情平复了再回过来看,如此交叉前进。这里有个前提是,这两本书都是关于移动开发的,虽然所属系统不同,但终究是一个大类,有相通可比较之处,一起看有利于总接归纳,算是相得益彰了。
另外,
WebOS
的开发终究是少了点调试的工具,虽然我很讨厌
Java
,但是难以调试的
WebOS
更令人痛疼,虽然开发的过程显然是
Js
来的舒畅。