Win32下的Perl,无用的select,停滞的Tk,结束吧....

Oracle:pl/sql
异常处理(
2
)
pl/sql
提供了强大而灵活的手段来捕捉和处理程序产生的异常,从而使
oracle
的用户远离一些令人烦恼的
bug
。
异常定义
在一个异常产生、被捕获并处理之前,它必须被定义。
Oracle
定义了几千个异常,绝大多数只有错误编号和相关描述,仅仅命名了若干个最常被用到的异常。这些名字被储存在
STANDARD
,
UTL_FILE
,
DBMS_SQL
这几个系统包中,详情请见
oracle:pl/sql
异常处理(
1
)。
出自之外的绝大多数异常需要程序员命名。有
2
种命名异常的方法:
1
:声明一个自定义异常
在
STANDARD
中的命名了的异常基本山是与系统的错误相关的(当然那些只有
errorcode
的异常也是这样),但在实际的应用中我们经常需要与特定的应用程序相关的异常,由程序员声明的异常就是用于处理这种情况的。
Oracle
异常处理模块的方便的地方在于,它并没有区别对待自定义的与预定义的异常。这使得我们可以像对待预定义异常一样,捕捉和处理自定义异常,只是在此之前需要声明它;同时对于一个自定义的异常,我们需要用
RAISE
来手动产生。
下面是一个声明的例子:
procedure calc_ammul_sales
(company_id_in in company.company_id%tye)
is
invalid_company_id exception;
negative_balance excrption;
duplicate_company Boolean;
begin
/*body of executable statement*/
exception
when invalid_company_id
then /*handle exception*/
when no_data_found
then /*handle exception*/
/*…..*/
end;
需要注意的是处理定义的时候,只有两个地方会出现自定义的异常:
ü
raise exception
;
ü
when exception then
2
:为非预定义异常关联一个名字
仅仅
21
个预定义异常对我们来说实在是太少了,还有几千个异常只有
errorcode
和描述。另外,程序员也可以用
RAISE_APPLICATION_ERROR
定义一个含
errorcode
和描述的异常。
当然,只用
errorcode
也可以很好地完成工作,只要你不担心会忘了那串数字代表的意思就行。比方说
;
exception
when others
then
if sqlcode=-1843 then /*sqlcode
是内建的用于返回最近一次错误编号的函数
*/
…..
这的确是一段让人感到晦涩的代码,还是给它关联个名字吧。
我们要用到的是
pragma exception_init(exception,integer)
,然后就可以像对待预定义异常一样对待它了,我是说没必要像上面的那种一样用
raise
。
Exception_init
是一个编译时运行的函数,它只能出现在代码的声明部分,而异常名字必须在此之前被定义。下面用一个匿名过程举个例子:
declare
invalid_company_id exception;
pragma exception_init(invalid_company_id, -1834);
要注意的时:
ü
不可以用
-1403
(
no_data_found
),用
100
,事实上
exception_init
中的
integer
对应的是
sqlcode
返回的值。
ü
不能为
0
,不能大于
100
,不能小于
-1000000
一个例子:
procedure delete_company(company_id_in in number)
is
still_have_emplyee exception;
pragma exception(still_have_employee, -2293);
begin
delete from compamy
where company_id=company_id_in;
exception
when still_have_employee
then dbms_output.put_line(‘delete employees for company first’);
end;
在一下两种情况下,我们有必要使用
exception_init
:
ü
一个非预定义异常是经常要被用到的。
ü
我们将用
raise_applocation_error
产生了一个自定义的
errorcode
时。
一种简便的方法是将以上两种情况中的异常定义在一个包中,这样我们就没有必要每次都重复定义了。
Create or replace package dynsql
Is
Invalid_table_name exception;
Pragma exception_init(invalid_table_name, -903);
Invalid_column_name exception;
Pragma exception_init(invalid_column_name, -904);
En_too_young const number:=-200001;
Exc_too_young exception;
Pragma exception_init(exc_too_young, -20001);
End;
有了上面这个包,就可以方便的处理异常了
;
procedure validate_emp(birthdate in date)
is
min_tear const pls_integer:=18;
begin
if add_month(sysdate,min_year*12*-1)<birthdate_in
then
raise_application_error(dynsql.en_too_young, ‘employee must be’ || min_year ||‘old’);
end if;
end;
除了
standard
包中的
21
个预定义异常外,还有一些包也定义了一些异常。但与
standard
包中异常不同的是,在使用这些异常时,需要带上包的名字。如:
when dbms_lob.invalid_argval then ……
非常有用的一点是,可以在最外层的
pl/sql
块的异常处理模块中加入
others
,这样就可以把从内部传递出来的未被处理的剩余异常全部处理掉了。
Exception
When others
Then ….
Oracle:pl/sql
异常处理(
1
)
pl/sql
提供了强大而灵活的手段来捕捉和处理程序产生的异常,从而使
oracle
的用户远离一些令人烦恼的
bug
。
pl/sql
异常处理的概念和术语
在
oracle
中所有的错误都被认为是不应该发生的异常。一个异常可能是以下
3
种情况的一种:
u
由系统产生的错误(“
out of memory
”或“
duplicate value in index
”)
u
用户行为导致的错误
u
应用程序给用户的一个警告
pl/sql
用一种异常句柄的结构来捕捉和响应错误。正是有了异常句柄的存在,我们能很方便的分离异常处理代码与可执行代码。与线性的代码相比,为了处理异常,异常句柄提供了一种类似事件驱动的模式;换句话说,就是不管一种特定的错误在何时何地发生,它都将被同一个代码处理。
当一个错误出现后,无论它是系统还是程序产生的,都将导致一个异常。之后,可执行程序被中断,控制权转移给异常处理代码。处理完异常后,程序将不会回到先前被中断的位置,相反的,控制权被交给了当前程序的外围模块(可能是程序,也可能是系统)。
procedure jimmy
is
new_value varchar(35)
begin
|--------new_value:=old_value || ‘-new’;
| if new_value like ‘like%’
| then
| …..
| end if;
| exception
|-----
à
when value_error
then
…..
end;
因为
old_value
是一个未被定义的变量,所以将产生一个错误,并将给异常处理模块处理。
从异常的可应用范围出发,可将异常分为两类:
系统异常:
由
oracle
定义并由
pl/sql runtime
引擎在检测到错误时产生的异常。一些系统异常有名字,比如
NO_DATA_FOUND
,然而大多数的异常仅仅只有数字编号和描述。这些异常无论在哪个
pl/sql
中程序都能被应用。
共有
21
个命名的系统异常:
|
命名的系统异常
|
产生原因
|
|
ACCESS_INTO_NULL
|
未定义对象
|
|
CASE_NOT_FOUND
|
CASE
中若未包含相应的
WHEN
,并且没有设置
ELSE
时
|
|
COLLECTION_IS_NULL
|
集合元素未初始化
|
|
CURSER_ALREADY_OPEN
|
游标已经打开
|
|
DUP_VAL_ON_INDEX
|
唯一索引对应的列上有重复的值
|
|
INVALID_CURSOR
|
在不合法的游标上进行操作
|
|
INVALID_NUMBER
|
内嵌的
sql
语句不能将字符转换为数字
|
|
NO_DATA_FOUND
|
使用
select into
未返回行,或应用索引表未初始化的元素时
|
|
TOO_MANY_ROWS
|
执行
select iotn
时,返回超过一行
|
|
ZERO_DIVIDE
|
除数为
0
|
|
SUBSCRIPT_BEYOND_COUNT
|
元素下标超过嵌套表或
VARRAY
的最大值
|
|
SUBSCRIPT_OUTSIDE_LIMIT
|
使用嵌套表或
VARRAY
时,将下标指定为负数
|
|
VALUE_ERROR
|
赋值时,变量长度不足以容纳实际数据
|
|
LOGIN_DENIED
|
Pl/sql
应用程序连接到
oracle
数据库时,提供了不正确的用户名或密码
|
|
NOT_LOGGED_ON
|
Pl/sql
应用程序在没有连接
oralce
数据库的情况下访问数据
|
|
PROGRAM_ERROR
|
Pl/sql
内部问题,可能需要重装数据字典&
pl./sql
系统包
|
|
ROWTYPE_MISMATCH
|
宿主游标变量与
pl/sql
游标变量的返回类型不兼容
|
|
SELF_IS_NULL
|
使用对象类型时,在
null
对象上调用对象方法
|
|
STORAGE_ERROR
|
运行
pl/sql
时,超出内存空间
|
|
SYS_INVALID_ID
|
无效的
ROWID
字符串
|
|
TIMEOUT_ON_RESOURCE
|
Oracle
在等待资源时超时
|
由程序员定义的异常:
程序员在程序中定义的异常,它只是在特定的程序种有效。可以使用
EXCEPTION_INT
这个
pragma
将一个无名字的系统异常与一个程序员定义的名字相关联。或者用
RAISE_APPLICATION_ERROE
来自己定义一个异常的数字编号和描述。
按异常生成方式可分为:
预定义异常:
就是上面表中的
21
种有名字的系统异常。
非预定义异常:
没名字的系统异常,可以用
pragma exception_int
给它关联一个名字。
自定义异常:
需要用
RAISE
或
RAISE_APPLICATION_ERROR
生成的异常。
下面是一些要用到的属于
;
Exception section
(异常处理模块)
它是
pl/sql
语句块种包含一个或多个异常句柄的部分。
Exception section
的结构基本上与
case
相似。
Raise
(产生)
通过通知
pl/sql runtime
引擎有错误来中止当前程序的运行。也可通过显式的请求,如:
RAISE
或
RAISE_APPLICATION_ERROR
来
RAISE
一个异常。
Handle
(句柄,某一个异常处理的代码)
在
exception section
中捕捉错误。可以在
handle
中编写程序来处理异常,比如将错误记入
log
中,显示一个错误信息,将异常传出当前程序快。
Scope
(作用范围
)
一个异常从产生、被捕捉到处理整个过程所处的程序部分。
Propagation
(传递)
如果一个异常没有被处理,那么它将被传递到但前块的上一级,它有可能是另一个代码快,也可能是系统。
Unhandled exception
(未被处理的异常)
如果一个异常没有被处理,并一直被传递道理系统中,那么它被称为
unhandled exception
。
Un-named or anonymous excepttion
(匿名异常)
(在异常类型中有介绍)
Named exception
(命名异常)
包括系统异常中有名字的那部分和用户定义的名字。
(网上有很多荒谬的中文介绍,可以去google看看。)
在pl/sql中,trunc函数返回由指定测量单位截取的时间值。
trunc函数的语法如下:
trunc(date, [format])
date就是要被截取的时间值。
format是用于截取的测量单位。如果省略的话date将被截取到day的精度。
format参数表:
unit valid format parameters
Year SYYY,YYYY,YEAR,SYEAR,YYY,YY,Y
ISO YEAR IYYY,IY,I
Quarter Q
Month MONTH,MON,MM,RM
Week WW
IW IW
W W
Day DDD,DD,J
Start day of week DAY,DY,D
Hour HH,HH12,HH24
Minute MI
例子:
trunc(to_date("22-AUG-03"), "YEAR") 返回‘01-JAN-03’
trunc(to_date("22-AUG-03"), "Q") 返回‘01-JUL-03’
trunc(to_date("22-AUG-03"), "MONTH") 返回‘01-AUG-03’
trunc(to_date("22-AUG-03"), "DDD") 返回‘22-AUG-03’
trunc(to_date("22-AUG-03"), "DAY") 返回‘17-AUG-03’
详情请见
http://www.techonthenet.com/oracle/index.php
听说有人用eclips在写perl,好像不错的样子。于是去
http://www.eclipse.org上下了个28M的platform版的(先要装perl的,我的是5.6.1)。按照
http://e-p-i-c.sourceforge.net/里的说明文档,单击help=>点击software updates=>点击find and install=>选择search new feature to install=>单击new remote site=>name中填写Epic,URL中填写
http://e-p-i-c.sourceforge.net/updates/=>然后一路NEXT,搞定。很漂亮的开发环境,不过没看出方便来,反而感到麻烦,基本属于华而不实。
浅谈
typeglob
本文是对《
advanced perl programming
》
edition 2
中有关
typeglob
的叙述,但不是一字一句的直译,又不能讲就是意译,因为加了一点个人浮浅的理解,所以叫浅谈。
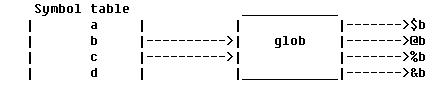
符号表
当程序使用一个全局变量时,
perl
解析器会在一个符号表中查找这个变量名。可以这么认为:符号表完成了变量的名字到实际存储区域的映射。
Symbol table
| A | --------
à
| 3 |
| B |---------
à
| 2 |
| C |
| D |
图
1
请注意,是变量的名称而不是变量,这一点很特别,可以说符号表中
a
映射了一个到
$a
的内存区域,实际的情况更复杂。
perl
中有几种基本数据结构:
$a
,
@a
,
%a
,
&a
和文件或目录句柄
a
,它们都有同样的变量名称只是前缀不一样,于是就有了
glob
的概念。

图2
正如上图所示符号表把
b
映射一个
glob
。对
glob
的描述大概可以这么讲:它是包含了各个名为
b
的变量的引用的
hash
结构,它叫做
*b
。
*b{SCALAR}=\$b;
*b{HASH}=\%b;
*b{ARRAY}=\@b;
…….
够诡异的了!
别名
很明显
glob
把名称与引用无情地分开了,好处大概就是可以很方便地取别名。简单地把
*b
赋值给
*c
,就是
*c=*b
,产生地结果就是这样:
图
3
两个名称指向了同一个
glob
,现在这个
glob
既叫
*b
又叫
*c
。
现在应该有些思路了,举个例子说:
%c
地解析过程可以这么认为,
perl
先在符号表中找到
c
所映射的
glob
,然后在
glob
中找到前缀为
%
的引用,最后返回存储位置。最常见体现这个思想的代码如下。
package Some::Module;
use base ‘Exporter’;
our @EXPORT=qw(useful);
sub useful{42;}
Exporter
的作用就是将
useful
从包中传出到调用者那里。基本的工作原理如下。
package Some::Module;
sub useful{42;}
sub import{
no strict ‘refs’;
*{call().”::useful”} = *useful;
}
import
子程序在包被
use
时将自动被调用。在调用者代码中的
useful
子程序最终将被指向
Some::Module::useful
。
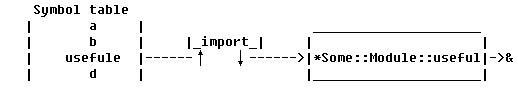
图
4
之所以要用
no strict ‘ref’;
是因为如果调用者的代码中使用了
use strict
的话,将产生错误。把上面的代码再简单点比喻一下就是:
$answer =42;
$variable = “answer”;
print ${$variable};
一个道理。
分解
glob
在上面的这个例子中,我们将
useful
的名称映射到了
Some::Module::useful
的
glob
(或者说为
Some::Module::useful
的
glob
取了个别名),这会带来一些影响。比如说:
use Some::module;
our $useful=”Some handy string”;
print $Some::Modile::useful;
因为
useful
和
Some::Modile::useful
映射同一个
glob
的关系,输出的结果是
”Some handy string”
。但实际的情况是,我们只希望
useful
指向子程序
Some::Modile::useful
,而不是整个
glob
。
Perl
提供了映射部分引用的办法。如果是希望仅仅映射标量或数组的话,可以这样:
${caller( )."::useful"} = $useful;
@{caller( )."::useful"} = @useful;
但是对于子程序,如果也这么做:
&{caller( )."::useful"} = &useful;
首先
perl
会运行
&usefule
得到
42
,然后将
42
赋值给运行
&{caller( )."::useful"}
所产生的结果,但
&{caller( )."::useful"}
根本是不存在的,于是错误产生了。为了解决这个问题,
glob
这个诡异的机构提供了一个重载过的“
=
”方法。像
*b=\@c
的操作可以给
*b
添加一个到
@c
的引用。
@b
和
@c
任何一方的变化都将反映对方上。
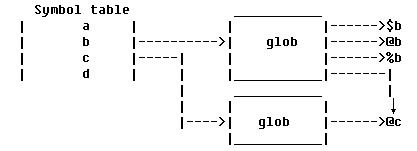
图
5
*b
中除了又一个引用指向
@c
外,其他的引用都没有变化。正是有了“
=
”这个方法,我们可以随心所欲在
glob
中指定引用。
*a = \"Hello";
*a = [ 1, 2, 3 ];
*a = { red => "rouge", blue => "bleu" };
print $a; # Hello
print $a[1]; # 2
print $a{"red"}; # rouge
后一个对
*a
的赋值并没有替换前面的赋值,只是加入了个不同类型的引用。有一个不得不讲的例外,如果
*a
被加入了一个到常量的引用,那么该变量的值将是不能改变的。
*a=\1234;
$a=10;
这么做是徒劳的,
perl
将返回“
modification of a ready-only value attempt
”的错误信息。
现在可以着手解决本节开始时遇到的那个问题了:
sub useful{42}
sub import{
no strict ‘refs’;
*{caller().”::userful”} = \&useful;
}
这已经跟
Exporter
的实际工作原理很接近了。
Exporter
核心代码的分析
my $pkg = shift;
my $callpkg = caller($ExportLevel);
#
$ExportLevel = 0
foreach $sym(@imports){
(*{${callpkg}::$sym}) = \&{“${pkg}::$sym”}, next)
unless $sym =~ s/^(\W)//;
$style = $1;
*{${callpkg}::$sym}) =
$style eq ‘&’ ? \&{“${pkg}::$sym”} :
$style eq ‘$’ ? \${“${pkg}::$sym”} :
$style eq ‘@’ ? \@{“${pkg}::$sym”} :
$style eq ‘%’ ? \%{“${pkg}::$sym”} :
$style eq ‘*’ ? *{“${pkg}::$sym”} :
do {require Carp; Carp::croak(Can’t export symbol:$sym)};
}
我们通过
@Export
数组传入需要输出的变量。如果变量不带前缀,那么直接在最顶层调用名称的
glob
中加入被引用模块相应子程序的引用。如果有前缀,那么将前缀去掉。
(*{${callpkg}::$sym}) = \&{“${pkg}::$sym”}, next)
unless $sym =~ s/^(\W)//;
去掉的前缀将被赋值给
$style
,然后检验
$style
的类型,并具此返回相应类型的引用。
$style = $1;
*{${callpkg}::$sym}) =
$style eq ‘&’ ? \&{“${pkg}::$sym”} :
$style eq ‘$’ ? \${“${pkg}::$sym”} :
$style eq ‘@’ ? \@{“${pkg}::$sym”} :
$style eq ‘%’ ? \%{“${pkg}::$sym”} :
$style eq ‘*’ ? *{“${pkg}::$sym”} :
do {require Carp; Carp::croak(Can’t export symbol:$sym)};
如果传入的值与以上各种情况都不匹配,那么就调用
croak
中止顶层程序。
使用
glob
建立子程序
给
glob
分配一个到匿名子程序的引用是别名技术在高级
perl
编程中的一个普遍应用。举个例子:有一个叫
Data::BT::PhoneBill
的模块,它被用于在英国电信公司的电话帐单服务中检索数据。这个模块将一个电话中的信息按照逗号分开,并将它们对象化。
package Data::BT::PhoneBill::_Call;
sub new{
my ($Class,@data) = @_;
bless \@data, $Class;
}
sub installation {shift->[0]}
sub line {shift->[1]}
…..
这样做的结果是不大好维护。如果我们打算在在数据的开头处添加一个新的条目,那么就需要修改大半块代码,将数组编号集体下移。为了避免这种情况的发生,应用
hash
来替换不方便的
array
。
our @field = qw(type installation line chargecard _data time destination _number duration _rebat cost);
sub new{
my ($class @data) = @_;
bless {map {$field[$_] => $data[$_]} 0..$#field => $class;}
}
sub type {shift->{type}}
sub installation {shift->{installation}}
….
只需要在代码中加入重复的
3
个词,我们就可以为模块添加一个新的条目。这比上面那个方便不少,但是如果待加入的条目名称是这样的:
friend_and_family_duscount
,那么重复
3
遍的工作也够麻烦的了。于是就要用到
glob
。
Foreach my $f(@field){
no strict ‘refs’;
*f = sub { shift->{$f}};
}
#SERVER
use strict;
my $port=$ARGV[0];
my $file=$ARGV[1];
my $PF_INET=2;
my $SOCK_STREAM=1;
my $local_addr=pack('SnC4x8',$PF_INET,$port,192,168,138,105);
socket(FILE_TRANS_SERV,$PF_INET,$SOCK_STREAM,getprotobyname('tcp')) or die("socket failed for $!");
bind(FILE_TRANS_SERV,$local_addr) or die("bind failed for $!");
listen(FILE_TRANS_SERV,3);
open(FILE,$file) or die("open failed for $!");
binmode(FILE);
seek(FILE,0,0);
for(;my $remote_addr=accept(FILE_TRANS_CLIENT,FILE_TRANS_SERV);close(FILE_TRANS_CLIENT)){
while(!eof(FILE)){
read(FILE,my $buffer,100);
send(FILE_TRANS_CLIENT,$buffer,0);
}#while
}#for
close(FILE_TRANS_SERV);
close(FILE);
1;
#CLIENT
use strict;
my $port=$ARGV[0];
my $file=$ARGV[1];
my $PF_INET=2;
my $SOCK_STREAM=1;
my $remote_addr=pack('SnC4x8',$PF_INET,$port,192,168,138,105);
socket(FILE_TRANS_CLIENT,$PF_INET,$SOCK_STREAM,getprotobyname('tcp')) or die("socket failed for $!");
open(SFILE,">$file") or die("file creation failed for $!");
binmode(SFILE);
connect(FILE_TRANS_CLIENT,$remote_addr) or die("connection failed for $!");
while(<FILE_TRANS_CLIENT>){
print SFILE $_;
}
close(FILE_TRANS_CLIENT);
close(SFILE);
1;
my用得有点乱,还好运行一些正常。
在网上没找不到这个主题的perl代码,所以自己写了个。
至于为什么用在while里用read(FILE,my $buffer,100),是怕如果一次全读入并传过去,内存会受不了。
2006年3月31日上午8点起,陆续有人通知上不了网,一一解决。
中午12点10分,新闻部的采编系统瘫痪,大约有20台电脑无法进入采编系统,也无法上网。经检查,无法ping通网关。于是停用网卡,又重新启用,无效。更改ip地址,恢复正常。后发现重新启动也可回复正常。由此推断,问题可能出在交换机上,于是将连接新闻部的一个接入层交换机华为2403重启,为保险起见也重启了核心交换机华为3526E。20台电脑均恢复正常。
以为就此一切恢复,但事情并未向想象的方向发展。20分钟后,故障重新出现,并在1小时之内扩展到了整个大楼和另外一幢大楼的某些楼层,大约波及150台左右电脑。
既然问题的原因并非交换机,于是将对象锁定于isa2004防火墙上。首先立即扫描计算机清楚病毒,但未发现一个病毒。重启防火墙,仍然没用。查看防火墙日志,发现一个非法ip的欺骗攻击,还有一些外网的全端口扫描,没放在心上。
由此开始,陷入迷茫中。4点左右,经过冷静分析,发现一个重要线索,所有问题计算机都处于同一网段中。回想isa2004中的记录,很明显,该网段有电脑在不断抢占ip地址,产生大量ip冲突,导致网络瘫痪。
于是立即针对平时出问题较多的几台电脑,进行杀毒。5点下班,网络回复正常,这更坚定了我的判断,因为下班后那台罪魁祸首定是被关闭了,ip冲突结束。但找不到那台电脑,问题依然存在。
周末休息,看来只有等到星期一了。
周六晚在网上请教了几个朋友,众说纷纭。后来有一人的说,可以查看一下交换机日志.....于是按照所讲方法查看交换机。令人感到无比高兴的是,日志里显示了无数的collision,经分析断定问题出在e0/2中一台mac地址是00e04c4596c1的电脑上。查看arp,发现该mac地址相关的ip地址一直在不断地变换。问题根源找到,可以安心睡觉了。
周一上午一上班,立即排查e0/2口的病毒网段电脑的mac地址,很快确定了是一台广告部的电脑。将其断线。现在网络恢复正常。
利用批处理文件和
vbs
脚本实现网站视频自动录制
关键字:
helix
,
vbs
脚本,批处理,压码参数文件
现在电视台基本上都有了自己的门户网站,我们可以充分利用网络的优势来扩大本地电视台的影响。事实上,将本地电视台的每日的王牌节目挂在网站上的做法已经成为建立电视台网站的必要组成步骤之一了。但随之而来的问题是:每天定时需要的手工录制过程,将给管理者带来极大的不便。在
windows
定时任务的基础上,将批处理程序与脚本程序有机的集合,就可以有效地解决这一问题。
1
:建立压码任务
我们将使用一台带有视频采集卡的电脑来完成压码过程。虽然压码不是本文的重点,但还是有必要交代一下。主要就是使用
helix producer plus9
建立一个压码参数文件,事实上它只是一个带有
rpjf
后缀的
xml
文件(图
1
)。需要注意的是,音频输入选项有线路输入与
microphone
输入两种,这需要与实际的接入线路相吻合;另外,不必选择
2 pass vedio encoding
选项,选择它除了显示一个
warning
外不会有任何效果;再者,因为现阶段绝大多数的网络接入模式为拨号和
dsl
,所以只需要生成
56k
和
384k
码率的视频文件;最后,录制完成的视频文件,其名称最好用日期来标识,比如:
20060301.rm
。
<?xml version="1.0" encoding="UTF-8"?>
<job xmlns="http://ns.real.com/tools/job.1.0.1">
<enableTwoPass type="bool">false</enableTwoPass>
<clipInfo>
<entry>
<name>Author</name>
<value type="string">ZSTV</value>
</entry>
<entry>
<name>Copyright</name>
<value type="string">(c) ZSTV2006 </value>
</entry>
<entry>
<name>Keywords</name>
<value type="string">ZSNews[2006-03-21]</value>
</entry>
<entry>
<name>Title</name>
<value type="string">ZSNews[2006-03-21]</value>
</entry>
</clipInfo>
<input>
<captureInput>
<audioDeviceID type="string">Intel(r) Integrated Audio</audioDeviceID>
....................................
我们可以建立一个名为
shixian.bat
的批处理文件来的调用上面所示的参数文件,内部具体如下:
producer -j "d:\shixian\shixian.rpjf" -daw -lc "e,i"
默认的录制过程会实时监控音频变化,并将它记录到一个叫
producer.log
的文件之中,但是产生的
wanging
记录很多,很快就使
log
文件变得巨大而且可能引起录制过程的意外中断,所以我们可以使用
-daw
参数关闭音频监视,再用
lc “e,i”
指明只记录错误和信息。这样做之后,录制过程就比较稳定了。
只要在计划中添加每日执行
shixian.bat
文件的任务,我们就会每天得到一个相同文件属性和名称的
rm
文件。在这里将每天产生一个带有
2006-03-21
属性的、名为
20060321.rm
文件。听起来很拗口,更糟糕的是这并没有减轻管理者的工作,因为他不得不每天打开服务器为其改名称。而且即便有幸雇佣了一名勤奋的管理员(他不介意每天做这样重复的事情),但他还是没办法更改文件中显示日期的属性,在这录制过程中已经决定了。除非
…….
2
:建立修改压码参数文件的任务
原理很简单:每天更新压码参数文件中与日期相关的
xml
字段。在这个例子里是文件显示日期的属性和文件名。
下面就是用于更新日期字段的脚本代码:
dim regOR
set regOR=new regexp ‘
建立一个正则表达式对象
regOR.ignorecase=True ‘
忽略大小写
regOR.global=True ‘
搜索应用于整个字符串
regOR.pattern="^([0-9]{1})$" ‘
建立搜索模式为单数字表达式
dim mytime
mytime=date ‘
用
date
函数达到系统日期,并赋值给
mydate
yy=year(mytime) ‘
提取系统日期中的年份
mm=month(mytime) ‘
提取系统日期中的月份
dd=day(mytime) ‘
提取系统日期中的日期
if regOR.test(mm) then ‘
检测月份是否为单数字(一月到九月)
mm=regOR.replace(mm,"0$1") ‘
如果是,则在月份前添加
0
使其成为两个数字
end if
if regOR.test(dd) then ‘
检测日期是否为单数字(一日到九日)
dd=regOR.replace(dd,"0$1") ‘
如果是,则在日期前添加
0
使其成为两个数字
end if
mytime=yy & "-" & mm & "-" & dd ‘
合并年月日为
”yy-mm-dd”
形式
dest=yy & mm & dd ‘
合并年月日为
”yymmdd”
形式
pattern1="(.*[^0-9])([0-9]{4}\-[0-9]{2}\-[0-9]{2})([^0-9].*)"
‘
设定模式变量
pattern1
为
”%d%d%d %d- %d %d -%d %d”
pattern2="(.*[^0-9])([0-9]{8})([^0-9].*)" ‘
设定模式变量
pattern2
为
8
个连续数字
regOR.pattern=pattern1 ‘
建立搜索模式为
pattern1
dim tempstring
Set fso = CreateObject("Scripting.FileSystemObject") ‘
建立系统文件对象
Set f = fso.CreateTextFile("d:\shixian\temp.txt", True) ‘
新建名为
temp
的文本文件
Set fr = fso.GetFile("d:\shixian\shixian.rpjf") ‘
得到编码参数文件
shixian.rpjf
Set ts = fr.OpenAsTextStream(1,-2) ‘
将参数文件以只读文本形式打开
do until ts.AtEndOfStream ‘
建立循环,直到参数文件读取完毕
tempstring=ts.readline ‘
以行为单位读取参数文件
if regOR.test(tempstring) then ‘
搜索改行参数是否存在日期字段
tempstring=regOR.replace(tempstring,"$1" & mytime & "$3") ‘
如存在,则更新
end if
regOR.pattern=pattern2 ‘
建立搜索模式为
pattern2
if regOR.test(tempstring) then ‘
搜索改行参数是否存在日期字段
tempstring=regOR.replace(tempstring,"$1" & dest & "$3") ‘
如存在,则更新
end if
regOR.pattern=pattern1 ‘
重新建立搜索模式为
pattern1
f.writeline(tempstring) ‘
将更新后的数据写入
temp.txt
文件
loop
ts.close
‘以下是关闭和注销各个对象
f.close
set regOR=nothing
set ts=nothing
set fr=nothing
set f=nothing
set fso=nothing
要说明的是为什么要在单数字的月份和日期前加
0
。打个比方比较容易说明:如果不加
0
,那么对于一个名为
2006111.rm
的文件,它究竟是指
2006
年
1
月
11
日还是
2006
年
11
月
1
日呢?加
0
后变成
20060111.rm
就一目了然了,是前者。
以上这段脚本代码的具体功能是将参数文件中的数据以行为单位导入到一个临时的文本文件中,实时监视与时间相关的
xml
字段并加以更新,最后在生成一个
temp.txt
的文件。之后我们要做的无非就是用一个批处理文件调用脚本,再删除旧的参数文件,最后将
temp.txt
重命名为参数文件。
这就是
update.bat
批处理文件中的代码:
@echo off
d:\shixian\update.vbs
if exist "d:\shixian\shixian.rpjf" del "d:\shixian\shixian.rpjf"
if exist "d:\shixian\temp.txt" rename d:\shixian\temp.txt shixian.rpjf
和第一节中一样,还是要将这个
update.bat
的批处理文件添加到计划与任务中,以便每日定时启动。
3
:建立自动传输任务
为了确保稳定,通常压码服务器与网站服务器是分离的,这就需要我们每日将录制的视频文件传输到网站服务器上。批处理文件中的
ftp
命令可以完美的实现这一功能。
以下就是
transfer.bat
批处理中的代码:
@echo off
ftp -s:media.txt
if exist "d:\shixian\shixian20060321.rm" del d:\shixian\shixian20060321.rm
考虑到
SCSI
硬盘惊人的价格,压码服务器的硬盘空间不必太大,最后一行的作用就是删除压码服务器中的视频文件,以节省空间。
Media.txt
是一个
ftp
参数文件,其中记录了
ftp
登陆服务器的名称、用户名、密码和相关的操作,具体形式如下:
open /
服务器名称或
IP
地址
/
/
用户名
/
/
用户密码
/
put /
要传输的文件名
/
quit
很明显,以上的各段代码中不乏需要更新的日期文字表达式。同样的道理,我们也需要使用一个类似的更新脚本,具体代码就不重复了。
4
:一些改进的意见
1
:使用
media player
也可实现压码的功能。
2
:在更新脚本中,用在声明和注销对象上的代码有好几行,如果使用
perl
可以大为简化。因为是
perl
提供了一系列操作符号来实现正则表达式的功能,而事实上
perl
就是为了处理文本而生的。
open(RPJF,"<c:/code/10161.rpjf") or die("can not open because of $!\n");
open(TEMP,">c:/code/temp.txt") or die("can not open because of $!\n");
($sec,$min,$hour,$mday,$mon,$year,$wday,$yday,$isdst)=localtime();
$mday=sprintf("%.2d",$mday);
$mon=sprintf("%.2d",$mon+1);
$year+=1900;
$timerF="$year"."$mon"."$mday";
$timerS="$year"."-"."$mon"."-"."$mday";
while(<RPJF>){
chomp();
$_=~s/(.*)([0-9]{8})(.*)/$1$timerF$3/;
$_=~s/(.*)([0-9]{4}\-[0-9]{2}\-[0-9]{2})(.*)/$1$timerS$3/;
print TEMP "$_\n";
}
close(RPJF);
close(TEMP);
3
:使用磁盘映射能够更加方便的实现文件的传输,不过需要考虑安全问题。