1 Inter prediction
Inter prediction is the process of predicting a block of luma and chroma samples from a picture that has previously been coded and transmitted, a reference picture. This involves selecting a prediction region, generating a prediction block and subtracting this from the original block of samples to form a residual that is then coded and transmitted. The block of samples to be predicted, a macroblock partition or sub-macroblock partition, can range in size from a complete macroblock, i.e. 16×16 luma samples and corresponding chroma samples, down to a 4×4 block of luma samples and corresponding chroma samples.
帧间预测是从已经被编码和传输的以前的图片(参考图片)中预测亮度、色度块的过程。这其中包括选择预测区域、生成预测块、从原始块中抽取生成残差和编码传输这几个环节。用于预测的采样块(macroblock partition or sub-macroblock partition)的大小,从一个完整的macroblock(16x16)到4x4的大小不等。
The reference picture is chosen from a list of previously coded pictures, stored in a Decoded Picture Buffer, which may include pictures before and after the current picture in display order (Chapter 5). The offset between the position of the current partition and the prediction region in the reference picture is a motion vector. The motion vector may point to integer, half- or quarter-sample positions in the luma component of the reference picture. Half- or quarter-sample positions are generated by interpolating the samples of the reference picture. Each motion vector is differentially coded from the motion vectors of neighbouring blocks
参考图片从存放于DPB的以前被编码的图片列表中选择,该图片从显示顺序上可以来自当前图片前,也可以来自当前图片后。当前partition与参考图片中预测区域的offset叫做运动向量。运动向量可以以整数像素、半像素或者四分之一像素为单位。半像素和四分之一像素为单位的移动向量,通过对参考图片进行插值来获得。当前blocks与邻居blocks的运动向量取差值,然后被编码传输。
The prediction block may be generated from a single prediction region in a reference picture, for a P or B macroblock, or from two prediction regions in reference pictures, for a B macroblock [i]. Optionally, the prediction block may be weighted according to the temporal distance between the current and reference picture(s), known as weighted prediction. In a B macroblock, a block may be predicted in direct mode, in which case no residual samples or motion vectors are sent and the decoder infers the motion vector from previously received vectors.
预测block可以基于单一的参考图像的预测region来生成,比如P或B macroblock,也可以基于参考图像里的两个预测region来生成,比如B macroblock。可选的,预测block可以根据当前图片和参考图片的时域距离进行加权预测。在B macroblock,可以采用direct mode来预测,这样没有任何的残差和运动向量需要传输,解码器根据之前接收到的运动向量进行预测。
To summarize the process of coding an inter-predicted macroblock (note that the steps need not occur in this exact order):
帧间预测编码步骤总结如下:
1. Interpolate the picture(s) in the Decoded Picture Buffer to generate 1/4-sample positions in the luma component and 1/8-sample positions in the chroma components. (section6.4.2).
对DPB下的图片进行插值处理,以生成亮度1/4像素(色度1/8像素)为单位的图像。
2. Choose an inter prediction mode from the following options:
选择帧内预测的模式:
(a) Choice of reference picture(s), previously-coded pictures available as sources for prediction. (section 6.4.1).
从已编码的图像中选择用于参考的图像
(b) Choice of macroblock partitions and sub-macroblock partitions, i.e. prediction block sizes. (section 6.4.3).
从参考图像中选择macroblock partions和sub-macroblock partitions
(b) Choice of prediction types:
选择预测类型:
(i) prediction from one reference picture in list 0 for P or B macroblocks or list 1 for B macroblocks only (section 6.4.5.1).
从list0中的一个参考图像进行预测(P或B| macroblocks),还是从list1中的参考图像进行预测(B macroblocks only)。
(ii) bi-prediction from two reference pictures, one in list 0 and one in list 1, B macroblocks only, optionally using weighted prediction (section 6.4.5.2).
分别从list0和list1中的参考图像进行双向预测,可选择的使用加权预测,B macroblocks only。
3. Choose motion vector(s) for each macroblock partition or sub-macroblock partition, one or two vectors depending on whether one or two reference pictures are used.
为每一个macroblock partition or sub-macroblock partition选择移动向量(有多少给参考图片,就有多少个运动向量)
4. Predict the motion vector(s) from previously-transmitted vector(s) and generate motion vector difference(s). Optionally, use Direct Mode prediction, B macroblocks only. (section 6.4.4).
从相邻的已编码传输的运动向量进行预测,计算向量差。可选的,B macroblocks可以使用Direct Mode预测。
5. Code the macroblock type, choice of prediction reference(s), motion vector difference(s) and residual. (Chapters 5 and 7).
把macroblock类型,选择的参考帧,运动向量差和残差进行编码。
6. Apply a deblocking filter prior to storing the reconstructed picture as a prediction reference for further coded pictures. (section 6.5).
进行环路滤波,并保存起来作为以后图片的预测参考用。
1.1 Macroblock partitions
Each 16×16 P or B macroblock may be predicted using a range of block sizes. The macroblock is split into one, two or fourmacroblock partitions:
用于预测的macroblock可以分成多种block size:
(a) one 16×16 macroblock partition (covering the whole MB),
(b) two 8×16 partitions,
(c) two 16×8 partitions or
(d) four 8×8 partitions.
If 8×8 partition size is chosen, then each 8×8 block of luma samples and associated chroma samples, a sub-macroblock, is split into one, two or four sub-macroblock partitions):
8x8的macroblock,又可以细分为多种sub-macroblock partition
one 8×8, two 4×8, two 8×4 or four 4×4 sub-MB partitions (Figure 6.29).
Each macroblock partition and sub-macroblock partition has one or two motion vectors(x, y), each pointing to an area of the same size in a reference frame that is used to predict the current partition. A partition in a P macroblock has one reference frame and one motion vector; a partition in a B macroblock has one or two reference frames and one or two corresponding motion vectors. Each macroblock partition may be predicted from different reference frame(s).
当前图像macroblock partition和sub-macroblock partition拥有一个或两个运动向量(x,y),分别指向参考图像同样大小的macroblock partition,P macroblock里面的partition拥有一个参考帧和对应的一个运动向量;B macroblock里面的partition拥有一个或两个参考帧和对应的一个或两个运动向量。每一个macroblock partition可以从不同的参考帧进行预测。
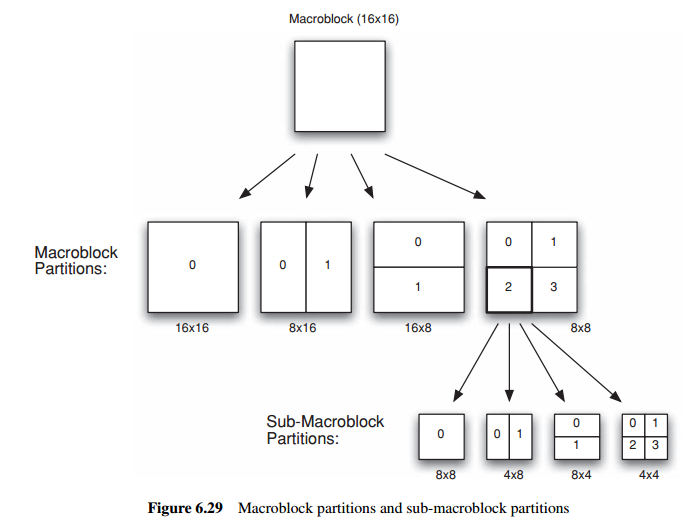
However, the sub-macroblock partitions within an 8×8 sub-macroblock share the same
reference frame(s)
1.2 Motion vector prediction
Encoding a motion vector for each partition can cost a significant number of bits, especially if small partition sizes are chosen. Motion vectors for neighbouring partitions are often highly correlated and so each motion vector is predicted from vectors of nearby, previously coded partitions. A predicted vector, MVp, is formed based on previously calculated motion vectors and MVD, the difference between the current vector and the predicted vector, is encoded and transmitted. 运动向量可以从邻近的已编码的partition预测得到的(MVp),然后计算当前实际运动向量与预测运动向量的差值(MVD)用于编码传输。
Let E be the current macroblock, macroblock partition or sub-macroblock partition, let A be the partition or sub-macroblock partition immediately to the left of E, let B be the partition or sub-macroblock partition immediately above E and let C be the partition or sub-macroblock partition above and to the right of E.
用于预测的邻近macroblock partition或sub-macroblock partition,基于以下原则进行选择:
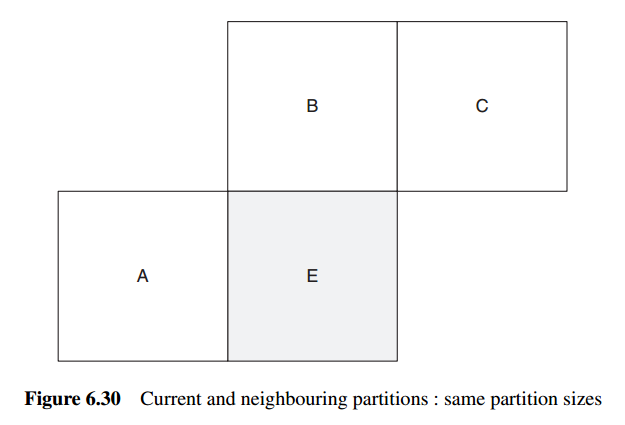
If there is more than one partition immediately to the left of E, the topmost of these partitions is chosen as A. If there is more than one partition immediately above E, the leftmost of these is chosen as B.
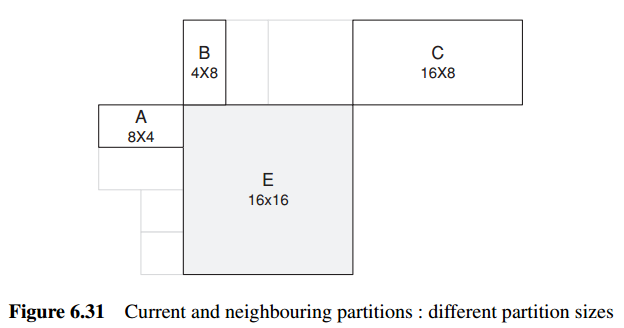
预测运行向量(MVP)的计算,遵循以下原则:
1. For transmitted partitions excluding 16×8 and 8×16 partition sizes, MVp is the median of the motion vectors for partitions A, B and C.
2. For 16×8 partitions, MVp for the upper 16×8 partition is predicted from B and MVp for the lower 16×8 partition is predicted from A.
3. For 8×16 partitions, MVp for the left 8×16 partition is predicted from A and MVp for the right 8×16 partition is predicted from C.
4. For skipped macroblocks, a 16×16 vector MVp is generated as in case (1) above, as if the block were encoded in 16×16 Inter mode.
If one or more of the previously transmitted blocks shown in the figure is not available, e.g. if it is outside the current picture or slice, the choice of MVp is modified accordingly. At the decoder, the predicted vector MVp is formed in the same way and added to the decoded vector difference MVD. In the case of a skipped macroblock, there is no decoded vector and a motion-compensated macroblock is produced using MVp as the motion vector.
如果某些预测用的macroblock partition不存在(当前macroblock partition处于边缘位置),则根据具体情况来调整。
在解码端,MVp按照同样的方法来生成,然后加上码流中传输的MVD,还原当前时间的运动向量。对应SKIP macroblock,码流中不传输MVD,直接拿MVp作为当前的运动向量。
1.2.1 Bipredicted macroblock motion vector prediction
A bipredicted macroblock in a B slice has two motion vectors.
B slice的双向预测macroblock有两个运动向量,这里要区分两种情况:
1、If one reference frame is a past
frame and the other is a future frame, each of the two vectors is predicted from neighbouring motion vectors that have the same temporal direction, i.e. a vector for the current macroblock pointing to a past frame is predicted from other neighbouring vectors that also point to past frames.
如果其中一个参考帧在过去,另一个在未来,那么这两个运动向量分别从邻近macroblock的运行向量预测得来。注意邻近的macroblock要具有一致的时域方向。
2、If both reference frames are past frames, relative to the current frame, or both are future frames, then one of the vectors is encoded as ascaled motion vector. The vector pointing to the list 0 reference (MV0) is encoded as described above and a motion vector is calculated by scaling MV0 based on the temporal distances between the current frame, the list 0 frame and the list 1 frame. The list 1 vector (MV1) is then encoded differentially from the scaled motion vector.
如果两个运动向量相对于当前macroblock都是来自过去或者未来,那么指向list0的运动向量会被编码传输(MV0),然后指向list0的运动向量会对比list1与当前帧时域的关系进行scale(smv),然后算出MV1和MV0的差值,再进行编码传输(解码端可以通过该差值和MV0来还原MV1)。
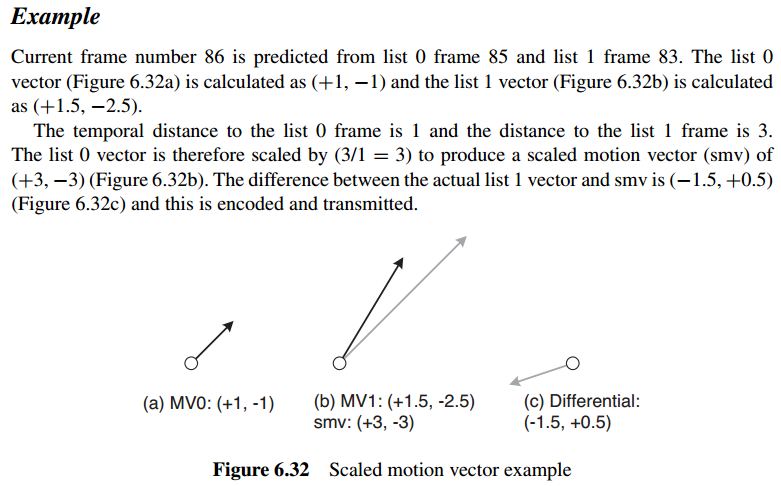
注:
隔得远,理论上运动向量大。固要把MV0按比例放大/缩写,这样MV0和MV1之间的差值才会小,利于压缩传输。
1.2.2 Direct mode motion vector prediction
No motion vector is transmitted for a B slice macroblock or partition encoded in direct mode. Instead, the decoder calculates list 0 and list 1 vectors based on previously coded vectors and uses these to carry out bipredicted motion compensation of the decoded residual samples
当B slice macroblock or partion采用direct mode进行编码时,不传输运动向量,解码器通过计算之前编码好的list0和list1的运动向量,获取当前macroblock or partion list0和list1的运动向量。
A flag in the slice header indicates whether a spatial or temporal method shall be used to calculate the vectors for direct mode macroblocks or partitions.
Slice header下的一个标志位用于区别采用空间或时域的方式计算direct mode macroblocks or partions的运行向量。
1、 In spatial direct mode, list 0 and list 1 vectors of neighbouring previously coded macroblocks or partitions in the same slice are used to calculate the list 0 and list 1 vectors of the current MB or partition.
在spatial mode下,来自同一个slice的list0和list1的运行向量用于计算当前MB or partion的list0和list1的运动向量。
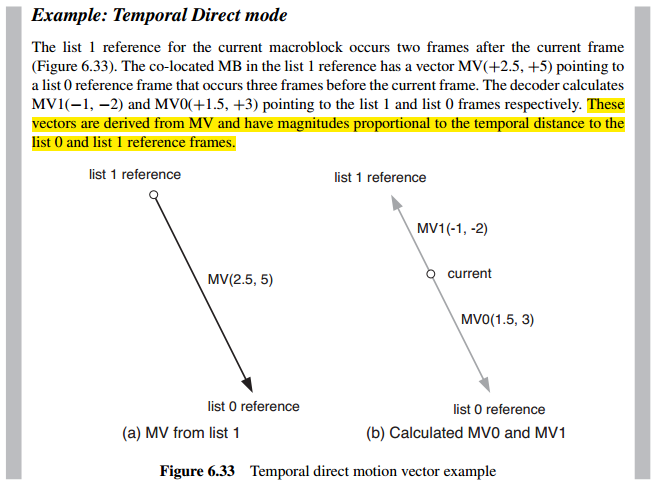
2、In temporal direct mode, the decoder carries out the following steps:
在temporal mode下,解码器采用以下步骤:
1. Find the list 0 reference frame for the co-located MB or partition in the list 1 frame. This list 0 reference becomes the list 0 reference of the current MB or partition.
2. Find the list 0 vector, MV, for the co-located MB or partition in the list 1 frame.
3. Scale vector MV based on the temporal distance between the current and list 1 frames:
this is the new list 1 vector MV1.
4. Scale vector MV based on the temporal distance between the current and list 0 frames:
this is the new list 0 vector MV0.
注:
隔得远,理论上运动向量大。固根据时域距离,按比例计算MV0和MV1。
refer to "the-h-264-advanced-video-compression-standard"
posted on 2015-06-01 17:12
lfc 阅读(726)
评论(0) 编辑 收藏 引用