
2008年6月2日
Memory footprint refers to the amount of main memory that a program uses or references while running.
This includes all sorts of active memory regions like code, static data sections (both initialized and uninitialized), heap, as well as all the stacks, plus memory required to hold any additional data structures, such as symbol tables, constant tables, debugging structures, open files, etc, that the program ever needs while executing and will be loaded at least once during the entire run.
Larger programs have larger memory footprints. Excessive number of utility classes and methods in a programming language design would increase the footprint for API users even if they did not use non-standard plug-ins or applications. Programs themselves often do not contribute the largest portions to their own memory footprints; rather, structures introduced by the run-time environment take up most of the memory. For example, a C++ compiler inserts vtables, type_info objects and many temporary and anonymous objects that are active during a program's execution. In a Java program the memory footprint is predominantly made up of the runtime environment in form of the the Java Virtual Machine (JVM) itself that is loaded indirectly when a Java application launches.
During the 1990s, computer memory became cheaper and programs with larger memory footprints became commonplace. This trend has been mostly due to the widespread use of computer software, from large enterprise-wide applications that consume vast amounts of memory (such as databases), to memory intensive multimedia authoring and editing software. To tackle the ever increasing memory needs, Virtual Memory systems were introduced that divide the available memory into equally-sized portions and loads them from "pages" stored on the hard-disk on an as-and-when required basis.
This approach to support programs with huge-memory-footprints has been quite successful. Most modern operating systems including Microsoft Windows, Apple's Mac OS X, and all versions of Linux and Unix provide Virtual memory systems.
With the proliferation of intelligent consumer electronics or embedded systems low-memory-footprint programs have regained importance once more. Low-memory-footprint programs are of paramount to running applications on embedded platforms where memory is often constrained to within a few MBs – so much so that developers typically sacrifice efficiency (processing speeds) just to make program footprints small enough to fit into the available RAM. So much so that Sun Microsystems has now brought out a version of its Java Virtual Machine (JVM) for these devices; it goes by the name of KVM. The KVM works on platforms where memory is in Kilobytes as opposed to the Megabytes (or even Gigabytes) of memory available on even a regular home PC.
posted @
2008-06-02 11:30 Konami wiki 阅读(428) |
评论 (0) |
编辑 收藏
2008年3月18日
Thread 1: I recorded the time it takes to call the Present method of the Direct3D device I'm using. It takes 15 - 16 ms. Doesn't this method just flip the backbuffer to the front? Why does it take so long?
-Devin
Answer 1.1 ( selected ):Present is a blocking call, and may take quite a while to finish, even when VSync is off.
During regular DX calls, the GPU and CPU are not sync'd. The CPU can issue commands to the GPU before it finishes the previous calls, by pushing them in to a command queue. The GPU then just processes commands in the queue at it's own time.
When you call Present, DX syncs between the CPU and GPU, to make sure the two don't drift apart too far. If the GPU has a lot more work to do than the CPU has, the CPU will be waiting for the GPU to finish before Present returns.
If you'd like, you can call Present with the D3DPRESENT_DONOTWAIT flag (I think it actually goes in the PresentParameters when you set up the device). With that flag set, Present returns immediately. Instead of waiting for the GPU to finish, Present returns a D3DERR_WASSTILLDRAWINGerror, to indicate the GPU hasn't finished it's work yet. This allows you to use these extra cycles for non-critical tasks.
psuedocode:
while (Device->Present(0, 0, 0, 0) == D3DERR_WASSTILLDRAWING)
CountSheep();
Hope this helps.
Answer 1.2 ( selected ):
Quote:
Original post by devronious
while (Device->Present(0, 0, 0, 0) == D3DERR_WASSTILLDRAWING)
CountSheep();
How can this work if present returns void? Also, I only show up to 3 params for that method. |
You need to go via a proper swap-chain interface to get the
Present() function in the form sirob posted it. The default/implicit chain controlled via the device doesn't expose it.
I don't have my docs to hand, but I'm pretty sure you can extract an
IDirect3DSwapChain9 interface from the device and work from there...
btw, be very careful how you're profiling your application - there are a lot of ways to generate completely bogus results

hth
Jack
Thread 2: I'm using DirectX9
In a rendering loop, I believe there must be a blocking function call (Present(), EndScene() or BeginScene() ???)
in order for the CPU to wait for the GPU to finish drawing its frame.
I then wondered how could I achieve maximum parrallelism/concurrency betwwen CPU & GPU.
Intuitively (if we admit that present() is the "blocking" function) my loop would look like this
BeginScene()
DrawIndexedPrimitive()
.
. (all kinds of drawing functions)
.
EndScene()
//While the graphic card/driver is executing all drawing commands, do some CPU intensive tasks
ComputeAI()
ComputePhysics()
....
Present() //Stall the CPU while the GPU has finished drawing (if not yet)
Am I wrong ? right ? and which is the "blocking function" if one exists ?
Answer 2.1 ( selected ):I believe there are two blocking factors. One is that the driver isn't supposed to queue more than 3 frames at a time. Present will block under these circumstances (unless you present on the swap chain itself, in which case you have the opportunity to D3DPRESENT_DONOTWAIT and the call will return immediately with D3DERR_WASSTILLDRAWING).
The other is that you can't render to a back buffer that's queued for display. So in some circumstances DrawPrimitive will block.
And I seem to recall that D3DSWAPEFFECT_COPY will block on Present until the back buffer has been blitted. But I haven't gotten around to testing all this, so don't hold me to it. Grain of salt and all that...

posted @
2008-03-18 23:42 Konami wiki 阅读(688) |
评论 (0) |
编辑 收藏
2008年3月2日
过年了简直时间就不够用,冷落了博客…… 补偿一下,找到一篇关于浮点精度控制的文章,兴趣满大的(但我不知道是哪里找来的,故无法贴出原帖地址,为此向作者说声抱歉)
Precision control
First -- a tiny introduction on IEEE floating point formats. On most chips, IEEE floats come in three flavors: 32-bit, 64-bit, and 80-bit, called "single-", "double-" and "extended-" precision, respectively. The increase in precision from one to the next is better than it appears: 32-bit floats only give you 24 bits of mantissa, while 64-bit ones give you 53 bits. Extended gives you 64 bits. (Unfortunately, you can't use extended precision under Windows NT without special drivers. This is ostensibly for compatibility with other chips.) Other CPUs, like the PowerPC, have even larger formats, like a 128-bit format.
Second -- to dispel a myth. Typing "float" rather than "double" changes the memory representation of your data, but doesn't really change the way the chip uses it. In fact, it guarantees you at least floating point accuracy. Because optimized code keeps data in registers longer, it will sometimes be more precise than debug code, which flushes to the stack often.
Again: typing "float" does not change anything that goes on in the FPU internally. If you don't actively change the chip's precision, you're probably doing double-precision arithmetic while an operand is being processed.
The x86 FPU does have precision control, which will stop calculation after it's computed enough to achieve floating point accuracy. But, you can't change FPU precision from ANSI C.
What runs faster in single precision?
Speedwise, single precision affects exactly two calls:
divides and
sqrts. It won't make trancendentals any faster (sin, acos, log, etc., all run the same no matter what: 100+ cycles.) If your program does lots of single-precision divides and sqrts, then you need to know about this.
Single precision will at least double the speed of divides and sqrts. Divides take 17 cycles and sqrts take about 25 cycles. In double precision, they're at least twice that.
On x86, precision control is adjusted using the assembly call "fldcw". Microsoft has a nice wrapper called _controlfp that's easier to use. If you're using Linux, I recommend getting the Intel Instruction Set Reference and writing the inline assembly. (Send me code so I can post it!)
To set the FPU to single precision:
_controlfp( _PC_24, MCW_PC );
To set it back to default (double) precision:
_controlfp( _CW_DEFAULT, 0xfffff );
I use a C++ class that sets the precision while it's in scope and then drops back to the previous rounding and precision mode as it goes out -- very convenient, so you don't forget to reset the precision, and you can handle error cases properly.
Fast conversions: float to int
Lots of people have been talking about how bad Intel chips are at converting floating point to integer. (Intel, NVIDIA, and hordes of people on Usenet.)
I thought it would be fun to try to do the definitive, complete, version of this discussion. This will get a little winded at the end, but try to hang on -- good stuff ahead.
So, if you ever do this:
inline int Convert(float x)
{
int i = (int) x;
return i;
}
or you call floor() or ceil() or anything like that, you probably shouldn't.
The problem is that there is no dedicated x86 instruction to do an "ANSI C" conversion from floating point to integer. There is an instruction on the chip that does a conversion (fistp), but it respects the chip's current rounding mode (set with fldcw like the precision flags up above.) Of course, the default rounding mode does not clamp to zero.
To implement a "correct" conversion, compiler writers have had to switch the rounding mode, do the conversion with fistp, and switch back. Each switch requires a complete flush of the floating point state, and takes about 25 cycles.
This means that this function, even inlined, takes upwards of 80 (EIGHTY) cycles!
Let me put it this way: this isn't something to scoff at and say, "Machines are getting faster." I've seen quite well-written code get 8 TIMES FASTER after fixing conversion problems. Fix yours! And here's how...
Sree's Real2Int
There are quite a few ways to fix this. One of the best general conversion utilities I have is one that Sree Kotay wrote. It's only safe to use when your FPU is in
double-precision mode, so you have to be careful about it if you're switching precision like above. It'll basically return '0' all the time if you're in single precision.
(I've recently discovered that this discussion bears a lot of resemblance to Chris Hecker's article on the topic, so be sure to read that if you can't figure out what I'm saying.)
This function is basically an ANSI C compliant conversion -- it always chops, always does the right thing, for positive or negative inputs.
typedef double lreal;
typedef float real;
typedef unsigned long uint32;
typedef long int32;
const lreal _double2fixmagic = 68719476736.0*1.5; //2^36 * 1.5, (52-_shiftamt=36) uses limited precisicion to floor
const int32 _shiftamt = 16; //16.16 fixed point representation,
#if BigEndian_
#define iexp_ 0
#define iman_ 1
#else
#define iexp_ 1
#define iman_ 0
#endif //BigEndian_
// ================================================================================================
// Real2Int
// ================================================================================================
inline int32 Real2Int(lreal val)
{
#if DEFAULT_CONVERSION
return val;
#else
val = val + _double2fixmagic;
return ((int32*)&val)[iman_] >> _shiftamt;
#endif
}
// ================================================================================================
// Real2Int
// ================================================================================================
inline int32 Real2Int(real val)
{
#if DEFAULT_CONVERSION
return val;
#else
return Real2Int ((lreal)val);
#endif
}
fistp
In either precision mode, you can call fistp (the regular conversion) directly. However, this means you need to know the current FPU rounding mode. In most cases, the following function will round the conversion to the nearest integer, rather than clamping towards zero, so that's what I call it:
inline int32 Round(real32 a) {
int32 retval;
__asm fld a
__asm fistp retval
return retval;
}
Direct conversions
I originally learned this one (and this way of thinking about the FPU) from
Dan Wallach when we were both at Microsoft in the summer of 1995. He showed me how to implement a fast lookup table by direct manipulation of the mantissa of a floating point number in a certain range.
First, you have to know a single precision float has three components:
sign[1 bit] exp[8 bits] mantissa[23 bits]
The value of the number is computed as:
(-1)^sign * 1.mantissa * 2^(exp - 127)
So what does that mean? Well, it has a nice effect:
Between any power of two and the next (e.g., [2, 4) ), the exponent is constant. For certain cases, you can just mask out the mantissa, and use that as a fixed-point number. Let's say you know your input is between 0 and 1, not including 1. You can do this:
int FloatTo23Bits(float x)
{
float y = x + 1.f;
return ((unsigned long&)y) & 0x7FFFFF; // last 23 bits
}
The first line makes 'y' lie between 1 and 2, where the exponent is a constant 127. Reading the last 23 bits gives an exact 23 bit representation of the number between 0 and 1. Fast and easy.
Timing: fast conversions
Sree and I have benchmarked and spent a lot of time on this problem. I tend to use fistp a lot more than his conversion, because I write a lot of code that needs single precision. His tends to be faster, so I need to remember to use it more.
In specific cases, the direct conversions can be very useful, but they're about as fast as Sree's code, so generally there's not too much advantage. You can save a shift, maybe, and it does work in single precision mode.
Each of the above functions is about 6 cycles by itself. However, the Real2Int version is much better at pairing with floating point (it doesn't lock the FPU for 6 cycles like fistp does.) So in really well pipelined code, his function can be close to free. fistp will take about 6 cycles.
Hacking VC's Runtime for Fun and Debugging
Finally, here's a function that overrides Microsoft's
_ftol (the root of all evil.) One of the comp.lang.x86.asm guys ripped this out of Microsoft's library, then Terje Mathison did the "OR" optimization, and then I hacked it into manually munging of the stack (note: no frame pointer?) like you see below. But don't do this at home -- it's evil too.
It also may have some bugs -- I'm not sure it works when there are floating point exceptions. Anyway, it's about 10-15 cycles faster than Microsoft's implementation.
Also, it will show up in a profile, which is a really great thing. You can put a breakpoint in it and see who's calling slow conversions, then go fix them. Overall, I don't recommend shipping code with it, but definitely use it for debugging.
Also, there's a "fast" mode that does simple rounding instead, but that doesn't get inlined, and it's generally a pain, since you can't get "ANSI correct" behavior when you want it.
#define ANSI_FTOL 1
extern "C" {
__declspec(naked) void _ftol() {
__asm {
#if ANSI_FTOL
fnstcw WORD PTR [esp-2]
mov ax, WORD PTR [esp-2]
OR AX, 0C00h
mov WORD PTR [esp-4], ax
fldcw WORD PTR [esp-4]
fistp QWORD PTR [esp-12]
fldcw WORD PTR [esp-2]
mov eax, DWORD PTR [esp-12]
mov edx, DWORD PTR [esp-8]
#else
fistp DWORD PTR [esp-12]
mov eax, DWORD PTR [esp-12]
mov ecx, DWORD PTR [esp-8]
#endif
ret
}
}
}
I got some great code from Kevin Egan at Brown University. He reimplemented precision control and the inline conversion calls with AT&T-compatible syntax so they work on gcc.
It's a lot of code, so I'm posting it at the end here. :)
#include
#include
#ifdef USE_SSE
#include
#endif // USE_SSE
/*
SAMPLE RUN
~/mod -> g++-3.2 fpu.cpp
~/mod -> ./a.out
ANSI slow, default FPU, float 1.80000 int 1
fast, default FPU, float 1.80000 int 2
ANSI slow, modified FPU, float 1.80000 int 1
fast, modified FPU, float 1.80000 int 1
ANSI slow, default FPU, float 1.80000 int 1
fast, default FPU, float 1.80000 int 2
ANSI slow, modified FPU, float 1.80000 int 1
fast, modified FPU, float 1.80000 int 1
ANSI slow, default FPU, float 1.10000 int 1
fast, default FPU, float 1.10000 int 1
ANSI slow, modified FPU, float 1.10000 int 1
fast, modified FPU, float 1.10000 int 1
ANSI slow, default FPU, float -1.80000 int -1
fast, default FPU, float -1.80000 int -2
ANSI slow, modified FPU, float -1.80000 int -1
fast, modified FPU, float -1.80000 int -1
ANSI slow, default FPU, float -1.10000 int -1
fast, default FPU, float -1.10000 int -1
ANSI slow, modified FPU, float -1.10000 int -1
fast, modified FPU, float -1.10000 int -1
*/
/**
* bits to set the floating point control word register
*
* Sections 4.9, 8.1.4, 10.2.2 and 11.5 in
* IA-32 Intel Architecture Software Developer's Manual
* Volume 1: Basic Architecture
*
* http://www.intel.com/design/pentium4/manuals/245471.htm
*
* http://www.geisswerks.com/ryan/FAQS/fpu.html
*
* windows has _controlfp() but it takes different parameters
*
* 0 : IM invalid operation mask
* 1 : DM denormalized operand mask
* 2 : ZM divide by zero mask
* 3 : OM overflow mask
* 4 : UM underflow mask
* 5 : PM precision, inexact mask
* 6,7 : reserved
* 8,9 : PC precision control
* 10,11 : RC rounding control
*
* precision control:
* 00 : single precision
* 01 : reserved
* 10 : double precision
* 11 : extended precision
*
* rounding control:
* 00 = Round to nearest whole number. (default)
* 01 = Round down, toward -infinity.
* 10 = Round up, toward +infinity.
* 11 = Round toward zero (truncate).
*/
#define __FPU_CW_EXCEPTION_MASK__ (0x003f)
#define __FPU_CW_INVALID__ (0x0001)
#define __FPU_CW_DENORMAL__ (0x0002)
#define __FPU_CW_ZERODIVIDE__ (0x0004)
#define __FPU_CW_OVERFLOW__ (0x0008)
#define __FPU_CW_UNDERFLOW__ (0x0010)
#define __FPU_CW_INEXACT__ (0x0020)
#define __FPU_CW_PREC_MASK__ (0x0300)
#define __FPU_CW_PREC_SINGLE__ (0x0000)
#define __FPU_CW_PREC_DOUBLE__ (0x0200)
#define __FPU_CW_PREC_EXTENDED__ (0x0300)
#define __FPU_CW_ROUND_MASK__ (0x0c00)
#define __FPU_CW_ROUND_NEAR__ (0x0000)
#define __FPU_CW_ROUND_DOWN__ (0x0400)
#define __FPU_CW_ROUND_UP__ (0x0800)
#define __FPU_CW_ROUND_CHOP__ (0x0c00)
#define __FPU_CW_MASK_ALL__ (0x1f3f)
#define __SSE_CW_FLUSHZERO__ (0x8000)
#define __SSE_CW_ROUND_MASK__ (0x6000)
#define __SSE_CW_ROUND_NEAR__ (0x0000)
#define __SSE_CW_ROUND_DOWN__ (0x2000)
#define __SSE_CW_ROUND_UP__ (0x4000)
#define __SSE_CW_ROUND_CHOP__ (0x6000)
#define __SSE_CW_EXCEPTION_MASK__ (0x1f80)
#define __SSE_CW_PRECISION__ (0x1000)
#define __SSE_CW_UNDERFLOW__ (0x0800)
#define __SSE_CW_OVERFLOW__ (0x0400)
#define __SSE_CW_DIVIDEZERO__ (0x0200)
#define __SSE_CW_DENORMAL__ (0x0100)
#define __SSE_CW_INVALID__ (0x0080)
// not on all SSE machines
// #define __SSE_CW_DENORMALZERO__ (0x0040)
#define __SSE_CW_MASK_ALL__ (0xffc0)
#define __MOD_FPU_CW_DEFAULT__ \
(__FPU_CW_EXCEPTION_MASK__ + __FPU_CW_PREC_DOUBLE__ + __FPU_CW_ROUND_CHOP__)
#define __MOD_SSE_CW_DEFAULT__ \
(__SSE_CW_EXCEPTION_MASK__ + __SSE_CW_ROUND_CHOP__ + __SSE_CW_FLUSHZERO__)
#ifdef USE_SSE
inline unsigned int getSSEStateX86(void);
inline void setSSEModDefault(unsigned int control);
inline void modifySSEStateX86(unsigned int control, unsigned int mask);
#endif // USE_SSE
inline void setRoundingMode(unsigned int round);
inline unsigned int getFPUStateX86(void);
inline void setFPUStateX86(unsigned int control);
inline void setFPUModDefault(void);
inline void assertFPUModDefault(void);
inline void modifyFPUStateX86(const unsigned int control, const unsigned int mask);
inline int FastFtol(const float a);
// assume for now that we are running on an x86
// #ifdef __i386__
#ifdef USE_SSE
inline
unsigned int
getSSEStateX86
(void)
{
return _mm_getcsr();
}
inline
void
setSSEStateX86
(unsigned int control)
{
_mm_setcsr(control);
}
inline
void
modifySSEStateX86
(unsigned int control, unsigned int mask)
{
unsigned int oldControl = getFPUStateX86();
unsigned int newControl = ((oldControl & (~mask)) | (control & mask));
setFPUStateX86(newControl);
}
inline
void
setSSEModDefault
(void)
{
modifySSEStateX86(__MOD_SSE_CW_DEFAULT__, __SSE_CW_MASK_ALL__);
}
#endif // USE_SSE
inline
void
setRoundingMode
(Uint32 round)
{
ASSERT(round < 4);
Uint32 mask = 0x3;
Uint32 fpuControl = getFPUStateX86();
fpuControl &= ~(mask << 10);
fpuControl |= round << 10;
setFPUStateX86(fpuControl);
#ifdef USE_SSE
Uint32 sseControl = getSSEStateX86();
sseControl &= ~(mask << 13);
sseControl |= round << 13;
setSSEStateX86(sseControl);
#endif // USE_SSE
}
inline
unsigned int
getFPUStateX86
(void)
{
unsigned int control = 0;
#if defined(_MSVC)
__asm fnstcw control;
#elif defined(__GNUG__)
__asm__ __volatile__ ("fnstcw %0" : "=m" (control));
#endif
return control;
}
/* set status */
inline
void
setFPUStateX86
(unsigned int control)
{
#if defined(_MSVC)
__asm fldcw control;
#elif defined(__GNUG__)
__asm__ __volatile__ ("fldcw %0" : : "m" (control));
#endif
}
inline
void
modifyFPUStateX86
(const unsigned int control, const unsigned int mask)
{
unsigned int oldControl = getFPUStateX86();
unsigned int newControl = ((oldControl & (~mask)) | (control & mask));
setFPUStateX86(newControl);
}
inline
void
setFPUModDefault
(void)
{
modifyFPUStateX86(__MOD_FPU_CW_DEFAULT__, __FPU_CW_MASK_ALL__);
assertFPUModDefault();
}
inline
void
assertFPUModDefault
(void)
{
assert((getFPUStateX86() & (__FPU_CW_MASK_ALL__)) ==
__MOD_FPU_CW_DEFAULT__);
}
// taken from http://www.stereopsis.com/FPU.html
// this assumes the CPU is in double precision mode
inline
int
FastFtol(const float a)
{
static int b;
#if defined(_MSVC)
__asm fld a
__asm fistp b
#elif defined(__GNUG__)
// use AT&T inline assembly style, document that
// we use memory as output (=m) and input (m)
__asm__ __volatile__ (
"flds %1 \n\t"
"fistpl %0 \n\t"
: "=m" (b)
: "m" (a));
#endif
return b;
}
void test()
{
float testFloats[] = { 1.8, 1.8, 1.1, -1.8, -1.1 };
int testInt;
unsigned int oldControl = getFPUStateX86();
for (int i = 0; i < 5; i++) {
float curTest = testFloats[i];
setFPUStateX86(oldControl);
testInt = (int) curTest;
printf("ANSI slow, default FPU, float %.5f int %d\n",
curTest, testInt);
testInt = FastFtol(curTest);
printf("fast, default FPU, float %.5f int %d\n",
curTest, testInt);
setFPUModDefault();
testInt = (int) curTest;
printf("ANSI slow, modified FPU, float %.5f int %d\n",
curTest, testInt);
testInt = FastFtol(curTest);
printf("fast, modified FPU, float %.5f int %d\n\n",
curTest, testInt);
}
}
int
main
(int argc, char** argv)
{
test();
return 0;
}
posted @
2008-03-02 23:19 Konami wiki 阅读(892) |
评论 (1) |
编辑 收藏
2007年12月24日
http://news.qq.com/a/20071224/000889.htm
《恶意取款者被判无期 专家称处罚太过令人震惊》
不好意思地转载了几位网友的评论:
[热] 腾讯网友 发表评论:[支持:2人 反对:35人 中立:0人]
连同发表反对重刑的所谓的“律师”一起判,许某钻银行的空子171次,而且挥霍一空,于情于理都没有可宽恕的地方,律师钻法律的空子,歪曲字面含义,应该取消其律师资格,永世不得录用
[热] 腾讯网友 发表评论:[支持:31人 反对:0人 中立:0人]
重得不是一点半点儿!贪污几个亿的也没死成,提了十几万就无期了?银行系统有问题管理者没有责任吗?那是不是银行的管理者以及软件制造商和ATM机制造商也得判?
[热] 腾讯网友 发表评论:[支持:72人 反对:0人 中立:1人]
ATM取出假钱--->银行无责
网上银行被盗--->储户责任
ATM机出现故障少给钱--->用户负责
ATM机出现故障多给钱--->用户盗窃,刑事责任
银行多给了钱--->储户义务归还
银行少给了钱---〉离开柜台银行概不负责
posted @
2007-12-24 09:50 Konami wiki 阅读(363) |
评论 (0) |
编辑 收藏
2007年11月9日
This Was A Triumph 这是一次大胜利
I'm Making A Note Here: 我要做点记录:
HUGE SUCCESS 巨大的成功!
It's hard to overstate 难以用语言表达
my satisfaction. 我的满足
Aperture Science 光圈科技
We do what we must 我们的做我们必须做的
because we can. 因为我们可以做大
For the good of all of us. 为了我们美好的一切
Except the ones who are dead. 除过那些死掉的人
But there's no sense crying over every mistake.在每次犯错后,哭也是毫无意义的
You just keep on trying 继续尝试
till you run out of cake. 直到”用完蛋糕“(不懂,延伸的太厉害了)
And the Science gets done. 直到我们的科技完成
And you make a neat gun. 你充当一头小白鼠
For the people who are 为了那些仍然活着的人
Still Alive
I'm not even angry. 我甚至都不生气
I'm being so sincere right now. 我现在是如此的纯真
Even though you broke my heart. 哪怕你使我心碎
And killed me. 而且杀了我
And tore me to pieces. 将我撕成碎片
And threw every piece into a fire. 扔进烈火里
As they burned it hurt because 碎片依然燃烧的那么凶
I was so happy for you! 因为我为你如此高兴!
Now these points of data make a beautiful line.现在这些数据成了如此美力的一条线
And we're out of beta. 我们不再是试验产品了
We're releasing on time. 我们从时间获得解放
So I'm GLAD. I got burned. 我如此开心,我被烧了
Think of all the things we learned 想想我们学到的东西
for the people who are 为了那些仍然活着的人们
still alive.
Go ahead and leave me. 前进吧,留下我
I think I prefer to stay inside. 我想我还是愿意呆在里面
Maybe you'll find someone else 可能你会找到其他人帮你
to help you.
Maybe Black Mesa. . . 可能黑山基地 T
HAT WAS A JOKE. HAHA FAT CHANCE.也是一个骗局,哈哈,好机会。
Anyway. this cake is great. 不管怎么样,蛋糕很棒
It's so delicious and moist. 如此美味
Look at me still talking 看着我,当我还能说话的时候
When Theres Science to do. 当还有实验的时候,
When I look out there, 我望向窗外
it makes me GLAD I'm not you. 我真高兴,我不是你
I've experiments to run. 我还有实验要做
There is research to be done. 还有研究要做
On the people who are 为了那些依然活着的人
still alive.
And believe me I am still alive. 相信我,我还活着
I'm doing Science and I'm still alive. 我还活着,而且我在做实验
T feel FANTASTIC and I'm still alive. 如此难以置信,我还活着
While you're dying I'll be still. 当你快死了,我也活着
And when you're dead I will be still alive.当你死了,我依旧活着
STILL ALIVE 依旧活着
posted @
2007-11-09 13:57 Konami wiki 阅读(517) |
评论 (0) |
编辑 收藏
2007年10月28日
decal是我一直想实现的一个3D技术之一,在这里纠正一下我之前的一篇关于decal的文章,那个其实只是利用解决平面decal下z-fighting的问题!无法解决任意表明的问题!由于工作太忙一直没有去搞最后还是“挤牙膏”的方式挤出点时间来,抓起Game programming GemII开始了decal的实现,花了2天终于搞出来了!
最后再恶习一下!呵呵!
snapshot1: decal rendering in wireframe mode.

snapshot2: decal rendering in solid mode ( no texture )

snapshot3 & 4: decal rendering with texture


posted @
2007-10-28 10:48 Konami wiki 阅读(377) |
评论 (0) |
编辑 收藏
2007年10月20日
最近研究了一下NVPerfHUD,感觉它太强大了!相比之下PIX要差点( just my peronal viewpoint ),个人认为这是PC 3D游戏开发者必备的东西,目前我很难找到形容词来赞美它(无情地赞美就免了, 呵呵)
最后放点图来show哈 恶习啊!!!=。=|||
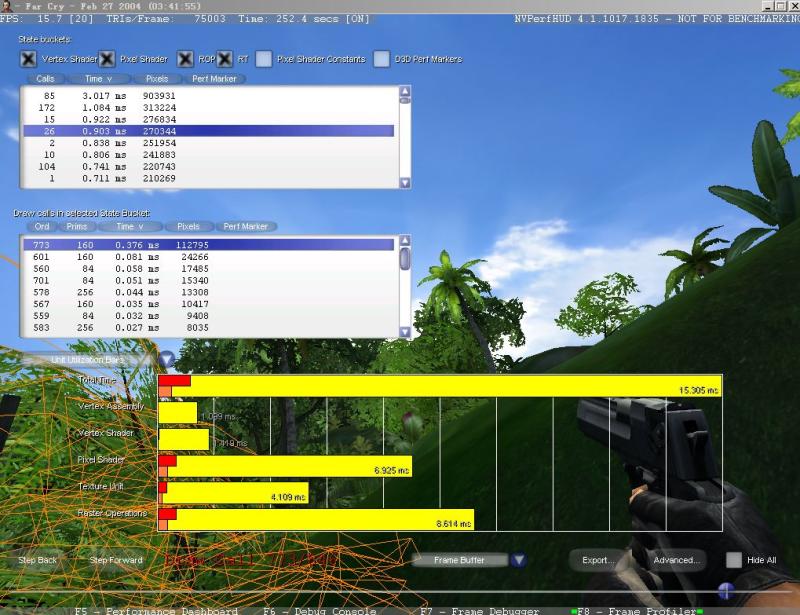
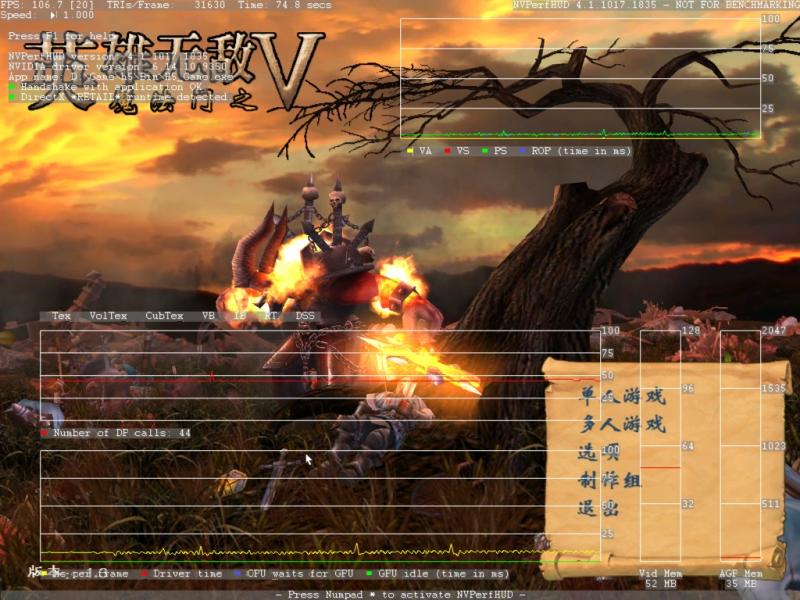
posted @
2007-10-20 20:32 Konami wiki 阅读(793) |
评论 (1) |
编辑 收藏
2007年10月19日
This article is quoted from forums of GameDev.net( In fact it is a thread )The question :
----------------------------------------------------------------------------------------------------------------------------------------------------------------
Hello all,
I am slightly unsure of which direction to take. I have a large array which will contain data pulled from a file. Like always, I proceeded to declare this array:
int array[1000];
Then I remembered some code that I saw in a tutorial:
int *array;
array = new int[1000];
I read up on it and it seems that dynamic memory goes on the heap, while static memory goes on the stack. I also learned that the heap is much larger than the stack. So my question is, which of the above methods is the best? And please correct me if I'm wrong on my new found knowledge. Thank you.
The answer: ( selected )
----------------------------------------------------------------------------------------------------------------------------------------------------------------
Many people like to think there are 2 types of memory, stack and heap ... because that's all most people have to think about most the time, there are really more than that.
There is data segment data (as mentioned by fpsgamer) and memory mapped i/o addresses (for instance when you write to video buffers or files, it is not using normal ram, it is just that certain addresses are mapped by the os to write to certain destinations).
between the 3 you can control:
// without initialization
int dataSegment[1000];
int main()
{
int stack[1000];
int *heap;
heap = new int[1000];
}
// with initialization
int dataSegmentB[4] = {56, 23, 11, 945};
int mainB()
{
int stackB[4] = {56, 23, 11, 945};
int *heapB;
heap = new int[4];
heapB[0] = 56;
heapB[1] = 23;
heapB[2] = 11;
heapB[3] = 945;
}
The dataSegment normallys grows the size of your executable to hold it. This data will then be loaded in main memory when the program loads, along with the rest of the application.
The stack values are pushed onto the stack when the function is called and poped off when it returns. if a function is in the call stack more than once (ie recursion) than there is memory in the stack for each instance, and that memory may of course have different values.
paramters to function are passed on the stack. In fact the purpose of the stack is to hold the return address of the function, its parameters, and its local variables.
there is a stack PER THREAD.
The heap values are allocated by the language or operating system from a dynamic pool of memory. The heap is shared by all threads in a process (in most normal OSes) so it can be slower to use heap memory in multithread capable apps because they must use locks to protect allocations and returns that use the heap. Many advanced systems have been built to have block allocating heaps, or thread specific heaps to eliminate various costs when it is important.
In general the cost of accessing any memory once allocated is not at all based on stack / data segment / heap ... but instead is based on whether or not the memory is currently in the CPU cache, if not, it causes a cache miss. This is based almost exclusively on how recently the memory was accessed, so hitting the same area in the heap 500 times in a row is no different than hitting the stack 500 times in a row. But hitting 40 variables right next to each other in the stack is less likely to use many data pages of cache than hitting 40 variables allocated on the heap ... especially if those variables we're allocated at different times in the application, and vary in size, etc.
The stack is often very limited in size (like 8kb on many platforms), so it is a VERY bad choice to use the stack for large data. Although the normal reason you choose between heap and stack is not size, but object lifetime. If the variable needs to exist only for the life of the function - and is known at compile time, it should be put on the stack (unless it is very large). If it needs to exist for longer than the life of the function it cannot be put on the stack, so only heap and data segment are possible. data segment values are, by definition, alive for the entire application and are effectively permanent globals / statics.
posted @
2007-10-19 12:07 Konami wiki 阅读(443) |
评论 (0) |
编辑 收藏
2007年10月5日
Those two identifiers are hints to the driver for how the buffer will be used, to optimize how the card accesses the data. They make sense even without AGP memory.
On systems with AGP memory, there are three classes of memory:
1) System Memory. This is cached, and reasonably fast to read from and write to with the CPU. However, it typically needs an additional copy before the graphics card can use it. System and scratch pool memory goes here.
2) AGP Memory. This is still CPU-local RAM, but it is not cached. This means that it's slow to read from, and it's slow to write to, UNLESS you write sequentially, without doing too much other memory traffic inbetween, and overwrite every byte, so that the write combiners don't need to fetch lines from RAM to do a combine. Thus, generating software-transformed vertices as a stream into this buffer might still be fast. For the GPU, the AGP memory is directly accessible, so no additional copy is needed. Dynamic pool memory goes here.
3) Video Memory. This is RAM that's local to the GPU. It typically has insanely high throughput. It is accessible over the bus for the CPU, but going over the bus is really slow; typically both for reading and for writing. Thus writing directly into this memory (or even worse, reading out of it), is not recommended. Default pool memory goes here.
On systems with PCI-Express, some of the AGP vs system memory differences are reduced, but the usage hints you're giving the driver ("I will change the data by writing it sequentially" vs "I will not change the data much") are still useful for optimizing performance.
Video memory is the memory chips physically located on the card. The card can easily access this memory, while reading it from the CPU is extremely slow.
AGP memory a part of your main memory on the motherboard that has been set aside for talking to the graphics card. The card and your CPU can access this memory at a decent speed.
This pageshows that your BIOS "AGP aperture size" controls the size of your AGP memory, and explains how "reducing the AGP aperture size won't save you any RAM. Again, what setting the AGP aperture size does is limit the amount of RAM the AGP bus can appropriate when it needs to. It is not used unless absolutely necessary. So, setting a 64MB AGP aperture doesn't mean 64MB of your RAM will be used up as AGP memory. It will only limit the maximum amount that can be used by the AGP bus to 64MB (with a usable AGP memory size of only 26MB)."
1) video memory can mean one of two things depending on the context the term is used in:
a. video memory is generally any memory which is used by the graphics chip.
b. video memory (correctly "local video memory") is memory that exists on the graphic card itself (i.e. RAM chips that live on the graphics card, they are 'local' to the graphics chip).
2) AGP memory is main memory on your system motherboard that has been specially assigned for graphics use. The "AGP Aperture" setting in your system BIOS controls this assignment. The more you have assigned for AGP use, the less you have for general system use. AGP memory is sometimes also known as "non-local video memory".
3a) 'Local' video memory is very fast for the graphics chip to read from and write to because it is 'local' to the graphics chip.
3b) 'Local' video memory is extremely slow to read from using for the system CPU, and reasonably slow to write to using the system CPU.
This is for a number of reasons; partly because the memory is physically on a different board (the graphics card) to the CPU (i.e. it's not 'local' for the CPU); partly because that memory isn't cached at all for reads using the CPU, and only burst cached for writes; partly due to the way data transfers over bus standards such as AGP must be done.
4a) AGP memory is reasonably fast for the graphics chip to read from or write to, but not as fast as local video memory.
4b) AGP memory is fairly slow to read from using the system CPU because it is marked as "Write Combined" so any reads don't benefit from the L2 and L1 caches (i.e. each read is effectively a cache-miss).
AGP memory is however faster than local video memory to read from using the CPU since it is local to the CPU.
4c) AGP memory is reasonably fast to write to using the system CPU. Although not fully cached, "Write Combined" memory uses a small buffer that collects sequential writes to memory (32 or 64 bytes IIRC) and writes them out in one go. This is why sequential access of vertex data using the CPU is preferable for performance.
5) D3DUSAGE_DYNAMIC is only a hint to the display driver about how you intend using that resource, usually it will give you AGP memory, but it isn't guaranteed (so don't rely it!).
6) Generally, for vertex buffers which you need to Lock() and update using the CPU regularly at runtime should be D3DUSAGE_DYNAMIC, and all others should be static.
7) Graphics drivers use techniques such as "buffer renaming" where multiple copies of the buffer are created and cycled through to reduce the chance of stalls when dynamic resources are locked. This is why it's essential to use the D3DLOCK_DISCARD and D3DLOCK_NOOVERWRITE locking flags correctly if you want good performance. It's also one of the many reasons you shouldn't rely on the data pointer from a Lock() after the resource has been unlocked.
8) General advice for good performance:
- treat all graphics resources as write-only for the CPU, particularly those in local video memory. CPU reads from graphics resources is a recipe for slowness.
- CPU writes to locked graphics resources should be done sequentially.
- it's better to write all of a vertex out to memory with the CPU than it is to skip elements of it. Skipping can harm the effectiveness of write combining, and even cause hidden reads in some situations (and reads are bad - see above).
since the "local video memory" is fast for video card to manipulate, and the video card dedicated to GRAPHICS PROCESS,why bother to use the "AGP memory"?
is that only because the "local video memory" may be not enough for graphic data storage?
what role does the CPU play in the process of graphics??
Yes. That's one of the main reasons. AGP comes from a time (~10 years ago!) when a typical graphics card would have, say, 2MB of local video memory and a typical PC system had 64-128MB of main system memory, so it made sense to set some system memory aside for situations where there wasn't enough local memory.
In these days of monster graphics cards with 512MB of local video memory, it's less likely used as an overflow.
Another reason is dynamic graphics data - any data that needs to be regularly modified with the CPU is usually better off in AGP memory (it's write combined, but it's local to the CPU too, so uses less CPU time to access)
Not very much these days. Mostly application-side jobs like writing vertex data into locked buffers, object culling, traversing scene graphs, loading resources into main memory, things like that.
On the D3D and device driver side: handling the D3D API, swizzling and other conversion when some types of resources are locked/unlocked [I believe some GPUs can even do their own swizzling now though], and setting up the command buffer for the GPU.
Before hardware T&L, the CPU also handled all vertex processing.
The fact that modern GPUs now handle so much of the graphics pipeline makes avoiding unnecessary serialization between CPU and GPU all the more important (i.e. stalls where one has a resource locked and the other wants to use it), thus things like buffer renaming. Serialization between CPU and GPU throws away the GPUs processing ability.
posted @
2007-10-05 14:50 Konami wiki 阅读(1074) |
评论 (0) |
编辑 收藏