在Makefile中可以使用函数来处理变量,从而让我们的命令或是规则更为的灵活和具 有智能。make所支持的函数也不算很多,不过已经足够我们的操作了。函数调用后,函 数的返回值可以当做变量来使用。
一、函数的调用语法
函数调用,很像变量的使用,也是以“$”来标识的,其语法如下:
$(<function> <arguments> )
或是
${<function> <arguments>}
这里,<function>就是函数名,make支持的函数不多。<arguments>是函数的参数,参数
间以逗号“,”分隔,而函数名和参数之间以“空格”分隔。函数调用以“$”开头,以圆
括号或花括号把函数名和参数括起。感觉很像一个变量,是不是?函数中的参数可以使
用变量,为了风格的统一,函数和变量的括号最好一样,如使用“$(substa,b,$(x))”这
样的形式,而不是“$(substa,b,${x})”的形式。因为统一会更清楚,也会减少一些不必
要的麻烦。
还是来看一个示例:
comma:= ,
empty:=
space:= $(empty) $(empty)
foo:= a b c
bar:= $(subst $(space),$(comma),$(foo))
在这个示例中,$(comma)的值是一个逗号。$(space)使用了$(empty)定义了一个空格,
$(foo)的值是“a b c”,$(bar)的定义用,调用了函数“subst”,这是一个替换函数,这
个函数有三个参数,第一个参数是被替换字串,第二个参数是替换字串,第三个参数
是替换操作作用的字串。这个函数也就是把$(foo)中的空格替换成逗号,所以$(bar)的值
是“a,b,c”。
二、字符串处理函数
$(subst <from>,<to>,<text> )
名称:字符串替换函数——subst。
功能:把字串<text>中的<from>字符串替换成<to>。
返回:函数返回被替换过后的字符串。
示例:
$(subst ee,EE,feet on the street),
把“feetonthestreet”中的“ee”替换成“EE”,返回结果是“fEEtonthestrEEt”。
$(patsubst <pattern>,<replacement>,<text> )
名称:模式字符串替换函数——patsubst。
功能:查找<text>中的单词(单词以“空格”、“Tab”或“回车”“换行”分隔)是否
符合模式<pattern>,如果匹配的话,则以<replacement>替换。这里,<pattern>可以包括
通配符“%”,表示任意长度的字串。如果<replacement>中也包含“%”,那么,
<replacement>中的这个“%”将是<pattern>中的那个“%”所代表的字串。(可以用“\”
来转义,以“\%”来表示真实含义的“%”字符)
返回:函数返回被替换过后的字符串。
示例:
$(patsubst %.c,%.o,x.c.c bar.c)
把字串“x.c.cbar.c”符合模式[%.c]的单词替换成[%.o],返回结果是“x.c.obar.o”
备注:
这和我们前面“变量章节”说过的相关知识有点相似。如:
“$(var:<pattern>=<replacement> )”
相当于
“$(patsubst <pattern>,<replacement>,$(var))”,
而“$(var:<suffix>=<replacement>)”
则相当于
“$(patsubst %<suffix>,%<replacement>,$(var))”。
例如有:objects=foo.obar.obaz.o,
那么,“$(objects:.o=.c)”和“$(patsubst%.o,%.c,$(objects))”是一样的。
$(strip <string> )
名称:去空格函数——strip。
功能:去掉<string>字串中开头和结尾的空字符。
返回:返回被去掉空格的字符串值。
示例:
$(strip a b c )
把字串“abc”去到开头和结尾的空格,结果是“abc”。
$(findstring <find>,<in> )
名称:查找字符串函数——findstring。
功能:在字串<in>中查找<find>字串。
返回:如果找到,那么返回<find>,否则返回空字符串。
示例:
$(findstring a,a b c)
$(findstring a,b c)
第一个函数返回“a”字符串,第二个返回“”字符串(空字符串)
$(filter <pattern...>,<text> )
名称:过滤函数——filter。
功能:以<pattern>模式过滤<text>字符串中的单词,保留符合模式<pattern>的单词。可
以有多个模式。
返回:返回符合模式<pattern>的字串。
示例:
sources := foo.c bar.c baz.s ugh.h
foo: $(sources)
cc $(filter %.c %.s,$(sources)) -o foo
$(filter %.c %.s,$(sources))返回的值是“foo.c bar.c baz.s”。
$(filter-out <pattern...>,<text> )
名称:反过滤函数——filter-out。
功能:以<pattern>模式过滤<text>字符串中的单词,去除符合模式<pattern>的单词。可
以有多个模式。
返回:返回不符合模式<pattern>的字串。
示例:
objects=main1.o foo.o main2.o bar.o
mains=main1.o main2.o
$(filter-out $(mains),$(objects)) 返回值是“foo.o bar.o”。
$(sort <list> )
名称:排序函数——sort。
功能:给字符串<list>中的单词排序(升序)。
返回:返回排序后的字符串。
示例:$(sortfoobarlose)返回“barfoolose”。
备注:sort函数会去掉<list>中相同的单词。
$(word <n>,<text> )
名称:取单词函数——word。
功能:取字符串<text>中第<n>个单词。(从一开始)
返回:返回字符串<text>中第<n>个单词。如果<n>比<text>中的单词数要大,那么返回
空字符串。
示例:$(word2,foobarbaz)返回值是“bar”。
$(wordlist <s>,<e>,<text> )
名称:取单词串函数——wordlist。
功能:从字符串<text>中取从<s>开始到<e>的单词串。<s>和<e>是一个数字。
返回:返回字符串<text>中从<s>到<e>的单词字串。如果<s>比<text>中的单词数要大,
那么返回空字符串。如果<e>大于<text>的单词数,那么返回从<s>开始,到<text>结束
的单词串。
示例:$(wordlist2,3,foobarbaz)返回值是“barbaz”。
$(words <text> )
名称:单词个数统计函数——words。
功能:统计<text>中字符串中的单词个数。
返回:返回<text>中的单词数。
示例:$(words,foobarbaz)返回值是“3”。
备注:如果我们要取<text>中最后的一个单词,我们可以这样:$(word $(words
<text> ),<text> )。
$(firstword <text> )
名称:首单词函数——firstword。
功能:取字符串<text>中的第一个单词。
返回:返回字符串<text>的第一个单词。
示例:$(firstwordfoobar)返回值是“foo”。
备注:这个函数可以用word函数来实现:$(word1,<text>)。
以上,是所有的字符串操作函数,如果搭配混合使用,可以完成比较复杂的功能。这里,
举一个现实中应用的例子。我们知道,make使用“VPATH”变量来指定“依赖文件”的
搜索路径。于是,我们可以利用这个搜索路径来指定编译器对头文件的搜索路径参数
CFLAGS,如:
override CFLAGS += $(patsubst %,-I%,$(subst :, ,$(VPATH)))
如果我们的“$(VPATH)”值是“src:../headers”,那么“$(patsubst %,-I%,$(subst :, ,
$(VPATH)))”将返回“-Isrc -I../headers”,这正是 cc 或 gcc 搜索头文件路径的参数。
三、文件名操作函数
下面我们要介绍的函数主要是处理文件名的。每个函数的参数字符串都会被当做一个或
是一系列的文件名来对待。
$(dir <names...> )
名称:取目录函数——dir。
功能:从文件名序列<names>中取出目录部分。目录部分是指最后一个反斜杠(“/”)
之前的部分。如果没有反斜杠,那么返回“./”。
返回:返回文件名序列<names>的目录部分。
示例:$(dirsrc/foo.chacks)返回值是“src/./”。
$(notdir <names...> )
名称:取文件函数——notdir。
功能:从文件名序列<names>中取出非目录部分。非目录部分是指最后一个反斜杠(“/
”)之后的部分。
返回:返回文件名序列<names>的非目录部分。
示例:$(notdirsrc/foo.chacks)返回值是“foo.chacks”。
$(suffix <names...> )
名称:取后缀函数——suffix。
功能:从文件名序列<names>中取出各个文件名的后缀。
返回:返回文件名序列<names>的后缀序列,如果文件没有后缀,则返回空字串。
示例:$(suffixsrc/foo.csrc-1.0/bar.chacks)返回值是“.c.c”。
$(basename <names...> )
名称:取前缀函数——basename。
功能:从文件名序列<names>中取出各个文件名的前缀部分。
返回:返回文件名序列<names>的前缀序列,如果文件没有前缀,则返回空字串。
示例:$(basenamesrc/foo.csrc-1.0/bar.chacks)返回值是“src/foosrc-1.0/barhacks”。
$(addsuffix <suffix>,<names...> )
名称:加后缀函数——addsuffix。
功能:把后缀<suffix>加到<names>中的每个单词后面。
返回:返回加过后缀的文件名序列。
示例:$(addsuffix.c,foobar)返回值是“foo.cbar.c”。
$(addprefix <prefix>,<names...> )
名称:加前缀函数——addprefix。
功能:把前缀<prefix>加到<names>中的每个单词后面。
返回:返回加过前缀的文件名序列。
示例:$(addprefixsrc/,foobar)返回值是“src/foosrc/bar”。
$(join <list1>,<list2> )
名称:连接函数——join。
功能:把<list2>中的单词对应地加到<list1>的单词后面。如果<list1>的单词个数要比
<list2>的多,那么,<list1>中的多出来的单词将保持原样。如果<list2>的单词个数要比
<list1>多,那么,<list2>多出来的单词将被复制到<list2>中。
返回:返回连接过后的字符串。
示例:$(joinaaabbb,111222333)返回值是“aaa111bbb222333”。
四、foreach函数
foreach 函数和别的函数非常的不一样。因为这个函数是用来做循环用的,Makefile 中的
foreach 函数几乎是仿照于 Unix 标准 Shell(/bin/sh)中的 for 语句,或是 C-Shell
(/bin/csh)中的foreach语句而构建的。它的语法是:
$(foreach <var>,<list>,<text> )
这个函数的意思是,把参数<list>中的单词逐一取出放到参数<var>所指定的变量中,
然后再执行<text>所包含的表达式。每一次<text>会返回一个字符串,循环过程中,
<text>的所返回的每个字符串会以空格分隔,最后当整个循环结束时,<text>所返回的
每个字符串所组成的整个字符串(以空格分隔)将会是foreach函数的返回值。
所以,<var>最好是一个变量名,<list>可以是一个表达式,而<text>中一般会使用
<var>这个参数来依次枚举<list>中的单词。举个例子:
names := a b c d
files := $(foreach n,$(names),$(n).o)
上面的例子中,$(name)中的单词会被挨个取出,并存到变量“n”中,“$(n).o”每次根
据“$(n)”计算出一个值,这些值以空格分隔,最后作为foreach函数的返回,所以,
$(files)的值是“a.o b.o c.o d.o”。
注意,foreach中的<var>参数是一个临时的局部变量,foreach函数执行完后,参数
<var>的变量将不在作用,其作用域只在 foreach 函数当中。
五、if函数
if 函数很像 GNU 的 make 所支持的条件语句——ifeq(参见前面所述的章节),if 函数
的语法是:
$(if <condition>,<then-part> )
或是
$(if <condition>,<then-part>,<else-part> )
可见,if函数可以包含“else”部分,或是不含。即if函数的参数可以是两个,也可以是
三个。<condition>参数是if的表达式,如果其返回的为非空字符串,那么这个表达式就
相当于返回真,于是,<then-part>会被计算,否则<else-part>会被计算。
而if函数的返回值是,如果<condition>为真(非空字符串),那个<then-part>会是整
个函数的返回值,如果<condition>为假(空字符串),那么<else-part>会是整个函数的
返回值,此时如果<else-part>没有被定义,那么,整个函数返回空字串。
所以,<then-part>和<else-part>只会有一个被计算。
六、call函数
call 函数是唯一一个可以用来创建新的参数化的函数。你可以写一个非常复杂的表达式,
这个表达式中,你可以定义许多参数,然后你可以用call函数来向这个表达式传递参
数。其语法是:
$(call <expression>,<parm1>,<parm2>,<parm3>...)
当make执行这个函数时,<expression>参数中的变量,如$(1),$(2),$(3)等,会被参
数<parm1>,<parm2>,<parm3>依次取代。而<expression>的返回值就是call函数的返
回值。例如:
reverse = $(1) $(2)
foo = $(call reverse,a,b)
那么,foo的值就是“ab”。当然,参数的次序是可以自定义的,不一定是顺序的,如:
reverse = $(2) $(1)
foo = $(call reverse,a,b)
此时的foo的值就是“ba”。
七、origin函数
origin 函数不像其它的函数,他并不操作变量的值,他只是告诉你你的这个变量是哪里
来的?其语法是:
$(origin <variable> )
注意,<variable>是变量的名字,不应该是引用。所以你最好不要在<variable>中使用“
$”字符。Origin 函数会以其返回值来告诉你这个变量的“出生情况”,下面,是 origin
函数的返回值:
“undefined”
如果<variable>从来没有定义过,origin函数返回这个值“undefined”。
“default”
如果<variable>是一个默认的定义,比如“CC”这个变量,这种变量我们将在后面讲述。
“environment”
如果<variable>是一个环境变量,并且当Makefile被执行时,“-e”参数没有被打开。
“file”
如果<variable>这个变量被定义在Makefile中。
“command line”
如果<variable>这个变量是被命令行定义的。
“override”
如果<variable>是被override指示符重新定义的。
“automatic”
如果<variable>是一个命令运行中的自动化变量。关于自动化变量将在后面讲述。
这些信息对于我们编写Makefile是非常有用的,例如,假设我们有一个Makefile其包
了一个定义文件Make.def,在Make.def中定义了一个变量“bletch”,而我们的环境中
也有一个环境变量“bletch”,此时,我们想判断一下,如果变量来源于环境,那么我
们就把之重定义了,如果来源于Make.def或是命令行等非环境的,那么我们就不重新
定义它。于是,在我们的Makefile中,我们可以这样写:
ifdef bletch
ifeq "$(origin bletch)" "environment"
bletch = barf, gag, etc.
endif
endif
当然,你也许会说,使用override关键字不就可以重新定义环境中的变量了吗?为什
么需要使用这样的步骤?是的,我们用override是可以达到这样的效果,可是override
过于粗暴,它同时会把从命令行定义的变量也覆盖了,而我们只想重新定义环境传来
的,而不想重新定义命令行传来的。
八、shell函数
shell 函数也不像其它的函数。顾名思义,它的参数应该就是操作系统 Shell 的命令。它和
反引号“`”是相同的功能。这就是说,shell函数把执行操作系统命令后的输出作为函数
返回。于是,我们可以用操作系统命令以及字符串处理命令awk,sed等等命令来生成
一个变量,如:
contents := $(shell cat foo)
files := $(shell echo *.c)
注意,这个函数会新生成一个Shell程序来执行命令,所以你要注意其运行性能,如果
你的Makefile中有一些比较复杂的规则,并大量使用了这个函数,那么对于你的系统
性能是有害的。特别是Makefile的隐晦的规则可能会让你的shell函数执行的次数比你
想像的多得多。
posted @
2014-09-01 15:09 yuhen 阅读(678) |
评论 (0) |
编辑 收藏1. os.system
import os
import tempfile
filename1 = tempfile.mktemp (".txt")
open (filename1, "w").close ()
filename2 = filename1 + ".copy"
print filename1, "=>", filename2
#拷文件
os.system ("copy %s %s" % (filename1, filename2))
if os.path.isfile (filename2): print "Success"
dirname1 = tempfile.mktemp (".dir")
os.mkdir (dirname1)
dirname2 = dirname1 + ".copy"
print dirname1, "=>", dirname2
#拷目录
os.system ("xcopy /s %s %s" % (dirname1, dirname2))
if os.path.isdir (dirname2): print "Success"
2. shutil.copy和shutil.copytree
import os
import shutil
import tempfile
filename1 = tempfile.mktemp (".txt")
open (filename1, "w").close ()
filename2 = filename1 + ".copy"
print filename1, "=>", filename2
#拷文件
shutil.copy (filename1, filename2)
if os.path.isfile (filename2): print "Success"
dirname1 = tempfile.mktemp (".dir")
os.mkdir (dirname1)
dirname2 = dirname1 + ".copy"
print dirname1, "=>", dirname2
#拷目录
shutil.copytree (dirname1, dirname2)
if os.path.isdir (dirname2): print "Success"
3. win32file.CopyFile
import os
import win32file
import tempfile
filename1 = tempfile.mktemp (".txt")
open (filename1, "w").close ()
filename2 = filename1 + ".copy"
print filename1, "=>", filename2
#拷文件
#文件已存在时,1为不覆盖,0为覆盖
win32file.CopyFile (filename1, filename2, 1)
win32file.CopyFile (filename1, filename2, 0)
win32file.CopyFile (filename1, filename2, 1)
if os.path.isfile (filename2): print "Success"
dirname1 = tempfile.mktemp (".dir")
os.mkdir (dirname1)
dirname2 = dirname1 + ".copy"
print dirname1, "=>", dirname2
#拷目录
win32file.CopyFile (dirname1, dirname2, 1)
if os.path.isdir (dirname2): print "Success"
4. SHFileOperation
import os
from win32com.shell import shell, shellcon
import tempfile
filename1 = tempfile.mktemp (".txt")
open (filename1, "w").close ()
filename2 = filename1 + ".copy"
print filename1, "=>", filename2
#拷文件
#文件已存在时,shellcon.FOF_RENAMEONCOLLISION会指示重命名文件
shell.SHFileOperation (
(0, shellcon.FO_COPY, filename1, filename2, 0, None, None)
)
shell.SHFileOperation (
(0, shellcon.FO_COPY, filename1, filename2, shellcon.FOF_RENAMEONCOLLISION, None, None)
)
shell.SHFileOperation (
(0, shellcon.FO_COPY, filename1, filename2, 0, None, None)
)
if os.path.isfile (filename2): print "Success"
dirname1 = tempfile.mktemp (".dir")
os.mkdir (dirname1)
dirname2 = dirname1 + ".copy"
print dirname1, "=>", dirname2
#拷目录
shell.SHFileOperation (
(0, shellcon.FO_COPY, dirname1, dirname2, 0, None, None)
)
if os.path.isdir (dirname2): print "Success"
不知道有没有其它的了,os.rename不算,那个是移动文件。另外我在测试它们的性能如何。
http://timgolden.me.uk/python/win32_how_do_i/copy-a-file.html
这里和楼主列出的都一样,没有更多的了
或者使用Chilkat http://www.chilkatsoft.com/refdoc/pythonCkFileAccessRef.html
测试结果出来了:
测试环境:系统——Win7 RTM,CPU——P4 3.0,MEM——1.5G DDR400,U盘——Kingston 4G
用4种不同的方法从硬盘拷贝MSDN 2008 SP1(2.37G)到U盘:
os System 的方法耗时903.218秒
shutil 的方法耗时1850.634秒
win32file 的方法耗时861.438秒
SHFileOperation的方法耗时794.023秒
另外SHFileOperation是显示对话框的,可以这样用
shell.SHFileOperation (
(0, shellcon.FO_COPY, filename1, filename2,
shellcon.FOF_RENAMEONCOLLISION | \
shellcon.FOF_NOCONFIRMATION |\
shellcon.FOF_NOERRORUI | \
shellcon.FOF_SILENT, None, None)
)
posted @
2014-08-14 15:14 yuhen 阅读(666) |
评论 (0) |
编辑 收藏
摘要: 做视频采集与处理,自然少不了要学会分析YUV数据。因为从采集的角度来说,一般的视频采集芯片输出的码流一般都是YUV数据流的形式,而从视频处理(例如H.264、MPEG视频编解码)的角度来说,也是在原始YUV码流进行编码和解析,所以,了解如何分析YUV数据流对于做视频领域的人而言,至关重要。本文就是根据我的学习和了解,简单地介绍如何分析YUV数据流。 YUV,分为...
阅读全文
posted @
2014-06-25 15:30 yuhen 阅读(604) |
评论 (0) |
编辑 收藏
对于.lds文件,它定义了整个程序编译之后的连接过程,决定了一个可执行程序的各个段的存储位置。虽然现在我还没怎么用它,但感觉还是挺重要的,有必要了解一下。
|
SECTIONS {
...
secname start BLOCK(align) (NOLOAD) : AT ( ldadr )
{ contents } >region :phdr =fill
...
} |
secname和contents是必须的,其他的都是可选的。下面挑几个常用的看看:
1、secname:段名
2、contents:决定哪些内容放在本段,可以是整个目标文件,也可以是目标文件中的某段(代码段、数据段等)
3、start:本段连接(运行)的地址,如果没有使用AT(ldadr),本段存储的地址也是start。GNU网站上说start可以用任意一种描述地址的符号来描述。
4、AT(ldadr):定义本段存储(加载)的地址。
看一个简单的例子:(摘自《2410完全开发》)
|
/* nand.lds */
SECTIONS {
firtst 0x00000000 : { head.o init.o }
second 0x30000000 : AT(4096) { main.o }
} |
以上,head.o放在0x00000000地址开始处,init.o放在head.o后面,他们的运行地址也是0x00000000,即连接和存储地址相同(没有AT指定);main.o放在4096(0x1000,是AT指定的,存储地址)开始处,但是它的运行地址在0x30000000,运行之前需要从0x1000(加载处)复制到0x30000000(运行处),此过程也就用到了读取Nand flash。
这就是存储地址和连接(运行)地址的不同,称为加载时域和运行时域,可以在.lds连接脚本文件中分别指定。
编写好的.lds文件,在用arm-linux-ld连接命令时带-Tfilename来调用执行,如
arm-linux-ld –Tnand.lds x.o y.o –o xy.o。也用-Ttext参数直接指定连接地址,如
arm-linux-ld –Ttext 0x30000000 x.o y.o –o xy.o。
既然程序有了两种地址,就涉及到一些跳转指令的区别,这里正好写下来,以后万一忘记了也可查看,以前不少东西没记下来现在忘得差不多了。。。
ARM汇编中,常有两种跳转方法:b跳转指令、ldr指令向PC赋值。
我自己经过归纳如下:
(1) b step1 :b跳转指令是相对跳转,依赖当前PC的值,偏移量是通过该指令本身的bit[23:0]算出来的,这使得使用b指令的程序不依赖于要跳到的代码的位置,只看指令本身。
(2) ldr pc, =step1 :该指令是从内存中的某个位置(step1)读出数据并赋给PC,同样依赖当前PC的值,但是偏移量是那个位置(step1)的连接地址(运行时的地址),所以可以用它实现从Flash到RAM的程序跳转。
(3) 此外,有必要回味一下adr伪指令,U-boot中那段relocate代码就是通过adr实现当前程序是在RAM中还是flash中。仍然用我当时的注释:
|
relocate: /* 把U-Boot重新定位到RAM */
adr r0, _start /* r0是代码的当前位置 */
/* adr伪指令,汇编器自动通过当前PC的值算出 如果执行到_start时PC的值,放到r0中:
当此段在flash中执行时r0 = _start = 0;当此段在RAM中执行时_start = _TEXT_BASE(在board/smdk2410/config.mk中指定的值为0x33F80000,即u-boot在把代码拷贝到RAM中去执行的代码段的开始) */
ldr r1, _TEXT_BASE /* 测试判断是从Flash启动,还是RAM */
/* 此句执行的结果r1始终是0x33FF80000,因为此值是又编译器指定的(ads中设置,或-D设置编译器参数) */
cmp r0, r1 /* 比较r0和r1,调试的时候不要执行重定位 */ |
下面,结合u-boot.lds看看一个正式的连接脚本文件。这个文件的基本功能还能看明白,虽然上面分析了好多,但其中那些GNU风格的符号还是着实让我感到迷惑,好菜啊,怪不得连被3家公司鄙视,自己鄙视自己。。。
OUTPUT_FORMAT("elf32­littlearm", "elf32­littlearm", "elf32­littlearm")
;指定输出可执行文件是elf格式,32位ARM指令,小端
OUTPUT_ARCH(arm)
;指定输出可执行文件的平台为ARM
ENTRY(_start)
;指定输出可执行文件的起始代码段为_start.
SECTIONS
{
. = 0x00000000 ; 从0x0位置开始
. = ALIGN(4) ; 代码以4字节对齐
.text : ;指定代码段
{
cpu/arm920t/start.o (.text) ; 代码的第一个代码部分
*(.text) ;其它代码部分
}
. = ALIGN(4)
.rodata : { *(.rodata) } ;指定只读数据段
. = ALIGN(4);
.data : { *(.data) } ;指定读/写数据段
. = ALIGN(4);
.got : { *(.got) } ;指定got段, got段式是uboot自定义的一个段, 非标准段
__u_boot_cmd_start = . ;把__u_boot_cmd_start赋值为当前位置, 即起始位置
.u_boot_cmd : { *(.u_boot_cmd) } ;指定u_boot_cmd段, uboot把所有的uboot命令放在该段.
__u_boot_cmd_end = .;把__u_boot_cmd_end赋值为当前位置,即结束位置
. = ALIGN(4);
__bss_start = .; 把__bss_start赋值为当前位置,即bss段的开始位置
.bss : { *(.bss) }; 指定bss段
_end = .; 把_end赋值为当前位置,即bss段的结束位置
}
88888888**********************************
r与adr的区别
转自:http://coon.blogbus.com/logs/2738861.html
ldr r0, _start
adr r0, _start
ldr r0, =_start
nop
mov pc, lr
_start:
nop
编译的时候设置 RO 为 0x0c008000
↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
0c008000 <_start-0x14>:
c008000: e59f000c ldr r0, [pc, #12] ; c008014 <_start>
c008004: e28f0008 add r0, pc, #8 ; 0x8
c008008: e59f0008 ldr r0, [pc, #8] ; c008018 <_start+0x4>
c00800c: e1a00000 nop (mov r0,r0)
c008010: e1a0f00e mov pc, lr
0c008014 <_start>:
c008014: e1a00000 nop (mov r0,r0)
c008018: 0c008014 stceq 0, cr8, [r0], -#80
分析:
ldr r0, _start
从内存地址 _start 的地方把值读入。执行这个后,r0 = 0xe1a00000
adr r0, _start
取得 _start 的地址到 r0,但是请看反编译的结果,它是与位置无关的。其实取得的时相对的位置。例如这段代码在 0x0c008000 运行,那么 adr r0, _start 得到 r0 = 0x0c008014;如果在地址 0 运行,就是 0x00000014 了。
ldr r0, =_start
这个取得标号 _start 的绝对地址。这个绝对地址是在 link 的时候确定的。看上去这只是一个指令,但是它要占用 2 个 32bit 的空间,一条是指令,另一条是 _start 的数据(因为在编译的时候不能确定 _start 的值,而且也不能用 mov 指令来给 r0 赋一个 32bit 的常量,所以需要多出一个空间存放 _start 的真正数据,在这里就是 0x0c008014)。
因此可以看出,这个是绝对的寻址,不管这段代码在什么地方运行,它的结果都是 r0 = 0x0c008014
posted @
2012-11-19 16:30 yuhen 阅读(2617) |
评论 (1) |
编辑 收藏#include <config.h>
#include <version.h>
#if defined(CONFIG_S3C2410)
#include <s3c2410.h>
#elif defined(CONFIG_S3C2440)//include\configs\smdk2440.h中定义。
#include <s3c2440.h>
#endif
#include <status_led.h>
/*************************************************************************
Jump vector table as in table 3.1 in [1]
*************************************************************************/
//.global声明一个符号可被其它文件引用,相当于声明了一个
//全局变量,.globl与.global相同。
//该部分为处理器的异常处理向量表。地址范围为
//0x0000 0000 ~ 0x0000 0020,刚好8条指令。
//声明全局变量 _start
.globl _start /*系统复位位置,整个程序入口*/
_start: b start_code /*各个异常向量对应的相对跳转代码,0x00*/
/*start_code用b,就是因为start_code在MMU建立前后都有可能发生*/
/*其他的异常只有在MMU建立之后才会发生*/
ldr pc, _undefined_instruction //未定义指令异常,0x04
ldr pc, _software_interrupt //软中断异常,0x08
ldr pc, _prefetch_abort //内存操作异常,0x0c
ldr pc, _data_abort //数据异常,0x10
ldr pc, _not_used //未适用,0x14
ldr pc, _irq //慢速中断异常,0x18
ldr pc, _fiq //快速中断异常,0x1c
//.word伪操作用于分配一段字内存单元(分配的单元都是字对齐的),并
//用伪操作中的expr初始化。.long与.int作用与之相同。
/*.word 表达式 ==> 就是在当前位置放一个word型的值,这个值就是"表达式"
;rWTCON: .word 0x15300000 就是在当前地址,即_rWTCON处放一个值0x15300000*/
_undefined_instruction: .word undefined_instruction
_software_interrupt: .word software_interrupt
_prefetch_abort: .word prefetch_abort
_data_abort: .word data_abort
_not_used: .word not_used
_irq: .word irq
_fiq: .word fiq
/*.balign[wl] abs-expr, abs-expr, abs-expr
;增加位置计数器(在当前子段)使它指向规定的存储边界。
;第一个表达式参数(结果必须是纯粹的数字)是必需参数:边界基准,单位
为字节。
;例如, '.balign 8'向后移动位置计数器直至计数器的值等于8的倍数。
;如果位置计数器已经是8的倍数,则无需移动。
;第2个表达式参数(结果必须是纯粹的数字)给出填充字节的值,用这个值
填充位置计数器越过的地方。
;第2个参数(和逗点)可以省略。如果省略它,填充字节的值通常是0。
;但在某些系统上,如果本段标识为包含代码,而填充值被省略,则使用
no-op指令填充空白区。
;第3个参数的结果也必须是纯粹的数字,这个参数是可选的。如果存在第
3个参数,
;它代表本对齐命令允许跳过字节数的最大值。如果完成这个对齐需要跳
过的字节数比规定的最大值还多,
;则根本无法完成对齐。您可以在边界基准参数后简单地使用两个逗号,
以省略填充值参数(第二参数);
;如果您在想在适当的时候,对齐操作自动使用no-op指令填充
balignw和.balignl是.balign命令的变化形式。.balignw使用2个字节来填充空白区。
.balignl使用4字节来填充。例如,.balignw 4,0x368d将地址对齐到4的倍数,如果它跳
过2个字节,GAS将使用0x368d填充这2个字节(字节的确切存放位置视处理器
的存储方式而定)。
如果它跳过1或3个字节,则填充值不明确。
//它的含义是以16字节边界对齐,为了对齐而越过的地址以字为单位填冲
//值0xdeadbeef。我猜0xdeadbeef可能NOP指令。
.balignl 16,0xdeadbeef //对齐内存为16的倍数
/*************************************************************************
*
* Startup Code (called from the ARM reset exception vector)
*
* do important init only if we don't start from memory!
* relocate armboot to ram
* setup stack
* jump to second stage
*
*************************************************************************/
// TEXT_BASE在开发板相关的目录中的config.mk文件中定义, 它定义了
// 代码在运行时所在的地址, 那么_TEXT_BASE中保存了这个地址
/*
*保存变量的数据区,保存一些全局变量,用于BOOT程序从FLASH拷贝到RAM,或者
其它的使用。
*还有一些变量的长度是通过连接脚本里得到,实际上由编译器算出来的
*/
//TEXT_BASE定义在\board\smdk2410\config.mk中。
/*TEXT_BASE是代码执行的起始地址.编译产生的二进制文件必需下载到该地
址,因为所有的函数,全局变量等等定位都是以这个地址为参照的.
如果uboot中是TEXT_BASE就是设的0x33F80000, 那么必需download到这个地址的ram中才
能正常运行.
*/
_TEXT_BASE: //_TEXT_BASE=TEXT_BASE.
.word TEXT_BASE /*uboot映像在SDRAM中的重定位地址*/
// 标号_start在前面有定义
.globl _armboot_start // /*在_armboot_start标号处,保存了_start的值*/
_armboot_start: //_armboot_start=_start。
.word _start /*_start是程序入口,链接完毕它的值应该是TEXT_BASE*/
/*
* These are defined in the board-specific linker script.
*/
//__bss_start是uboot 的bss段起始地址,那么uboot映像的大小就是__bss_start - _start;
//实际上,_armboot_start并没有实际意义,它只是在"ldr r2, _armboot_start"中用來寻
//址_start的值而已,_bss_start也是一样的道理,真正有意义的应该是_start和
//__bss_start本身。
.globl _bss_start /*__bss_start是uboot 的bss段起始地址,*/
_bss_start: /*uboot映像的大小就是__bss_start - _start*/
.word __bss_start
.globl _bss_end
_bss_end:
.word _end
#ifdef CONFIG_USE_IRQ
/* IRQ stack memory (calculated at run-time) */
.globl IRQ_STACK_START
IRQ_STACK_START:
.word 0x0badc0de
/* IRQ stack memory (calculated at run-time) */
.globl FIQ_STACK_START
FIQ_STACK_START:
.word 0x0badc0de
#endif
/* the actual start code*/
start_code:/*复位启动子程序*/
/*设置cpu运行在SVC32模式。共有7种模式*/
mrs r0,cpsr /*复制当前程序状态寄存器cpsr到r0*/
bic r0,r0,#0x1f //这里使用位清除指令,把中断全部清除,只置位模式控制位
//7种异常,共占0x00 - 0x16空间
/*ORR{条件}{S} <dest>, <op 1>, <op 2>*/
/*OR 将在两个操作数上进行逻辑或,把结果放置到目的寄存器中*/
orr r0,r0,#0xd3 /*选择新模式,(现在设为超级保护模式)*/
msr cpsr,r0 /*设置cpsr为超级保护模式*/
/*通过设置ARM的CPSR寄存器,让CPU运行在操作系统模式,为后面进行其它操作作好准备*/
//如果定义了CONFIG_AT91RM9200DK,CONFIG_AT91RM9200EK,CONFIG_AT91RM9200DF中的任意一个
//,就会执行其中的语句.这里没有用。
#if defined(CONFIG_AT91RM9200DK) || defined(CONFIG_AT91RM9200EK) || defined(CONFIG_AT91RM9200DF)
/* relocate exception table*/
ldr r0, =_start
ldr r1, =0x0
mov r2, #16
copyex:
subs r2, r2, #1
ldr r3, [r0], #4
str r3, [r1], #4
bne copyex
#endif
#if defined(CONFIG_S3C2400) || defined(CONFIG_S3C2410) || defined(CONFIG_S3C2440)
#if defined(CONFIG_S3C2400)
#define pWTCON 0x15300000
#define INTMSK 0x14400008 /* Interupt-Controller base addresses */
#define CLKDIVN 0x14800014 /* clock divisor register */
#elif defined(CONFIG_S3C2410) || defined(CONFIG_S3C2440)
#define pWTCON 0x53000000 /*"看门狗定时器控制寄存器"的地址0x53000000*/
#define INTMSK 0x4A000008 /*"中断屏蔽寄存器"的地址:0x4A000008 */
#define INTSUBMSK 0x4A00001C /*针对INTMAK具体化的一个中断请求屏蔽寄存器,其地
址0x4A00001C */
#define LOCKTIME 0x4c000000 //锁时计数寄存器
#define MPLLCON 0x4c000004 //MPLL寄存器
#define UPLLCON 0x4c000008 //UPLL寄存器
#define CLKDIVN 0x4C000014 /*CPU时钟分频控制寄存器,地址0x4C000014*/
#endif
#if defined(CONFIG_S3C2410)
#define INTSUBMSK_val 0x7ff
#define MPLLCON_val ((0x90 << 12) + (0x7 << 4) + 0x0) /* 202 MHz */
#define UPLLCON_val ((0x78 << 12) + (0x2 << 4) + 0x3)
#define CLKDIVN_val 3 /* FCLK:HCLK:PCLK = 1:2:4 */
#elif defined(CONFIG_S3C2440)
#define INTSUBMSK_val 0xffff //以便屏蔽INTSUBMSK的bit[15:0]对应的中断请求
#if (CONFIG_SYS_CLK_FREQ == 16934400)//晶振=16.9344M在include\configs\smdk2440.h中定义。
/*
Mpll = (2 * m * Fin) / (p * 2s)
m = (MDIV + 8), p = (PDIV + 2), s = SDIV
Upll = (m * Fin) / (p * 2s)
m = (MDIV + 8), p = (PDIV + 2), s = SDIV
MDIV =PLLCON[19:12]; PDIV=PLLCON[9:4]; SDIV=PLLCON[1:0];
*/
//# define MPLLCON_val ((0x61 << 12) + (0x1 << 4) + 0x2) /* 296.35 MHz */
//# define UPLLCON_val ((0x3c << 12) + (0x4 << 4) + 0x2) /* 47.98 MHz */
//MDIV=184 PDIV=2 SDIV=2
#define MPLLCON_val ((184 << 12) + (2 << 4) + 2) /*406M*/
//MDIV=60 PDIV=4 SDIV=2
#define UPLLCON_val ((60 << 12) + (4 << 4) + 2) /* 47M */
#elif (CONFIG_SYS_CLK_FREQ == 12000000)
#define MPLLCON_val ((0x44 << 12) + (0x1 << 4) + 0x1) /* 304.00 MHz */
#define UPLLCON_val ((0x38 << 12) + (0x2 << 4) + 0x2) /* 48.00 MHz */
#endif
#define CLKDIVN_val 7 /* FCLK:HCLK:PCLK = 1:3:6 CLKDIVN=7 */
//CPU : 高速设备: 低速设备
#define CAMDIVN 0x4C000018
#endif
//禁用看门狗
ldr r0, =pWTCON
mov r1, #0x0
str r1, [r0]
/* mask all IRQs by setting all bits in the INTMR - default*/
/*在SVC模式下,屏蔽所有中断发生*/
mov r1, #0xffffffff
ldr r0, =INTMSK
str r1, [r0]
#if defined(CONFIG_S3C2410) || defined(CONFIG_S3C2440)
ldr r1, =INTSUBMSK_val /*子中断同样屏蔽INTSUBMSK_val=0xffff*/
ldr r0, =INTSUBMSK
str r1, [r0]
/*To reduce PLL lock time, adjust the LOCKTIME register. */
ldr r0,=LOCKTIME
ldr r1,=0xffffff
str r1,[r0]
#endif
/* FCLK:HCLK:PCLK = 1:3:6*//* default FCLK is 406M MHz ! */
ldr r0, =CLKDIVN
mov r1, #CLKDIVN_val
str r1, [r0]
#if defined(CONFIG_S3C2440)
/* Make sure we get FCLK:HCLK:PCLK = 1:3:6 */
ldr r0, =CAMDIVN
mov r1, #0
str r1, [r0]
/* Clock asynchronous mode */
mrc p15, 0, r1, c1, c0, 0
orr r1, r1, #0xc0000000
mcr p15, 0, r1, c1, c0, 0
ldr r0,=UPLLCON
ldr r1,=UPLLCON_val
str r1,[r0]
nop
nop
nop
nop
nop
nop
nop
nop
ldr r0,=MPLLCON
ldr r1,=MPLLCON_val
str r1,[r0]
//
#define GPJCON 0x560000D0
#define GPJDAT 0x560000D4
#define GPJUP 0x560000D8
/*
LDR R0, = GPJCON
LDR R1, = 0x15555
STR R1, [R0]
LDR R0, = GPJUP
LDR R1, = 0x1f
STR R1, [R0]
LDR R0, = GPJDAT
// LDR R1, = 0xffff
LDR R1, = 0x00
STR R1, [R0]
*/
#endif
#endif /* CONFIG_S3C2400 || CONFIG_S3C2410 */
/*
* we do sys-critical inits only at reboot,
* not when booting from ram!
*/
//bl LED_FLASH
#ifndef CONFIG_SKIP_LOWLEVEL_INIT
/*这些初始化代码在系统重启的时候执行,运行时热复位从RAM中启动不执行*/
bl cpu_init_crit
#endif
#if 1
LDR R0, = GPJCON
LDR R1, = 0x15555
STR R1, [R0]
LDR R0, = GPJUP
LDR R1, = 0x1f
STR R1, [R0]
LDR R0, = GPJDAT
LDR R1, = 0x00
STR R1, [R0]
#endif
#if defined(CONFIG_AT91RM9200) || defined(CONFIG_S3C2410) || defined(CONFIG_S3C2440)
#ifndef CONFIG_SKIP_RELOCATE_UBOOT
#ifndef CONFIG_S3C2410_NAND_BOOT
//NOR_BOOT :
relocate: /* 把U-BOOT重新定位到RAM*/
//r0=0;
adr r0, _start /* r0是代码的当前位置*/
//r1=TEXT_BASE = 0x33F80000
ldr r1, _TEXT_BASE /*测试判断是从FLASH启动,还是RAM */
cmp r0, r1 /*比较R0、R1,调试的时候不需要重定位。 */
beq stack_setup /*如果R0等于R1,跳到重定位代码。*/
//如果不是从RAM运行的话,则将代码拷贝到_TEXT_BASE标识的RAM中。
/*准备重新定义代码。*/
ldr r2, _armboot_start//_armboot_start=_start
ldr r3, _bss_start //
sub r2, r3, r2 /* r2得到armboot的大小*/
add r2, r0, r2 /* r2得到要复制代码的末尾地址*/
//kaobei guo cheng
copy_loop:/*重新定位代码*/
ldmia r0!, {r3-r10} /*从源地址[r0]复制,r0指向_start(=0)*/
stmia r1!, {r3-r10} /*复制到目的地址[r1],r1指向_TEXT_BASE(=0x33F80000)*/
cmp r0, r2 /* 复制数据块直到源数据末尾地址[r2]*/
ble copy_loop
#else /* NAND_BOOT */
//relocate:
copy_myself:
/* mov r10, lr */
#if defined(CONFIG_S3C2410)
@ reset NAND
mov r1, #S3C2410_NAND_BASE
ldr r2, =0xf842 @ initial value enable tacls=3,rph0=6,rph1=0
str r2, [r1, #oNFCONF]
ldr r2, [r1, #oNFCONF]
bic r2, r2, #0x800 @ enable chip
str r2, [r1, #oNFCONF]
mov r2, #0xff @ RESET command
strb r2, [r1, #oNFCMD]
mov r3, #0 @ wait
1: add r3, r3, #0x1
cmp r3, #0xa
blt 1b
2: ldr r2, [r1, #oNFSTAT] @ wait ready
tst r2, #0x1
beq 2b
ldr r2, [r1, #oNFCONF]
orr r2, r2, #0x800 @ disable chip
str r2, [r1, #oNFCONF]
#elif defined(CONFIG_S3C2440)
/*从NAND闪存中把U-BOOT拷贝到RAM*/
mov r1, #S3C2440_NAND_BASE //S3C2440_NAND_BASE=0x4E000000
ldr r2, =0xfff0 @ initial value tacls=3,rph0=7,rph1=7
ldr r3, [r1, #oNFCONF] //oNFCONF=0x00
orr r3, r3, r2
str r3, [r1, #oNFCONF]//oNFCONF=0x00
ldr r3, [r1, #oNFCONT] //oNFCONT=0x04
orr r3, r3, #1 @ enable nand controller
str r3, [r1, #oNFCONT]//oNFCONT=0x04
#endif //if defined(CONFIG_S3C2410)
#if 0
@ get ready to call C functions (for nand_read())
ldr sp, DW_STACK_START @ setup stack pointer
mov fp, #0 @ no previous frame, so fp=0
#else
ldr r0, _TEXT_BASE /* upper 128 KiB: relocated uboot */
/* CFG_MALLOC_LEN=(CFG_ENV_SIZE + 2048*1024) =0x210000 ; CFG_ENV_SIZE = 0x10000
CFG_GBL_DATA_SIZE=128 */
sub r0, r0, #CFG_MALLOC_LEN /* malloc area */
sub r0, r0, #CFG_GBL_DATA_SIZE /* bdinfo */
#ifdef CONFIG_USE_IRQ /*include/configs/smdk2440.h*/
sub r0, r0, #(CONFIG_STACKSIZE_IRQ+CONFIG_STACKSIZE_FIQ) //8K+4K
#endif
sub sp, r0, #12 /* leave 3 words for abort-stack */
#endif //#if 0
@ copy u-boot to RAM
ldr r0, _TEXT_BASE //置第1个参数: UBOOT在RAM中的起始地址
mov r1, #0x0 //设置第2个参数:NAND闪存的起始地址
//CFG_UBOOT_SIZE=0x40000=256k
mov r2, #CFG_UBOOT_SIZE // 设置第3个参数: U-BOOT的长度(256KB)
bl nand_read_ll //调用nand_read_whole(),把NAND闪存中的数据读入到RAM中
tst r0, #0x0 // 如果函数的返回值为0,表示执行成功
beq ok_nand_read //执行内存比较,把RAM中的前4K内容与NAND闪存中的前4K内容进行比较, 如果完全相同, 则表示搬移成功
#ifdef CONFIG_DEBUG_LL
bad_nand_read:
ldr r0, STR_FAIL
ldr r1, SerBase
bl PrintWord
1: b 1b @ infinite loop
#endif
ok_nand_read:
#ifdef CONFIG_DEBUG_LL
ldr r0, STR_OK
ldr r1, SerBase
bl PrintWord
#endif
@ verify
mov r0, #0
@ldr r1, =0x33f00000
ldr r1, _TEXT_BASE
mov r2, #0x400 @ 4 bytes * 1024 = 4K-bytes
go_next:
ldr r3, [r0], #4
ldr r4, [r1], #4
teq r3, r4
bne notmatch
subs r2, r2, #4
beq done_nand_read
bne go_next
notmatch:
#ifdef CONFIG_DEBUG_LL
sub r0, r0, #4
ldr r1, SerBase
bl PrintHexWord
ldr r0, STR_FAIL
ldr r1, SerBase
bl PrintWord
#endif
#if 1
LDR R0, = GPJDAT
LDR R1, = 0x4
STR R1, [R0]
#endif
1: b 1b
done_nand_read:
#if 1
LDR R0, = GPJDAT
LDR R1, = 0x2
STR R1, [R0]
#endif
#endif /* NAND_BOOT */
#endif /* CONFIG_SKIP_RELOCATE_UBOOT */
#endif
/* 初始化堆栈*/
stack_setup:
ldr r0, _TEXT_BASE /*上面是128kib重定位的u-boot*/
/*在smdk244.h中定义 #define CFG_MALLOC_LEN (CFG_ENV_SIZE + 2048*1024)
#define CFG_ENV_SIZE 0x10000
#define CFG_GBL_DATA_SIZE 128 */
sub r0, r0, #CFG_MALLOC_LEN /*向下是内存分配空间*/
sub r0, r0, #CFG_GBL_DATA_SIZE /*然后是bdinfo结构体地址空间*/
#ifdef CONFIG_USE_IRQ //在 smdk2440.h中定义。
/*在smdk244.h中定义#define CONFIG_STACKSIZE_IRQ (8*1024)
#define CONFIG_STACKSIZE_FIQ (4*1024) */
sub r0, r0, #(CONFIG_STACKSIZE_IRQ+CONFIG_STACKSIZE_FIQ)
#endif
sub sp, r0, #12 /*为 abort-stack 预留3个字,得到最终sp指针初始值*/
clear_bss:
ldr r0, _bss_start /*找到bss 段起始地址。*/
ldr r1, _bss_end /* bss 段末尾地址。*/
mov r2, #0x00000000 /* 清零。*/
clbss_l:str r2, [r0] /*bss 段地址空间清零循环。。。*/
add r0, r0, #4
cmp r0, r1
ble clbss_l
#if 1
LDR R0, = GPJDAT
LDR R1, = 0x1
STR R1, [R0]
#endif
/*跳转到start_armboot函数入口,_start_armboot字保存函数入口指针*/
ldr pc, _start_armboot
//_start_armboot=start_armboot
//pc=start_armboot;
//去执行void start_armboot (void),在lib_arm/boarb.c中。
_start_armboot: .word start_armboot
/*
*************************************************************************
*
* CPU_init_critical registers
*
* setup important registers
* setup memory timing
*
*************************************************************************
*/
//功能:设置CP15寄存器 这里完成的功能:失效Icache和Dcache,禁能MMU和cache
#ifndef CONFIG_SKIP_LOWLEVEL_INIT
//关键的初始化子程序。
cpu_init_crit:
/* flush v4 I/D caches | 失效指令cache和数据cache */
mov r0, #0
//使I/D cache失效:将寄存器r0的数据传送到协处理器p15的c7中。C7寄存器
//位对应cp15中的cache控制寄存器
mcr p15, 0, r0, c7, c7, 0 /* flush v3/v4 cache */
//使TLB操作寄存器失效:将r0数据送到cp15的c8、c7中。C8对应TLB操作
//寄存器
mcr p15, 0, r0, c8, c7, 0 /* flush v4 TLB */
/*
* disable MMU stuff and caches
*/
/* disable MMU stuff and caches | 禁能MMU和cache */
mrc p15, 0, r0, c1, c0, 0 //先把c1和c0寄存器的各位置0(r0 = 0)
bic r0, r0, #0x00002300 @ clear bits 13, 9:8 (--V- --RS)
bic r0, r0, #0x00000087 @ clear bits 7, 2:0 (B--- -CAM)
orr r0, r0, #0x00000002 @ set bit 2 (A) Align
orr r0, r0, #0x00001000 @ set bit 12 (I) I-Cache
mcr p15, 0, r0, c1, c0, 0
/*
* before relocating, we have to setup RAM timing
* because memory timing is board-dependend, you will
* find a lowlevel_init.S in your board directory.
*/
mov ip, lr
#if defined(CONFIG_AT91RM9200DK) || defined(CONFIG_AT91RM9200EK) || defined(CONFIG_AT91RM9200DF)
#else
bl lowlevel_init //位于board/smdk2440/lowlevel_init.S:用于完成芯片存储器的初始化,
//执行完成后返回
#endif
mov lr, ip
mov pc, lr
#endif /* CONFIG_SKIP_LOWLEVEL_INIT */
/*
*************************************************************************
*
* Interrupt handling
*
*************************************************************************
*/
@
@ IRQ stack frame.
@
#define S_FRAME_SIZE 72
#define S_OLD_R0 68
#define S_PSR 64
#define S_PC 60
#define S_LR 56
#define S_SP 52
#define S_IP 48
#define S_FP 44
#define S_R10 40
#define S_R9 36
#define S_R8 32
#define S_R7 28
#define S_R6 24
#define S_R5 20
#define S_R4 16
#define S_R3 12
#define S_R2 8
#define S_R1 4
#define S_R0 0
#define MODE_SVC 0x13
#define I_BIT 0x80
/*
* use bad_save_user_regs for abort/prefetch/undef/swi ...
* use irq_save_user_regs / irq_restore_user_regs for IRQ/FIQ handling
*/
.macro bad_save_user_regs
sub sp, sp, #S_FRAME_SIZE
stmia sp, {r0 - r12} @ Calling r0-r12
ldr r2, _armboot_start
sub r2, r2, #(CONFIG_STACKSIZE+CFG_MALLOC_LEN)
sub r2, r2, #(CFG_GBL_DATA_SIZE+8) @ set base 2 words into abort stack
ldmia r2, {r2 - r3} @ get pc, cpsr
add r0, sp, #S_FRAME_SIZE @ restore sp_SVC
add r5, sp, #S_SP
mov r1, lr
stmia r5, {r0 - r3} @ save sp_SVC, lr_SVC, pc, cpsr
mov r0, sp
.endm
.macro irq_save_user_regs
sub sp, sp, #S_FRAME_SIZE
stmia sp, {r0 - r12} @ Calling r0-r12
add r8, sp, #S_PC
stmdb r8, {sp, lr}^ @ Calling SP, LR
str lr, [r8, #0] @ Save calling PC
mrs r6, spsr
str r6, [r8, #4] @ Save CPSR
str r0, [r8, #8] @ Save OLD_R0
mov r0, sp
.endm
.macro irq_restore_user_regs
ldmia sp, {r0 - lr}^ @ Calling r0 - lr
mov r0, r0
ldr lr, [sp, #S_PC] @ Get PC
add sp, sp, #S_FRAME_SIZE
subs pc, lr, #4 @ return & move spsr_svc into cpsr
.endm
.macro get_bad_stack
ldr r13, _armboot_start @ setup our mode stack
sub r13, r13, #(CONFIG_STACKSIZE+CFG_MALLOC_LEN)
sub r13, r13, #(CFG_GBL_DATA_SIZE+8) @ reserved a couple spots in abort stack
str lr, [r13] @ save caller lr / spsr
mrs lr, spsr
str lr, [r13, #4]
mov r13, #MODE_SVC @ prepare SVC-Mode
@ msr spsr_c, r13
msr spsr, r13
mov lr, pc
movs pc, lr
.endm
.macro get_irq_stack @ setup IRQ stack
ldr sp, IRQ_STACK_START
.endm
.macro get_fiq_stack @ setup FIQ stack
ldr sp, FIQ_STACK_START
.endm
/*
* exception handlers
*/
.align 5
undefined_instruction:
get_bad_stack
bad_save_user_regs
bl do_undefined_instruction
.align 5
software_interrupt:
get_bad_stack
bad_save_user_regs
bl do_software_interrupt
.align 5
prefetch_abort:
get_bad_stack
bad_save_user_regs
bl do_prefetch_abort
.align 5
data_abort:
get_bad_stack
bad_save_user_regs
bl do_data_abort
.align 5
not_used:
get_bad_stack
bad_save_user_regs
bl do_not_used
#ifdef CONFIG_USE_IRQ
.align 5
irq:
get_irq_stack
irq_save_user_regs
bl do_irq
irq_restore_user_regs
.align 5
fiq:
get_fiq_stack
/* someone ought to write a more effiction fiq_save_user_regs */
irq_save_user_regs
bl do_fiq
irq_restore_user_regs
#else
.align 5
irq:
get_bad_stack
bad_save_user_regs
bl do_irq
.align 5
fiq:
get_bad_stack
bad_save_user_regs
bl do_fiq
#endif
posted @
2012-10-30 16:49 yuhen 阅读(602) |
评论 (0) |
编辑 收藏最近遇到一个设置系统sleep状态的case,最后从客户那里得到了设置方法~就是用Powercfg 命令
powercfg -energy
顺便找了一些powercfg的其他命令行选项在下面:
powercfg [-l] [-q ] [-x] [-changename] [-duplicatescheme] [-d] [-deletesetting] [-setactive] [-getactivescheme] [-setacvalueindex] [-setdcvalueindex] [-h] [-a] [-devicequery] [-deviceenablewake] [-devicedisablewake] [-import] [-export] [-lastwake] [-?][-aliases] [-setsecuritydescriptor] [-getsecuritydescriptor]
| 选项 |
描述 |
|
-list
-l |
列出当前用户环境中的所有电源方案。
例如:
powercfg -list |
|
-query [Scheme_GUID] [Sub_GUID]
-q [Scheme_GUID] [Sub_GUID] |
显示指定的电源方案的内容。
用法:
powercfg -query [Scheme_GUID] [Sub_GUID]
SCHEME_GUID
(可选)指定要显示的电源方案的 GUID。可以使用 powercfg -l 命令获取。
SUB_GUID
(可选)指定要显示的子组的 GUID。要求提供 SCHEME_GUID。
如果未提供 SCHEME_GUID 和 SUB_GUID,则显示当前用户的活动电源方案的设置。
如果未指定 SUB_GUID,则显示指定电源方案中的所有设置。 |
|
-changesettingvalue
-xsetting value |
修改当前电源方案中的设置值。
用法:
powercfg-xsetting value
设置
指定以下设置之一:
-monitor-timeout-ac分钟
-monitor-timeout-dc分钟
-disk-timeout-ac分钟
-disk-timeout-dc分钟
-standby-timeout-acminutes
-standby-timeout-dc分钟
-hibernate-timeout-ac分钟
-hibernate-timeout-dc分钟
值
指定值,以分钟为单位。
例如:
powercfg-change-monitor-timeout-ac5
这将监视器使用交流电源时的空闲超时值设置为五分钟。 |
|
-changenameGUID name [scheme_description] |
修改电源方案的名称,也可以修改方案描述。
用法:
powercfg-changenameGUID namescheme_description
GUID
指定电源方案的 GUID
名称
指定电源方案的名称。
scheme_description
描述电源方案。
如果忽略描述,将仅更改名称。 |
|
-duplicateschemeGUID [DestinationGUID] |
复制指定的电源方案。将显示产生的 GUID(表示新方案)。
用法:
powercfg-duplicateschemeGUID [DestinationGUID]
GUID
指定方案 GUID。通过使用 powercfg-l 命令获取。
DestinationGUID
指定将在其中复制方案的 GUID。
如果省略 DestinationGUID,则将为重复方案创建新 GUID。 |
|
-deleteGUID
-dGUID |
删除带有指定 GUID 的电源方案。
用法:
Powercfg-deleteGUID
GUID
指定方案的 GUID。使用 -list 选项获取。 |
|
-deletesettingSub_GUID Setting_GUID |
删除电源设置。
用法:
powercfg-deletesettingSub_GUID Setting_GUID
Sub_GUID
指定子组 GUID。
Setting_GUID
指定电源设置 GUID。 |
|
-setactiveScheme_GUID
-s Scheme_GUID |
使计算机上指定的电源方案成为活动的方案。
用法:
Powercfg-setactiveScheme_GUID
Scheme_GUID
指定方案 GUID。 |
|
-getactivescheme |
检索当前活动的电源方案。
用法:
Powercfg-getactivescheme |
|
-setacvalueindexScheme_GUID Sub_GUID Setting_GUID SettingIndex |
设置在计算机使用交流电源供电时与指定电源设置相关联的值。
用法:
powercfg-setacvalueindexScheme_GUIDSub_GUIDSetting_GUIDSettingIndex
Scheme_GUID
指定电源方案 GUID。使用 -l 选项获取。
Sub_GUID
指定电源设置 GUID 的子组。使用 -q 选项获取。
Setting_GUID
指定单个电源设置 GUID。通过使用 -q 选项获取。
SettingIndex
指定此电源设置将会设置为可能值列表中的哪个。
例如:
powercfg-setacvalueindexScheme_GUID Sub_GUID Setting_GUID 5
这会将电源设置的交流电源值设置为此电源设置可能值列表中的第五项。 |
|
-setdcvalueindexScheme_GUID Sub_GUID Setting_GUID SettingIndex |
设置在计算机使用直流电源供电时与指定电源设置相关联的值。
用法:
powercfg-setdcvalueindexScheme_GUID Sub_GUID Setting_GUID SettingIndex
Scheme_GUID
指定电源方案 GUID。通过使用 -l 选项获取。
Sub_GUID
指定电源设置 GUID 的子组。通过使用 -q 选项获取。
Setting_GUID
指定单个电源设置 GUID。通过使用 -q 选项获取。
SettingIndex
指定此电源设置将设置为可能值的列表中的哪一个。
例如:
powercfg-setdcvalueindexScheme_GUID Sub_GUID Setting_GUID 5
这会将电源设置的直流电源值设置为此电源设置可能值列表中的第五项。 |
|
-hibernate [on|off]
-h [on|off] |
启用或禁用休眠功能。所有计算机上均不支持休眠超时。
例如:powercfg-h on |
|
-availablesleepstates
-a |
报告计算机上可用的睡眠状态。尝试报告睡眠状态不可用的原因。 |
|
-devicequeryquery_flags |
返回符合指定条件的设备。
用法:
powercfg-devicequeryquery_flags
query_flags
指定以下条件之一:
wake_from_S1_supported - 返回支持将计算机从轻度睡眠状态中唤醒的所有设备。
例如:
powercfg -devicequery wake_armed |
|
-deviceenablewakedevicename |
使设备可以将计算机从睡眠状态中唤醒。
用法:
powercfg-deviceenablewakedevicename
devicename
指定通过使用 powercfg-devicequerywake_programmable 命令检索的设备。
例如:
powercfg-deviceenablewake"Microsoft USB IntelliMouse Explorer" |
|
-devicedisablewakedevicename |
使设备不能将计算机从睡眠状态中唤醒。
用法:
powercfg-devicedisablewakedevicename
devicename
指定通过使用 powercfg-devicequerywake_armed 命令检索的设备。 |
|
-import filename [GUID] |
从指定的文件导入所有电源设置。
用法:
powercfg-importfilename [GUID]
filename
指定通过使用 powercfg-export 选项生成的文件的完全限定路径。
GUID
(可选)表示加载到电源方案的设置。如果未提供,则 Powercfg 将生成并使用新的 GUID
例如:
powercfg-importc:\scheme.pow |
|
-export filename GUID |
将指定 GUID 表示的电源方案导出到指定文件。
用法:
powercfg -export filename GUID
filename
指定目标文件的完全限定路径。
GUID
指定电源方案 GUID。使用 -/l 选项获取。
例如:
powercfg -export c:\scheme.pow 381b4222-f694-41f0-9685-ff5bb260df2e |
|
-lastwake |
报告有关将计算机从最后一个睡眠转换中唤醒的事件的信息。 |
|
-help
-? |
显示有关 Powercfg 命令行选项的信息。 |
|
-aliases |
显示所有别名及其相应的 GUID。用户可能在命令提示符处使用这些别名来代替任意 GUID |
|
-setsecruitydescriptor [GUID|Action] SDDL |
设置与指定的电源设置、电源方案或操作相关联的安全描述符。
用法:
powercfg -setsecuritydescriptor [GUID|Action] SDDL
GUID
指定电源方案或电源设置 GUID。
Action
指定以下字符串之一:ActionSetActive、ActionCreate、ActionDefault
SDDL
指定 SDD 格式的有效的安全描述符字符串。调用 powercfg -getsecuritydescriptor 来查看示例 SDDL STRING。 |
|
-getsecuritydescriptor [GUID|Action] |
获取与指定的电源设置、电源方案或操作相关联的安全描述符。
用法:
powercfg -getsecuritydescriptor [GUID|Action]
GUID
指定电源方案或电源设置 GUID。
Action
指定以下一个字符串:ActionSetActive、ActionCreate、ActionDefault |
posted @
2012-06-05 15:27 yuhen 阅读(1492) |
评论 (2) |
编辑 收藏ACPI BIOS implementations that directly access certain system hardware resources from AML code cannot be synchronized with operating system access to the same resources, which can cause the operating system to become unstable or to stop responding. This article describes issues related to BIOS AML firmware accessing system board resources, and the changes implemented to address these issues in the Windows XP, Windows Server 2003, and future versions of the operating system.
Introduction
During the development of the Windows XP operating system, Microsoft discovered many ACPI BIOS implementations that directly access and attempt to manipulate system hardware resources from BIOS ASL code. At run time, system board resources must not be simultaneously accessed or modified by both the BIOS and the operating system, because these accesses cannot be synchronized with operating system access to the same system resources. As a result, BIOS read or write access to these resources can cause adverse effects, ranging from general instability to causing the system to stop responding.
Historically, error conditions of this nature might have been construed by the operating system as an unrecoverable error, resulting in a stop error (blue screen) and system shutdown. In an effort to improve the end user experience and increase system reliability, Windows XP has been re-designed as described in this article.
Changes in Windows XP
While developing and testing Windows XP a list of system board resources was identified that, when accessed from BIOS AML code, proved to be the most problematic. This article refers to the list of addresses associated with these resources as the "blocked ports list." Table 1 lists affected system resources and their associated I/O addresses.
The ACPI AML interpreter in the Windows XP kernel monitors all attempts by BIOS AML code to read from or write to the specific addresses on the blocked ports list. When a read or write access is detected at any of these addresses, the following actions will occur:
| • |
An error will be added to the system event log stating that the ACPI AML interpreter has detected an illegal read or write, and that this read or write has been blocked.
|
| • |
For BIOS AML code that indicates compatibility with the Windows XP ACPI implementation, the operating system will block all read and write accesses to these addresses. This compatibility is determined by the AML code calling the _OSI method, as described later in this article.
|
| • |
For BIOS AML code that is compatible with versions of Windows released before Windows XP, the operating system will allow the read or write access to succeed in most cases, but will still add an error to the system event log.
|
| • |
Accesses to the Programmable Interrupt Controller (PIC) and cascaded PIC, and to PIC Edge/Level Control Registers, are always blocked because BIOS access to these ports is potentially catastrophic and might prevent the system from running. These I/O addresses are noted in Table 1.
|
Windows XP BIOS Compatibility Determined Using _OSI
The specific actions taken by the operating system when read or write accesses to these resources are detected depends on the version of ACPI interface that the BIOS indicates it supports. This is determined through the BIOS use of the _OSI method as described in this article.
For complete details about the _OSI method, see How to Identify Windows Versions in ACPI Using _OSI.
The _OSI method is being introduced with the Windows XP operating system. BIOS ASL code can test for the level of features supported in the current Windows operating system by passing a string to the _OSI method. The operating system returns TRUE for any string that represents a feature set that it can support. Windows XP, for example, returns TRUE for the string "Windows 2001".
By passing the string "Windows 2001" into the _OSI method, the BIOS indicates to the operating system that the BIOS is aware of and compatible with the ACPI implementation and feature set of Windows XP. Windows XP will then reject all I/O reads or writes from BIOS ASL code to addresses on the blocked ports list and generate an error in the system event log.
Windows XP and Legacy BIOS ASL Implementations
For those BIOS implementations that are compatible with versions of Windows released before Windows XP, the operating system will allow the read or write access to succeed in most cases. Accesses to the PIC and cascaded PIC, and to the PIC Edge/Level Control Registers, are always blocked. In all cases an error will be written to the system event log.
To help ensure system stability on systems with legacy BIOS ASL implementations, Windows XP attempts to synchronize accesses to resources whenever possible. For example:
| • |
When a read or write access is detected to the CMOS/RTC index and data pair registers at I/O addresses 0x70 and 0x71, the operating system does the following:
| • |
Disables interrupts
|
| • |
Preserves the contents of the index (address) register
|
| • |
Allows the ASL code access to proceed
|
| • |
Restores the value of the index register
|
This process helps prevent a race condition in which the operating system writes the desired address to the index register and a BIOS method changes the address in the index register before the operating system can access the intended data register, causing the operating system to use the wrong index value.
Note: This approach cannot guarantee that the CMOS address register (0x70) will not be corrupted on multi-processor systems.
|
| • |
ASL code that attempts to access the PCI Configuration Space registers at 0xCF8 0xD00 is re-routed by the kernel AML interpreter to call HalGetBusDataByOffset, which allows access to system resources to be properly synchronized.
|
Accessing BIOS Non-volatile Memory (CMOS NVRAM)
With these changes in Windows XP, BIOS developers may be looking for alternative methods to access CMOS NVRAM. The following examples present some possible solutions.
Reading from CMOS NVRAM
This example ASL code defines an operation region in the system memory address space. During POST, BIOS code copies the data from CMOS to this memory area. ASL code can then use fields to read the CMOS data.
Each CMnn field in the example corresponds to 8 bits of CMOS. The BIOS engineer is responsible for defining these fields appropriately. Each field of this memory can be any combination of bits.
During system boot, BIOS POST code should update this memory area with the value written in the CMOS before handing off to the operating system. Once the operating system has switched to ACPI mode, any attempt to read CMOS from ASL code should be done by reading from these memory locations and not from CMOS NVRAM I/O ports.
// Declare a memory operation region for 255 bytes of CMOS.
// First 0 to 127 bytes reflects CMOS access from IO ports 0x70
// and 0x71 and the subsequent bytes reflect CMOS access from IO
// ports 0x72 to 0x73. BIOS code should properly set up the base
// address of the beginning of this memory range at offset during
// BIOS POST.
OperationRegion (CMRM, SystemMemory, offset, 255) //Operation Region
Field (CMRM, AnyAcc, NoLock, Preserve) { //Field
// Memory corresponding to addresses 0x70, 0x71
CM00, 8,
CM01, 8,
CM02, 8,
.
.
CM7f, 8,
// Memory corresponding to addresses 0x72, 0x73
CM80, 8,
.
.
CMFF
} // End of CMOS field
The following is an example of ASL code which reads from CMOS offset 52 bits 4 to 7 and returns the value read.
// This example returns bits 4 to 7 of CMOS offset 52
Method (RDCM) {
ShiftRight (CM52, 4, Local0)
Return (Local0)
}
Writing to CMOS NVRAM
BIOS code should write to CMOS NVRAM by generating a system management interrupt (SMI). AML code can generate a SMI by writing a specific value to the SMI command port. AML code can pass the CMOS offset and value to be written through the NVRAM memory operation region. The BIOS SMI handles the writes to CMOS, and also updates the memory area pointed by the CMRM operation region to reflect the correct CMOS contents.
Affected System Resources and Addresses
Table 1 lists the system resources and associated I/O addresses that should not be directly accessed by BIOS AML code (the "blocked ports" list).
Table 1 Blocked I/O Port Addresses and System Board Resources
|
0x000 0x00F
|
DMA Controller 1
|
|
|
0x020 0x021
|
Programmable Interrupt Controller
|
Access is never allowed*
|
|
0x040 0x043
|
System Timer 1
|
|
|
0x048 0x04B
|
Timer 2 Failsafe
|
|
|
0x070 0x071
|
System CMOS, RTC
|
|
|
0x074 0x076
|
Extended CMOS
|
|
|
0x081 0x083
|
DMA1 Page Registers
|
|
|
0x087
|
DMA1 CH0 Low Page
|
|
|
0x089
|
DMA2 CH2 Low Page
|
|
|
0x08A 0x08B
|
DMA2 CH3 Low Page,
|
|
|
0x08F
|
DMA2 Low Page Refresh
|
|
|
0x090 0x091
|
Arbitration Control Port Card Select Feedback
|
|
|
0x093 0x094
|
Reserved System Board Setup
|
|
|
0x096 0x097
|
POS Channel Select
|
|
|
0x0A0 0x0A1
|
Cascaded Programmable Interrupt Controller
|
Access is never allowed*
|
|
0x0C0 0x0DF
|
ISA DMA
|
|
|
0x4D0 0x4D1
|
PIC Edge/Level Control Registers
|
Access is never allowed*
|
|
0xCF8 0xD00
|
PCI Configuration Space Access
|
|
*Read or write accesses to these ports are always blocked, regardless of the BIOS use of the _OSI method.
Call to Action
BIOS developers should design their BIOS code according to the guidelines in this article:
| • |
BIOS code that is compatible with Windows XP should access system resources as described in this article; they should not directly read from or write to any of the I/O port addresses listed in Table 1.
|
| • |
BIOS code that is compatible with earlier versions of Windows released before Windows XP should not directly access the PIC and cascaded PIC, or PIC Edge/Level Control Registers.
|
| • |
BIOS code should report compatibility with Windows XP as described in How to Identify Windows Versions in ACPI Using _OSI.
|
posted @
2009-12-31 14:54 yuhen 阅读(938) |
评论 (1) |
编辑 收藏 如果EFI支持64-bit的话,那么就可以启动Windows 7, 还不是因为MS不好好支持32-bit,这样就不需要CSM module了
那么如果EFI支持64-bit的话,SMM driver也就变成64-bit了,这个时候SMM就必须从Real mode 转成64-bit protect mode,其实主要的问题就是CPU的mode是IA-32e mode,这是由CPU的一个寄存器来决定的,具体的就是MSR(C0000080h)的bit8,所以在SMI handler中就需要load 64-bit的GDT,然后切成保护模式之前,设置CPU的这个寄存器,使之变成64-bit,其他的和32-bit的一模一样,就可以去执行64-bit的C程序了
需要强调的是,64-bit汇编code中,eax就用rax了,等等。
贴一张图吧,说明一下CPU的不同模式:
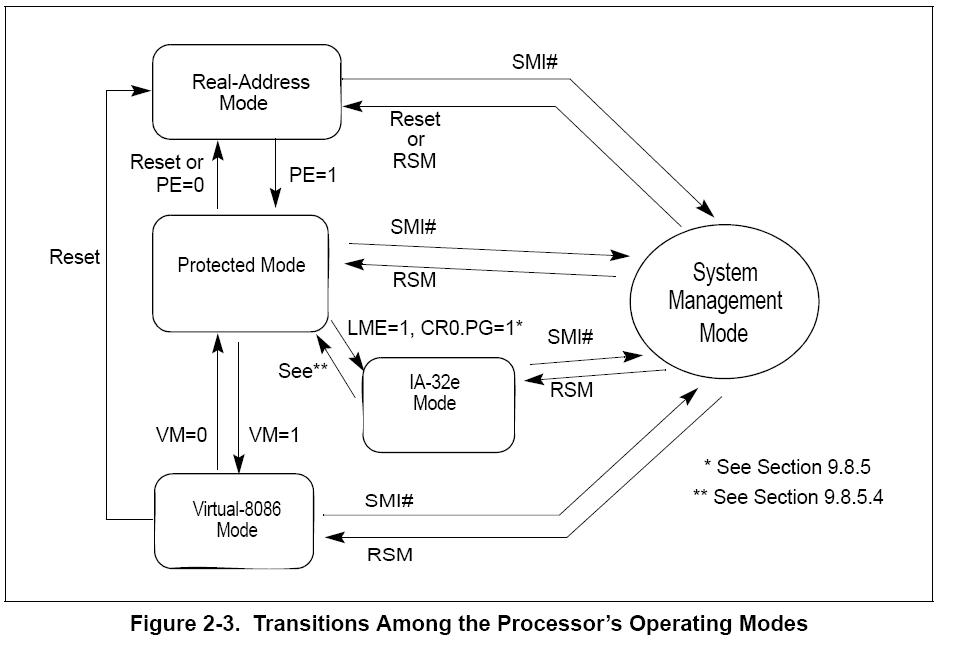
posted @
2009-11-09 18:26 yuhen 阅读(1250) |
评论 (1) |
编辑 收藏 ACPI Table是BIOS提供给OSPM的硬件配置数据,包括系统硬件的电源管理和配置管理,ACPI Table有很多表,根据存储的位置,可以分为:
1) RSDP位于F段,用于OSPM搜索ACPI Table,RSDP可以定位其他所有ACPI Table
2) FACS位于ACPI NVS内存,用于系统进行S3保存的恢复指针,内存为NV Store
3) 剩下所有ACPI Table都位于ACPI Reclaim内存,进入OS后,内存可以释放
ACPI Table根据版本又分为1.0B,2.0,3.0,4.0。2.0以后,支持了64-bit的地址空间,因此几个重要的Table会不大一样,比如:RSDP,RSDT,FADT,FACS。简单的列举一下不同版本的ACPI Table:
1) ACPI 1.0B:RSDP1,RSDT,FADT1,FACS1,DSDT,MADT,SSDT,HPET,MCFG等
2) ACPI 3.0 :RSDP3,RSDT,XSDT,FADT3,FACS3,DSDT,MADT,HPET,MCFG,SSDT等
以系统支持ACPI3.0为例子,说明系统中ACPI table之间的关系如图:
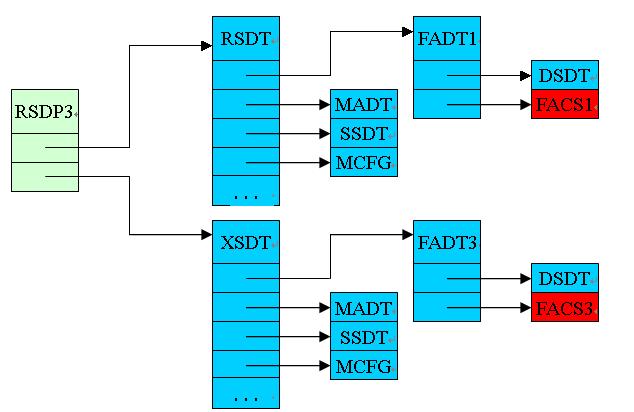
其中绿色代表在内存F段,蓝色是ACPI Reclaim内存,红色是NV store内存
posted @
2009-10-21 16:04 yuhen 阅读(10633) |
评论 (2) |
编辑 收藏 当我们在coding的时候,使用两个变量相加的情况,或者用 +,或者用 | ,都是没有问题,比如:
0x1000 + 0x55 = 0x1055
0x1000 | 0x55 = 0x1055
介于以前这种固有的思维,因此没有把其中不同仔细考虑,直到这几天的bug,才恍然大悟,还是因为基础知识的不扎实和习惯性的思维导致这个bug,不过也给我了一个机会,彻底的搞清楚这两个运算符在变量相加的时候的区别。
因为code是这么定义的:
#define PCI_ADDR(bus,device,func,reg) (UINT64)(bus<<24 + device<<16 + func<<8 + reg ) & 0x00000000FFFFFFFF
#define DRAM_PCI PCI_ADDR(0,0,3,0)
UINT64 Addr;
假如我要访问寄存器0x55
(1) Addr = DRAM_PCI + 0x55;
(2) Addr = DRAM_PCI | 0x55;
那么请问(1)和(2)相等吗?
答案是: (1) Addr = 0;
(2) Addr = RealValue;
那么为什么在(1)中,Addr = 0呢,问题还是出在PCI_ADDR这个宏定义上:
因为宏定义最后做了一个与运算,所以在之后的运算中就需要和 + 或者 | 进行优先级的比较,由于+ 》 & 》 | ,因此当使用 | 的时候,就不会出现问题,能够和我们想要的运算一致;当使用 + 的时候,由于 + 比 & 优先级高,因此就率先计算了 0x00000000FFFFFFFF + 0x55,导致得到了新值 0x0000000100000054,然后和之前的数值进行 &, 不就得到了 0 嘛
所以得到的经验教训:
1)在复杂的定义面前不能想当然的去使用自己认为没有问题的运算符,因为检查这个问题可不是这么容易找到根源的。
2)在进行宏定义的时候最好给整个宏加上括号,那么就可以避免很多优先级的问题,因为调用这个宏的人可能多种多样。
3)尽可能的使用最简单的运算符进行coding,可以避免一些问题,当然如果反复调用的情况下,还是需要定义宏,当然定义要慎重,参考2)
4)基础很重要啊,要能快速的找到问题的根源还是需要熟悉各种运算符的优先级,这次又好好的复习了一下。
顺便附上C语言中常用运算符的优先级:
1 () [] -> . :: ! ~ ++ --
2 - (unary) * (dereference) & (address of) sizeof
3 ->* .*
4 * (multiply) / %
5 + -
6 << >>
7 < <= > >=
8 == !=
9 & (bitwise AND)
10 ^
11 |
12 &&
13 ||
14 ? :
15 = += -= etc.
16 ,
posted @
2009-05-22 13:18 yuhen 阅读(1676) |
评论 (4) |
编辑 收藏