(转载)异步IO、APC、IO完成端口、线程池与高性能服务器
转载: http://www.vchelp.net/
原作者姓名 Fang(fangguicheng@21cn.com)
异步IO、APC、IO完成端口、线程池与高性能服务器之一 异步IO
背景:轮询 PIO DMA 中断
早期IO设备的速度与CPU相比,还不是太悬殊。CPU定时轮询一遍IO设备,看看有无处理要求,有则加以处理,完成后返回继续工作。至今,软盘驱动器还保留着这种轮询工作方式。
随着CPU性能的迅速提高,这种效率低下的工作方式浪费了大量的CPU时间。因此,中断工作方式开始成为普遍采用的技术。这种技术使得IO设备在需要得到服务时,能够产生一个硬件中断,迫使CPU放弃目前的处理任务,进入特定的中断服务过程,中断服务完成后,再继续原先的处理。这样一来,IO设备和CPU可以同时进行处理,从而避免了CPU等待IO完成。
早期数据的传输方式主要是PIO(程控IO)方式。通过对IO地址编程方式的方式来传输数据。比如串行口,软件每次往串行口上写一个字节数据,串口设备完成传输任务后,将会产生一个中断,然后软件再次重复直到全部数据发送完成。性能更好的硬件设备提供一个FIFO(先进先出缓冲部件),可以让软件一次传输更多的字节。
显然,使用PIO方式对于高速IO设备来说,还是占用了太多的CPU时间(因为需要通过CPU编程控制传输)。而DMA(直接内存访问)方式能够极大地减少CPU处理时间。CPU仅需告诉DMA控制器数据块的起始地址和大小,以后DMA控制器就可以自行在内存和设备之间传输数据,其间CPU可以处理其他任务。数据传输完毕后将会产生一个中断。
同步文件IO和异步文件IO:
下面摘抄于MSDN《synchronous file I/O and asynchronous file I/O》。
有两种类型的文件IO同步:同步文件IO和异步文件IO。异步文件IO也就是重叠IO。
在同步文件IO中,线程启动一个IO操作然后就立即进入等待状态,直到IO操作完成后才醒来继续执行。
而异步文件IO方式中,线程发送一个IO请求到内核,然后继续处理其他的事情,内核完成IO请求后,将会通知线程IO操作完成了。
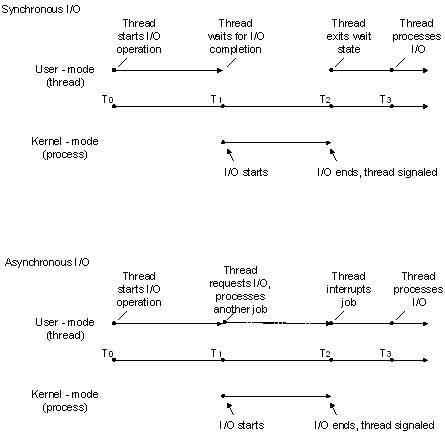
如果IO请求需要大量时间执行的话,异步文件IO方式可以显著提高效率,因为在线程等待的这段时间内,CPU将会调度其他线程进行执行,如果没有其他线程需要执行的话,这段时间将会浪费掉(可能会调度操作系统的零页线程)。如果IO请求操作很快,用异步IO方式反而还低效,还不如用同步IO方式。
同步IO在同一时刻只允许一个IO操作,也就是说对于同一个文件句柄的IO操作是序列化的,即使使用两个线程也不能同时对同一个文件句柄同时发出读写操作。重叠IO允许一个或多个线程同时发出IO请求。
异步IO在请求完成时,通过将文件句柄设为有信号状态来通知应用程序,或者应用程序通过GetOverlappedResult察看IO请求是否完成,也可以通过一个事件对象来通知应用程序。
Alertable IO(告警IO)提供了更有效的异步通知形式。ReadFileEx / WriteFileEx在发出IO请求的同时,提供一个回调函数(APC过程),当IO请求完成后,一旦线程进入可告警状态,回调函数将会执行。
以下五个函数能够使线程进入告警状态:
SleepEx
WaitForSingleObjectEx
WaitForMultipleObjectsEx
SignalObjectAndWait
MsgWaitForMultipleObjectsEx
线程进入告警状态时,内核将会检查线程的APC队列,如果队列中有APC,将会按FIFO方式依次执行。如果队列为空,线程将会挂起等待事件对象。以后的某个时刻,一旦APC进入队列,线程将会被唤醒执行APC,同时等待函数返回WAIT_IO_COMPLETION。
QueueUserAPC可以用来人为投递APC,只要目标线程处于告警状态时,APC就能够得到执行。
使用告警IO的主要缺点是发出IO请求的线程也必须是处理结果的线程,如果一个线程退出时还有未完成的IO请求,那么应用程序将永远丢失IO完成通知。然而以后我们将会看到IO完成端口没有这个限制。
下面的代码演示了QueueUserAPC的用法。
/*********************************************/
/* APC Test.*/
/*********************************************/
DWORD WINAPI WorkThread(PVOID pParam)
{
HANDLE Event = (HANDLE)pParam;
for(;;)
{
DWORD dwRet = WaitForSingleObjectEx(Event, INFINITE, TRUE);
if(dwRet == WAIT_OBJECT_0)
break;
else if(dwRet == WAIT_IO_COMPLETION)
printf("WAIT_IO_COMPLETION\n");
}
return 0;
}
VOID CALLBACK APCProc(DWORD dwParam)
{
printf("%s", (PVOID)dwParam);
}
void TestAPC(BOOL bFast)
{
HANDLE QuitEvent = CreateEvent(NULL, FALSE, FALSE, NULL);
HANDLE hThread = CreateThread(NULL,
0,
WorkThread,
(PVOID)QuitEvent,
0,
NULL);
Sleep(100); // Wait for WorkThread initialized.
for(int i=5; i>0; i--)
{
QueueUserAPC(APCProc, hThread, (DWORD)(PVOID)"APC here\n");
if(!bFast)
Sleep(1000);
}
SetEvent(QuitEvent);
WaitForSingleObject(hThread, INFINITE);
CloseHandle(hThread);
}
下面摘抄于MSDN《I/O Completion Ports》,smallfool翻译,原文请参考CSDN文档中心文章《I/O Completion Ports》, http://dev.csdn.net/Develop/article/29%5C29240.shtm 。
I/O完成端口是一种机制,通过这个机制,应用程序在启动时会首先创建一个线程池,然后该应用程序使用线程池处理异步I/O请求。这些线程被创建的唯一目的就是用于处理I/O请求。对于处理大量并发异步I/O请求的应用程序来说,相比于在I/O请求发生时创建线程来说,使用完成端口(s)它就可以做的更快且更有效率。
CreateIoCompletionPort函数会使一个I/O完成端口与一个或多个文件句柄发生关联。当与一个完成端口相关的文件句柄上启动的异步I/O操作完成时,一个I/O完成包就会进入到该完成端口的队列中。对于多个文件句柄来说,这种机制可以用来把多文件句柄的同步点放在单个对象中。(言下之意,如果我们需要对每个句柄文件进行同步,一般而言我们需要多个对象(如:Event来同步)。
而我们使用IO Complete Port 来实现异步操作,我们可以同多个文件相关联,每当一个文件中的异步操作完成,就会把一个complete package放到队列中,这样我们就可以使用这个来完成所有文件句柄的同步)
调用GetQueuedCompletionStatus函数,某个线程就会等待一个完成包进入到完成端口的队列中,而不是直接等待异步I/O请求完成。线程(们)就会阻塞于它们的运行在完成端口(按照后进先出队列顺序的被释放)。这就意味着当一个完成包进入到完成端口的队列中时,系统会释放最近被阻塞在该完成端口的线程。
调用GetQueuedCompletionStatus,线程就会将会与某个指定的完成端口建立联系,一直延续其该线程的存在周期,或被指定了不同的完成端口,或者释放了与完成端口的联系。一个线程只能与最多不超过一个的完成端口发生联系。
完成端口最重要的特性就是并发量。完成端口的并发量可以在创建该完成端口时指定。该并发量限制了与该完成端口相关联的可运行线程的数目。当与该完成端口相关联的可运行线程的总数目达到了该并发量,系统就会阻塞任何与该完成端口相关联的后续线程的执行,直到与该完成端口相关联的可运行线程数目下降到小于该并发量为止。
最有效的假想是发生在有完成包在队列中等待,而没有等待被满足,因为此时完成端口达到了其并发量的极限。此时,一个正在运行中的线程调用GetQueuedCompletionStatus时,它就会立刻从队列中取走该完成包。这样就不存在着环境的切换,因为该处于运行中的线程就会连续不断地从队列中取走完成包,而其他的线程就不能运行了。
对于并发量最好的挑选值就是您计算机中CPU的数目。如果您的事务处理需要一个漫长的计算时间,一个比较大的并发量可以允许更多线程来运行。虽然完成每个事务处理需要花费更长的时间,但更多的事务可以同时被处理。对于应用程序来说,很容易通过测试并发量来获得最好的效果。
PostQueuedCompletionStatus函数允许应用程序可以针对自定义的专用I/O完成包进行排队,而无需启动一个异步I/O操作。这点对于通知外部事件的工作者线程来说很有用。
在没有更多的引用针对某个完成端口时,需要释放该完成端口。该完成端口句柄以及与该完成端口相关联的所有文件句柄都需要被释放。调用CloseHandle可以释放完成端口的句柄。
下面的代码利用IO完成端口做了一个简单的线程池。
/*********************************************/
/* Test IOCompletePort.*/
/*********************************************/
DWORD WINAPI IOCPWorkThread(PVOID pParam)
{
HANDLE CompletePort = (HANDLE)pParam;
PVOID UserParam;
WORK_ITEM_PROC UserProc;
LPOVERLAPPED pOverlapped;
for(;;)
{
BOOL bRet = GetQueuedCompletionStatus(
CompletePort,
(LPDWORD)&UserParam,
(LPDWORD)&UserProc,
&pOverlapped,
INFINITE);
_ASSERT(bRet);
if(UserProc == NULL) // Quit signal.
break;
// execute user's proc.
UserProc(UserParam);
}
return 0;
}
void TestIOCompletePort(BOOL bWaitMode, LONG ThreadNum)
{
HANDLE CompletePort;
OVERLAPPED Overlapped = {0, 0, 0, 0, NULL};
CompletePort = CreateIoCompletionPort(
INVALID_HANDLE_VALUE,
NULL,
NULL,
0);
// Create threads.
for(int i=0; i<ThreadNum; i++)
{
HANDLE hThread = CreateThread(NULL,
0,
IOCPWorkThread,
CompletePort,
0,
NULL);
CloseHandle(hThread);
}
CompleteEvent = CreateEvent(NULL, FALSE, FALSE, NULL);
BeginTime = GetTickCount();
ItemCount = 20;
for(i=0; i<20; i++)
{
PostQueuedCompletionStatus(
CompletePort,
(DWORD)bWaitMode,
(DWORD)UserProc1,
&Overlapped);
}
WaitForSingleObject(CompleteEvent, INFINITE);
CloseHandle(CompleteEvent);
// Destroy all threads.
for(i=0; i<ThreadNum; i++)
{
PostQueuedCompletionStatus(
CompletePort,
NULL,
NULL,
&Overlapped);
}
Sleep(1000); // wait all thread exit.
CloseHandle(CompletePort);
}
下面摘抄于MSDN《Thread Pooling》。
有许多应用程序创建的线程花费了大量时间在睡眠状态来等待事件的发生。还有一些线程进入睡眠状态后定期被唤醒以轮询工作方式来改变或者更新状态信息。线程池可以让你更有效地使用线程,它为你的应用程序提供一个由系统管理的工作者线程池。至少会有一个线程来监听放到线程池的所有等待操作,当等待操作完成后,线程池中将会有一个工作者线程来执行相应的回调函数。
你也可以把没有等待操作的工作项目放到线程池中,用QueueUserWorkItem函数来完成这个工作,把要执行的工作项目函数通过一个参数传递给线程池。工作项目被放到线程池中后,就不能再取消了。
Timer-queue timers和Registered wait operations也使用线程池来实现。他们的回调函数也放在线程池中。你也可以用BindIOCompletionCallback函数来投递一个异步IO操作,在IO完成端口上,回调函数也是由线程池线程来执行。
当第一次调用QueueUserWorkItem函数或者BindIOCompletionCallback函数的时候,线程池被自动创建,或者Timer-queue timers或者Registered wait operations放入回调函数的时候,线程池也可以被创建。线程池可以创建的线程数量不限,仅受限于可用的内存,每一个线程使用默认的初始堆栈大小,运行在默认的优先级上。
线程池中有两种类型的线程:IO线程和非IO线程。IO线程等待在可告警状态,工作项目作为APC放到IO线程中。如果你的工作项目需要线程执行在可警告状态,你应该将它放到IO线程。
非IO工作者线程等待在IO完成端口上,使用非IO线程比IO线程效率更高,也就是说,只要有可能的话,尽量使用非IO线程。IO线程和非IO线程在异步IO操作没有完成之前都不会退出。然而,不要在非IO线程中发出需要很长时间才能完成的异步IO请求。
正确使用线程池的方法是,工作项目函数以及它将会调用到的所有函数都必须是线程池安全的。安全的函数不应该假设线程是一次性线程的或者是永久线程。一般来说,应该避免使用线程本地存储和发出需要永久线程的异步IO调用,比如说RegNotifyChangeKeyValue函数。如果需要在永久线程中执行这样的函数的话,可以给QueueUserWorkItem传递一个选项WT_EXECUTEINPERSISTENTTHREAD。
注意,线程池不能兼容COM的单线程套间(STA)模型。
为了更深入地讲解操作系统实现的线程池的优越性,我们首先尝试着自己实现一个简单的线程池模型。
代码如下:
/*********************************************/
/* Test Our own thread pool.*/
/*********************************************/
typedef struct _THREAD_POOL
{
HANDLE QuitEvent;
HANDLE WorkItemSemaphore;
LONG WorkItemCount;
LIST_ENTRY WorkItemHeader;
CRITICAL_SECTION WorkItemLock;
LONG ThreadNum;
HANDLE *ThreadsArray;
}THREAD_POOL, *PTHREAD_POOL;
typedef VOID (*WORK_ITEM_PROC)(PVOID Param);
typedef struct _WORK_ITEM
{
LIST_ENTRY List;
WORK_ITEM_PROC UserProc;
PVOID UserParam;
}WORK_ITEM, *PWORK_ITEM;
DWORD WINAPI WorkerThread(PVOID pParam)
{
PTHREAD_POOL pThreadPool = (PTHREAD_POOL)pParam;
HANDLE Events[2];
Events[0] = pThreadPool->QuitEvent;
Events[1] = pThreadPool->WorkItemSemaphore;
for(;;)
{
DWORD dwRet = WaitForMultipleObjects(2, Events, FALSE, INFINITE);
if(dwRet == WAIT_OBJECT_0)
break;
//
// execute user's proc.
//
else if(dwRet == WAIT_OBJECT_0 +1)
{
PWORK_ITEM pWorkItem;
PLIST_ENTRY pList;
EnterCriticalSection(&pThreadPool->WorkItemLock);
_ASSERT(!IsListEmpty(&pThreadPool->WorkItemHeader));
pList = RemoveHeadList(&pThreadPool->WorkItemHeader);
LeaveCriticalSection(&pThreadPool->WorkItemLock);
pWorkItem = CONTAINING_RECORD(pList, WORK_ITEM, List);
pWorkItem->UserProc(pWorkItem->UserParam);
InterlockedDecrement(&pThreadPool->WorkItemCount);
free(pWorkItem);
}
else
{
_ASSERT(0);
break;
}
}
return 0;
}
BOOL InitializeThreadPool(PTHREAD_POOL pThreadPool, LONG ThreadNum)
{
pThreadPool->QuitEvent = CreateEvent(NULL, TRUE, FALSE, NULL);
pThreadPool->WorkItemSemaphore = CreateSemaphore(NULL, 0, 0x7FFFFFFF, NULL);
pThreadPool->WorkItemCount = 0;
InitializeListHead(&pThreadPool->WorkItemHeader);
InitializeCriticalSection(&pThreadPool->WorkItemLock);
pThreadPool->ThreadNum = ThreadNum;
pThreadPool->ThreadsArray = (HANDLE*)malloc(sizeof(HANDLE) * ThreadNum);
for(int i=0; i<ThreadNum; i++)
{
pThreadPool->ThreadsArray[i] = CreateThread(NULL, 0, WorkerThread, pThreadPool, 0, NULL);
}
return TRUE;
}
VOID DestroyThreadPool(PTHREAD_POOL pThreadPool)
{
SetEvent(pThreadPool->QuitEvent);
for(int i=0; i<pThreadPool->ThreadNum; i++)
{
WaitForSingleObject(pThreadPool->ThreadsArray[i], INFINITE);
CloseHandle(pThreadPool->ThreadsArray[i]);
}
free(pThreadPool->ThreadsArray);
CloseHandle(pThreadPool->QuitEvent);
CloseHandle(pThreadPool->WorkItemSemaphore);
DeleteCriticalSection(&pThreadPool->WorkItemLock);
while(!IsListEmpty(&pThreadPool->WorkItemHeader))
{
PWORK_ITEM pWorkItem;
PLIST_ENTRY pList;
pList = RemoveHeadList(&pThreadPool->WorkItemHeader);
pWorkItem = CONTAINING_RECORD(pList, WORK_ITEM, List);
free(pWorkItem);
}
}
BOOL PostWorkItem(PTHREAD_POOL pThreadPool, WORK_ITEM_PROC UserProc, PVOID UserParam)
{
PWORK_ITEM pWorkItem = (PWORK_ITEM)malloc(sizeof(WORK_ITEM));
if(pWorkItem == NULL)
return FALSE;
pWorkItem->UserProc = UserProc;
pWorkItem->UserParam = UserParam;
EnterCriticalSection(&pThreadPool->WorkItemLock);
InsertTailList(&pThreadPool->WorkItemHeader, &pWorkItem->List);
LeaveCriticalSection(&pThreadPool->WorkItemLock);
InterlockedIncrement(&pThreadPool->WorkItemCount);
ReleaseSemaphore(pThreadPool->WorkItemSemaphore, 1, NULL);
return TRUE;
}
VOID UserProc1(PVOID dwParam)
{
WorkItem(dwParam);
}
void TestSimpleThreadPool(BOOL bWaitMode, LONG ThreadNum)
{
THREAD_POOL ThreadPool;
InitializeThreadPool(&ThreadPool, ThreadNum);
CompleteEvent = CreateEvent(NULL, FALSE, FALSE, NULL);
BeginTime = GetTickCount();
ItemCount = 20;
for(int i=0; i<20; i++)
{
PostWorkItem(&ThreadPool, UserProc1, (PVOID)bWaitMode);
}
WaitForSingleObject(CompleteEvent, INFINITE);
CloseHandle(CompleteEvent);
DestroyThreadPool(&ThreadPool);
}
我们把工作项目放到一个队列中,用一个信号量通知线程池,线程池中任意一个线程取出工作项目来执行,执行完毕之后,线程返回线程池,继续等待新的工作项目。
线程池中线程的数量是固定的,预先创建好的,永久的线程,直到销毁线程池的时候,这些线程才会被销毁。
线程池中线程获得工作项目的机会是均等的,随机的,并没有特别的方式保证哪一个线程具有特殊的优先获得工作项目的机会。
而且,同一时刻可以并发运行的线程数目没有任何限定。事实上,在我们的执行计算任务的演示代码中,所有的线程都并发执行。
下面,我们再来看一下,完成同样的任务,系统提供的线程池是如何运作的。
/*********************************************/
/* QueueWorkItem Test.*/
/*********************************************/
DWORD BeginTime;
LONG ItemCount;
HANDLE CompleteEvent;
int compute()
{
srand(BeginTime);
for(int i=0; i<20 *1000 * 1000; i++)
rand();
return rand();
}
DWORD WINAPI WorkItem(LPVOID lpParameter)
{
BOOL bWaitMode = (BOOL)lpParameter;
if(bWaitMode)
Sleep(1000);
else
compute();
if(InterlockedDecrement(&ItemCount) == 0)
{
printf("Time total %d second.\n", GetTickCount() - BeginTime);
SetEvent(CompleteEvent);
}
return 0;
}
void TestWorkItem(BOOL bWaitMode, DWORD Flag)
{
CompleteEvent = CreateEvent(NULL, FALSE, FALSE, NULL);
BeginTime = GetTickCount();
ItemCount = 20;
for(int i=0; i<20; i++)
{
QueueUserWorkItem(WorkItem, (PVOID)bWaitMode, Flag);
}
WaitForSingleObject(CompleteEvent, INFINITE);
CloseHandle(CompleteEvent);
}
很简单,是吧?我们仅需要关注于我们的回调函数即可。但是与我们的简单模拟来比,系统提供的线程池有着更多的优点。
首先,线程池中线程的数目是动态调整的,其次,线程池利用IO完成端口的特性,它可以限制并发运行的线程数目,默认情况下,将会限制为CPU的数目,这可以减少线程切换。它挑选最近执行过的线程再次投入执行,从而避免了不必要的线程切换。
作为一个网络服务器程序,性能永远是第一位的指标。性能可以这样定义:在给定的硬件条件和时间里,能够处理的任务量。能够最大限度地利用硬件性能的服务器设计才是良好的设计。
设计良好的服务器还应该考虑平均服务,对于每一个客户端,服务器应该给予每个客户端平均的服务,不能让某一个客户端长时间得不到服务而发生“饥饿”的状况。
可伸缩性,也就是说,随着硬件能力的提高,服务器的性能能够随之呈线性增长。
实现高性能的途径
一个实际的服务器的计算是很复杂的,往往是混合了IO计算和CPU计算。IO计算指计算任务中以IO为主的计算模型,比如文件服务器、邮件服务器等,混合了大量的网络IO和文件IO;CPU计算指计算任务中没有或很少有IO,比如加密/解密,编码/解码,数学计算等等。
在CPU计算中,单线程和多线程模型效果是相当的。《Win32多线程的性能》中说“在一个单处理器的计算机中,基于 CPU 的任务的并发执行速度不可能比串行执行速度快,但是我们可以看到,在 Windows NT 下线程创建和切换的额外开销非常小;对于非常短的计算,并发执行仅仅比串行执行慢 10%,而随着计算长度的增加,这两个时间就非常接近了。”
可见,对于纯粹的CPU计算来说,如果只有一个CPU,多线程模型是不合适的。考虑一个执行密集的CPU计算的服务,如果有几十个这样的线程并发执行,过于频繁地任务切换导致了不必要的性能损失。
在编程实现上,单线程模型计算模型对于服务器程序设计是很不方便的。因此,对于CPU计算采用线程池工作模型是比较恰当的。QueueUserWorkItem函数非常适合于将一个CPU计算放入线程池。线程池实现将会努力减少这种不必要的线程切换,而且控制并发线程的数目为CPU的数目。
我们真正需要关心的是IO计算,一般的网络服务器程序往往伴随着大量的IO计算。提高性能的途径在于要避免等待IO 的结束,造成CPU空闲,要尽量利用硬件能力,让一个或多个IO设备与CPU并发执行。前面介绍的异步IO,APC,IO完成端口都可以达到这个目的。
对于网络服务器来说,如果客户端并发请求数目比较少的话,用简单的多线程模型就可以应付了。如果一个线程因为等待IO操作完成而被挂起,操作系统将会调度另外一个就绪的线程投入运行,从而形成并发执行。经典的网络服务器逻辑大多采用多线程/多进程方式,在一个客户端发起到服务器的连接时,服务器将会创建一个线程,让这个新的线程来处理后续事务。这种以一个专门的线程/进程来代表一个客户端对象的编程方法非常直观,易于理解。
对于大型网络服务器程序来说,这种方式存在着局限性。首先,创建线程/进程和销毁线程/进程的代价非常高昂,尤其是在服务器采用TCP“短连接”方式或UDP方式通讯的情况下,例如,HTTP协议中,客户端发起一个连接后,发送一个请求,服务器回应了这个请求后,连接也就被关闭了。如果采用经典方式设计HTTP服务器,那么过于频繁地创建线程/销毁线程对性能造成的影响是很恶劣的。
其次,即使一个协议中采取TCP“长连接”,客户端连上服务器后就一直保持此连接,经典的设计方式也是有弊病的。如果客户端并发请求量很高,同一时刻有很多客户端等待服务器响应的情况下,将会有过多的线程并发执行,频繁的线程切换将用掉一部分计算能力。实际上,如果并发线程数目过多的话,往往会过早地耗尽物理内存,绝大部分时间耗费在线程切换上,因为线程切换的同时也将引起内存调页。最终导致服务器性能急剧下降。
对于一个需要应付同时有大量客户端并发请求的网络服务器来说,线程池是唯一的解决方案。线程池不光能够避免频繁地创建线程和销毁线程,而且能够用数目很少的线程就可以处理大量客户端并发请求。
值得注意的是,对于一个压力不大的网络服务器程序设计,我们并不推荐以上任何技巧。在简单的设计就能够完成任务的情况下,把事情弄得很复杂是很不明智,很愚蠢的行为。