转载:http://www.51testing.com/html/17/n-3725417.html
本人作为一名test人员,目前在创业公司上班,针对公司产品需求,做系统
功能测试,由于测试只有1人,只做了系统功能测试,但测试项目过程中,发现如下问题:
产生问题:
1.开发编码后,未做过自测试,就将代码提测测试人员
2.缺少产品、开发相关性文档,导致测试人员是盲目,没有一个很明确的目标
3.项目开发管理者,未做版本管理,导致测试人员无法做版本质量控制
4.项目开发管理者,管理能力缺少,不能很好的管理好开发人员
5.测试过程中,测试人员反馈,项目反复出现的问题,公司领导(产品经理、boss、人事等)没有相关的制度进行管理
6.测试过程中,产品频繁的修改需求,因此开发需要修改代码,导致测试重复性,进而导致测试周期的延长
解决方案:
1.公司针对项目质量实行相关的奖惩制度
2.测试人员要求产品人员、开发人员,提交产品测试的相关详细文档(产品需求说明书、软件设计说明书)
3.开发编码后,提交测试前,测试人员做冒烟测试,通过,即进行版本测试,不通过,返回给开发返工
4.公司领导,给
项目管理者,施压,将项目质量,并纳入绩效考核
5.产品设计时,召开产品需求会议,参会人员(产品、开发、测试、运维),对产品设计存在的不足,提出个人的建议
摘要: 转载:http://www.51testing.com/html/87/n-3725387.html1. CS/CSS系统架构的基本概念 1.1系统架构定义 虽然B/S结构、J2EE架构愈来愈成为流行模式,但基于传统的C/S结构的应用程序还广泛地应用于各种行业。尤其是金融行业中的商业银行柜面-核心帐务 系统等...
阅读全文
运营快速增长的
技术创企往往面临一些挑战,许多人以为这不过是说说而已。但根据我个人的经历而言,这种说法简直太轻描淡写了,这是我有史以来做过的最困难的事情,不过也是最有价值的事。
1999年我进入了eBay,那时我还没有什么运营业务的经验。而在迪士尼商店担任了首席财务官之后,我管理了组织内的部分小组,但积攒的管理经验也不多。而后,我还在Reel.com担任了一小段时间的首席执行官。
尽管我缺乏经营经验,但是eBay的首席执行官梅格·惠特曼(MegWhitman)还是愿意给我一次机会。在我1990年加入华特迪士尼公司的战略计划部门时,梅格彼时正担任公司的人事部经理。九年后,当我们都离开了迪士尼之后,她就邀请我加入eBay。在我的印象中,我一直以为eBay是那种出售豆豆公仔(BeanieBabies)等收藏品的老网站,但后来我才意识到这个网站的潜在优势。但这要归功于梅格的坚定,是她成功地点醒了我,说服我加入了eBay。
我刚进eBay时管理的是一个刚起步的服务部门,部门责任是发展公司的伙伴关系,以便促成eBay上的贸易。很快,梅格决定将eBay分成两个分部,同时推出国际部门。2000年初,梅格任命我为eBay北美的负责人。时光飞逝,在我任职的五年内,该部门也实现了超高速增长。在此期间,我负责了eBay的对Paypal的收购,并在2005年管理起了PayPal。在我刚开启eBay生涯时,我只能管理一个人,而七年后我却管理起了五千人。
回顾我在eBay的这七年,我发现成功运营高速增长业务的经验和要求是随着时间变化的。在这里,我想拿体育行业做比喻:
员工=1-10。球员:
当我刚开始管理eBay北美时,我大概只需要管理六个人。在这个级别上,我差不多要参与每项决策。这种感觉就像是我参与了一场高赌注的比赛,如果我身边人举措不当,我的肾上腺素就要开始飙升了。
员工=10-100。教练:
当员工人数上升,不但决策数量会大大提高,而且下达决策的速度要更快。现在,有很多人等待着我的决策,而这时候我再参与到每项决策中,明显是不符合实际的。我发现我需要聘请有才之士来帮助我做出决策。我将这些日常决策者组成一支团队,管理他们,告诉他们整体方向和调整建议,但是不插手他们的执行过程。我要管理这么多人,就必须先成为教练,让我的队员帮我管理其它人。
雇员=100-1000。总经理:
很快,教练这个身份也不够用了。我委派的日常决策者很快也发现他们自己也无法做出所有的决策。他们现在也需要成为教练,建立他们自己的团队,并将他们的决策权委派给他们的队员。而我,也需要用不同的方式来指导这些新教练,虽然我还是要帮他们把握整体方向,但我也要开始制定高层组织目标、协调个人努力,以及调整这些迅速增长的团队之间的组织关系。我必须成为这个快速成长的团队的总经理。
员工=1000-10000。总干事:
当我开始管理PayPal时,整支队伍的规模已经达到了上千人。很快我就发现,我在总经理级别上刚挖掘到的技能又不够用了。这个组织是如此庞大,下属队员已经出现了两三个层级。只有我实现了完美的管理,整个组织才能同心同力,队员们的潜能才会被释放,他们才会把大部分的精力投入到比赛中去。用体育上的话来说,我现在可能是球队的所有者,也可能是联盟的总干事,但我对遥远赛场上的情况了如指掌。
在此过程中,我有个重要的发现,企业规模将会迅速扩大,为了有效管理这样的企业,我需要快速且持续地升级自身的技能。在我反思后,下面这些方法能帮助我进行管理升级:
定期收集反馈。相信我,如果你向别人收集反馈,而通常又能以建设性的方式来回应人们的反馈,那么他们会很乐意做这件事的。反馈虽然会让我感到恐惧,但它是具有建设意义的,比如说反馈能呈现出某些事项是否有效,或者说我又需要学习哪些新技能。
与教练共事。我的好友约翰·多纳霍(JohnDonahoe),目前正担任eBay的首席执行官,是他在我沮丧之时让我相信,人们在做事情时都需要一个教练。他告诉我,如果连世界级运动员老虎伍兹都借助了教练的力量,那么那些渴望有所进步的高管为什么不这样做呢?这些年来,我请教了很多教练,他们帮助我发展管理和领导技能,也让我能更好地服务于eBay和PayPal的用户!
寻找导师。我最终明白了,我肯定不是第一个经历某种情况的人。而硅谷恰好又是那种的超高速增长公司的发源地,因此,渐渐地,我和在这些公司工作过的人建立起了密切的联系,最后证明这对我很有帮助。
而成功使用这些方法的关键在于求知若渴、百折不挠,既要能正视自己的长短处,也要学会和组织一起在实践中改正缺点。对我来说,提升自己的过程比较漫长,不过,这个旅程也让人欣喜。我想起了我与斯科特·麦克尼利(ScottMcNealy)的一次谈话,当时我觉得,随着业务规模的扩大,虽然效率提升了,但是乐趣也变少了。而他是这么劝解我的,“你就不懂了吧,你只有把手上的这些事做好了,公司里的其他人才能有效率和快乐可言。”当时我还不懂,但是现在的我做到了这一点。
转载:www.51testing.com/html/80/n-3725380.html
本文转自:51Testing软件测试网。(http://www.51testing.com/html/27/n-7827.html)
第一章:日志管理
1.forcing log switches
sql> alter system switch logfile;
2.forcing checkpoints
sql> alter system checkpoint;
3.adding online redo log groups
sql> alter database add logfile [group 4]
sql> ('/disk3/log4a.rdo','/disk4/log4b.rdo') size 1m;
4.adding online redo log members
sql> alter database add logfile member
sql> '/disk3/log1b.rdo' to group 1,
sql> '/disk4/log2b.rdo' to group 2;
5.changes the name of the online redo logfile
sql> alter database rename file 'c:/oracle/oradata/oradb/redo01.log'
sql> to 'c:/oracle/oradata/redo01.log';
6.drop online redo log groups
sql> alter database drop logfile group 3;
7.drop online redo log members
sql> alter database drop logfile member 'c:/oracle/oradata/redo01.log';
8.clearing online redo log files
sql> alter database clear [unarchived] logfile 'c:/oracle/log2a.rdo';
9.using logminer analyzing redo logfiles
a. in the init.ora specify utl_file_dir = ' '
b. sql> execute dbms_logmnr_d.build('oradb.ora','c:\oracle\oradb\log');
c. sql> execute dbms_logmnr_add_logfile('c:\oracle\oradata\oradb\redo01.log',
sql> dbms_logmnr.new);
d. sql> execute dbms_logmnr.add_logfile('c:\oracle\oradata\oradb\redo02.log',
sql> dbms_logmnr.addfile);
e. sql> execute dbms_logmnr.start_logmnr(dictfilename=>'c:\oracle\oradb\log\oradb.ora');
f. sql> select * from v$logmnr_contents(v$logmnr_dictionary,v$logmnr_parameters
sql> v$logmnr_logs);
g. sql> execute dbms_logmnr.end_logmnr;
第二章:表空间管理
1.create tablespaces
sql> create tablespace tablespace_name datafile 'c:\oracle\oradata\file1.dbf' size 100m,
sql> 'c:\oracle\oradata\file2.dbf' size 100m minimum extent 550k [logging/nologging]
sql> default storage (initial 500k next 500k maxextents 500 pctinccease 0)
sql> [online/offline] [permanent/temporary] [extent_management_clause]
2.locally managed tablespace
sql> create tablespace user_data datafile 'c:\oracle\oradata\user_data01.dbf'
sql> size 500m extent management local uniform size 10m;
3.temporary tablespace
sql> create temporary tablespace temp tempfile 'c:\oracle\oradata\temp01.dbf'
sql> size 500m extent management local uniform size 10m;
4.change the storage setting
sql> alter tablespace app_data minimum extent 2m;
sql> alter tablespace app_data default storage(initial 2m next 2m maxextents 999);
5.taking tablespace offline or online
sql> alter tablespace app_data offline;
sql> alter tablespace app_data online;
6.read_only tablespace
sql> alter tablespace app_data read only|write;
7.droping tablespace
sql> drop tablespace app_data including contents;
8.enableing automatic extension of data files
sql> alter tablespace app_data add datafile 'c:\oracle\oradata\app_data01.dbf' size 200m
sql> autoextend on next 10m maxsize 500m;
9.change the size fo data files manually
sql> alter database datafile 'c:\oracle\oradata\app_data.dbf' resize 200m;
10.Moving data files: alter tablespace
sql> alter tablespace app_data rename datafile 'c:\oracle\oradata\app_data.dbf'
sql> to 'c:\oracle\app_data.dbf';
11.moving data files:alter database
sql> alter database rename file 'c:\oracle\oradata\app_data.dbf'
sql> to 'c:\oracle\app_data.dbf';
第三章:表
1.create a table
sql> create table table_name (column datatype,column datatype]....)
sql> tablespace tablespace_name [pctfree integer] [pctused integer]
sql> [initrans integer] [maxtrans integer]
sql> storage(initial 200k next 200k pctincrease 0 maxextents 50)
sql> [logging|nologging] [cache|nocache]
2.copy an existing table
sql> create table table_name [logging|nologging] as subquery
3.create temporary table
sql> create global temporary table xay_temp as select * from xay;
on commit preserve rows/on commit delete rows
4.pctfree = (average row size - initial row size) *100 /average row size
pctused = 100-pctfree- (average row size*100/available data space)
5.change storage and block utilization parameter
sql> alter table table_name pctfree=30 pctused=50 storage(next 500k
sql> minextents 2 maxextents 100);
6.manually allocating extents
sql> alter table table_name allocate extent(size 500k datafile 'c:/oracle/data.dbf');
7.move tablespace
sql> alter table employee move tablespace users;
8.deallocate of unused space
sql> alter table table_name deallocate unused [keep integer]
9.truncate a table
sql> truncate table table_name;
10.drop a table
sql> drop table table_name [cascade constraints];
11.drop a column
sql> alter table table_name drop column comments cascade constraints checkpoint 1000;
alter table table_name drop columns continue;
12.mark a column as unused
sql> alter table table_name set unused column comments cascade constraints;
alter table table_name drop unused columns checkpoint 1000;
alter table orders drop columns continue checkpoint 1000
data_dictionary : dba_unused_col_tabs
第四章:索引
1.creating function-based indexes
sql> create index summit.item_quantity on summit.item(quantity-quantity_shipped);
2.create a B-tree index
sql> create [unique] index index_name on table_name(column,.. asc/desc) tablespace
sql> tablespace_name [pctfree integer] [initrans integer] [maxtrans integer]
sql> [logging | nologging] [nosort] storage(initial 200k next 200k pctincrease 0
sql> maxextents 50);
3.pctfree(index)=(maximum number of rows-initial number of rows)*
100/maximum number of rows
4.creating reverse key indexes
sql> create unique index xay_id on xay(a) reverse pctfree 30 storage(initial 200k
sql> next 200k pctincrease 0 maxextents 50) tablespace indx;
5.create bitmap index
sql> create bitmap index xay_id on xay(a) pctfree 30 storage( initial 200k next 200k
sql> pctincrease 0 maxextents 50) tablespace indx;
6.change storage parameter of index
sql> alter index xay_id storage (next 400k maxextents 100);
7.allocating index space
sql> alter index xay_id allocate extent(size 200k datafile 'c:/oracle/index.dbf');
8.alter index xay_id deallocate unused;
第五章:约束
1.define constraints as immediate or deferred
sql> alter session set constraint[s] = immediate/deferred/default;
set constraint[s] constraint_name/all immediate/deferred;
2. sql> drop table table_name cascade constraints
sql> drop tablespace tablespace_name including contents cascade constraints
3. define constraints while create a table
sql> create table xay(id number(7) constraint xay_id primary key deferrable
sql> using index storage(initial 100k next 100k) tablespace indx);
primary key/unique/references table(column)/check
4.enable constraints
sql> alter table xay enable novalidate constraint xay_id;
5.enable constraints
sql> alter table xay enable validate constraint xay_id;
第六章:LOAD数据
1.loading data using direct_load insert
sql> insert /*+append */ into emp nologging
sql> select * from emp_old;
2.parallel direct-load insert
sql> alter session enable parallel dml;
sql> insert /*+parallel(emp,2) */ into emp nologging
sql> select * from emp_old;
3.using sql*loader
sql> sqlldr scott/tiger \
sql> control = ulcase6.ctl \
sql> log = ulcase6.log direct=true
第七章:reorganizing data
1.using expoty
$exp scott/tiger tables(dept,emp) file=c:\emp.dmp log=exp.log compress=n direct=y
2.using import
$imp scott/tiger tables(dept,emp) file=emp.dmp log=imp.log ignore=y
3.transporting a tablespace
sql>alter tablespace sales_ts read only;
$exp sys/.. file=xay.dmp transport_tablespace=y tablespace=sales_ts
triggers=n constraints=n
$copy datafile
$imp sys/.. file=xay.dmp transport_tablespace=y datafiles=(/disk1/sles01.dbf,/disk2
/sles02.dbf)
sql> alter tablespace sales_ts read write;
4.checking transport set
sql> DBMS_tts.transport_set_check(ts_list =>'sales_ts' ..,incl_constraints=>true);
在表transport_set_violations 中查看
sql> dbms_tts.isselfcontained 为true 是, 表示自包含
第八章:managing password security and resources
1.controlling account lock and password
sql> alter user juncky identified by oracle account unlock;
2.user_provided password function
sql> function_name(userid in varchar2(30),password in varchar2(30),
old_password in varchar2(30)) return boolean
3.create a profile : password setting
sql> create profile grace_5 limit failed_login_attempts 3
sql> password_lock_time unlimited password_life_time 30
sql>password_reuse_time 30 password_verify_function verify_function
sql> password_grace_time 5;
4.altering a profile
sql> alter profile default failed_login_attempts 3
sql> password_life_time 60 password_grace_time 10;
5.drop a profile
sql> drop profile grace_5 [cascade];
6.create a profile : resource limit
sql> create profile developer_prof limit sessions_per_user 2
sql> cpu_per_session 10000 idle_time 60 connect_time 480;
7. view => resource_cost : alter resource cost
dba_Users,dba_profiles
8. enable resource limits
sql> alter system set resource_limit=true;
第九章:Managing users
1.create a user: database authentication
sql> create user juncky identified by oracle default tablespace users
sql> temporary tablespace temp quota 10m on data password expire
sql> [account lock|unlock] [profile profilename|default];
2.change user quota on tablespace
sql> alter user juncky quota 0 on users;
3.drop a user
sql> drop user juncky [cascade];
4. monitor user
view: dba_users , dba_ts_quotas
第十章:managing privileges
1.system privileges: view => system_privilege_map ,dba_sys_privs,session_privs
2.grant system privilege
sql> grant create session,create table to managers;
sql> grant create session to scott with admin option;
with admin option can grant or revoke privilege from any user or role;
3.sysdba and sysoper privileges:
sysoper: startup,shutdown,alter database open|mount,alter database backup controlfile,
alter tablespace begin/end backup,recover database
alter database archivelog,restricted session
sysdba: sysoper privileges with admin option,create database,recover database until
4.password file members: view:=> v$pwfile_users
5.O7_dictionary_accessibility =true restriction access to view or tables in other schema
6.revoke system privilege
sql> revoke create table from karen;
sql> revoke create session from scott;
7.grant object privilege
sql> grant execute on dbms_pipe to public;
sql> grant update(first_name,salary) on employee to karen with grant option;
8.display object privilege : view => dba_tab_privs, dba_col_privs
9.revoke object privilege
sql> revoke execute on dbms_pipe from scott [cascade constraints];
10.audit record view :=> sys.aud$
11. protecting the audit trail
sql> audit delete on sys.aud$ by access;
12.statement auditing
sql> audit user;
13.privilege auditing
sql> audit select any table by summit by access;
14.schema object auditing
sql> audit lock on summit.employee by access whenever successful;
15.view audit option : view=> all_def_audit_opts,dba_stmt_audit_opts,
dba_priv_audit_opts,dba_obj_audit_opts
16.view audit result: view=> dba_audit_trail,dba_audit_exists,dba_audit_object,
dba_audit_session,dba_audit_statement
第十一章: manager role
1.create roles
sql> create role sales_clerk;
sql> create role hr_clerk identified by bonus;
sql> create role hr_manager identified externally;
2.modify role
sql> alter role sales_clerk identified by commission;
sql> alter role hr_clerk identified externally;
sql> alter role hr_manager not identified;
3.assigning roles
sql> grant sales_clerk to scott;
sql> grant hr_clerk to hr_manager;
sql> grant hr_manager to scott with admin option;
4.establish default role
sql> alter user scott default role hr_clerk,sales_clerk;
sql> alter user scott default role all;
sql> alter user scott default role all except hr_clerk;
sql> alter user scott default role none;
5.enable and disable roles
sql> set role hr_clerk;
sql> set role sales_clerk identified by commission;
sql> set role all except sales_clerk;
sql> set role none;
6.remove role from user
sql> revoke sales_clerk from scott;
sql> revoke hr_manager from public;
7.remove role
sql> drop role hr_manager;
8.display role information
view: =>dba_roles,dba_role_privs,role_role_privs,dba_sys_privs,
role_sys_privs,role_tab_privs,session_roles
第十二章: BACKUP and RECOVERY
1. v$sga,v$instance,v$process,v$bgprocess,v$database,v$datafile,v$sgastat
2. Rman need set dbwr_IO_slaves or backup_tape_IO_slaves and large_pool_size
3. Monitoring Parallel Rollback
> v$fast_start_servers , v$fast_start_transactions
4.perform a closed database backup (noarchivelog)
> shutdown immediate
> cp files /backup/
> startup
5.restore to a different location
> connect system/manager as sysdba
> startup mount
> alter database rename file '/disk1/../user.dbf' to '/disk2/../user.dbf';
> alter database open;
6.recover syntax
--recover a mounted database
>recover database;
>recover datafile '/disk1/data/df2.dbf';
>alter database recover database;
--recover an opened database
>recover tablespace user_data;
>recover datafile 2;
>alter database recover datafile 2;
7.how to apply redo log files automatically
>set autorecovery on
>recover automatic datafile 4;
8.complete recovery:
--method 1(mounted databae)
>copy c:\backup\user.dbf c:\oradata\user.dbf
>startup mount
>recover datafile 'c:\oradata\user.dbf;
>alter database open;
--method 2(opened database,initially opened,not system or rollback datafile)
>copy c:\backup\user.dbf c:\oradata\user.dbf (alter tablespace offline)
>recover datafile 'c:\oradata\user.dbf' or
>recover tablespace user_data;
>alter database datafile 'c:\oradata\user.dbf' online or
>alter tablespace user_data online;
--method 3(opened database,initially closed not system or rollback datafile)
>startup mount
>alter database datafile 'c:\oradata\user.dbf' offline;
>alter database open
>copy c:\backup\user.dbf d:\oradata\user.dbf
>alter database rename file 'c:\oradata\user.dbf' to 'd:\oradata\user.dbf'
>recover datafile 'e:\oradata\user.dbf' or recover tablespace user_data;
>alter tablespace user_data online;
--method 4(loss of data file with no backup and have all archive log)
>alter tablespace user_data offline immediate;
>alter database create datafile 'd:\oradata\user.dbf' as 'c:\oradata\user.dbf''
>recover tablespace user_data;
>alter tablespace user_data online
5.perform an open database backup
> alter tablespace user_data begin backup;
> copy files /backup/
> alter database datafile '/c:/../data.dbf' end backup;
> alter system switch logfile;
6.backup a control file
> alter database backup controlfile to 'control1.bkp';
> alter database backup controlfile to trace;
7.recovery (noarchivelog mode)
> shutdown abort
> cp files
> startup
8.recovery of file in backup mode
>alter database datafile 2 end backup;
9.clearing redo log file
>alter database clear unarchived logfile group 1;
>alter database clear unarchived logfile group 1 unrecoverable datafile;
10.redo log recovery
>alter database add logfile group 3 'c:\oradata\redo03.log' size 1000k;
>alter database drop logfile group 1;
>alter database open;
or >cp c:\oradata\redo02.log' c:\oradata\redo01.log
>alter database clear logfile 'c:\oradata\log01.log';
在python项目中常会发现作为数据容器的某个对象每次都需要被载入到内存,然后在程序运行之后,该对象还需要被保存下来供下次使用。将对象的状态信息转换为序列字符存储的过程就是对象序列化,反之将对象的序列信息恢复成内存对象,就是反序列化过程。
python 序列化示例
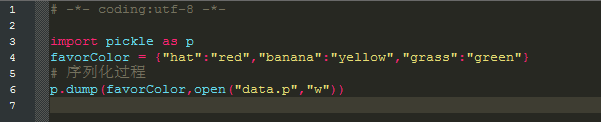
打开data.p文件,我们可以看到以下的字典对象被序列化的字符内容:

python 反序列化示例
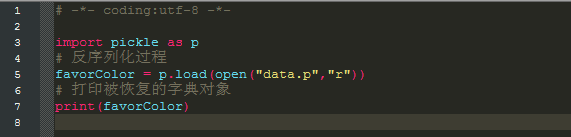
运行结果

好了,想成为技术大牛么?可前往51Testing软件测试网(http://www.51testing.com),掌握更多关于IT编程方面的技巧喔~

软件生命周期中,软件修复成本金字塔,越往下修改成本越大。
需求阶段发现需求变更代价最小,其他由小到大依次是设计阶段 ,编码阶段,测试阶段,当到达用户测试阶段和维护阶段时,此时修改代码的代价是原来的5-20倍以上,所以这就是需求阶段就与用户沟通,给他们看原型评审,进行需求确认的意义,减少风险,节约成本。
10月份XXX系统进行需求变更,增加了香港的需求后,新功能做完了,改出来上百个bug,按照经验个人认为是由于在系统测试阶段才进行修改代码的代价。建议以后的项目,必须增加需求确认环节,需求肯定会变,但我们要管理和控制它,让它在一个可控范围内。比如黑龙江就应该在作出原型,画完流程图后与用户确认,这样才能减少我们的成本超标风险。
举例:
比如需求1和需求2在一开始就开发,它们各自的成本是5人/天,一次性开发是10人/天。
由于需求2一开始并未提出,项目组只开发了需求1,进入测试阶段后,发现需求2也要开发,此时需求2的成本按照软件工程理论翻倍5-20倍,假设为5*5=25,那么总成本可能为30人/天。
想了解更多关于软件方面的文章,请前往51Testing软件测试网(http://www.51testing.com)哈~
总结下遇到的web测试的时候需要注意的地方:
页面分辨率:
通常是计算机的默认分辨率,但是还是会有一些老式电脑存在1024*768的情况
浏览器的兼容性:
目前市场上的主流浏览器:IE8.0-11,Chrome,Firefox,360浏览器。通常要保持IE和chrome,firefox浏览器下的兼容性,需要保持页面不变型,js均执行正常
开发设计组需要制定页面设计规范和js设计规范,保证主流的浏览器页面显示兼容性和js设计兼容性。
易用性:
Tab键的使用:页面中支持tab按键切换
Enter键的使用:页面中的某些确定按钮可以使用enter键盘替代
前进和后退:用户前进和后退有可能会造成数据不完整的提交,重复提交,或者其他的显示问题
用户删除某个数据前,需要提示用户是否删除,默认焦点选择为“否”
页面的提示语言,js提示语言,程序提示语言:
提示风格不一样,或者表达不够清晰
微软语言标准:
全角字符和半角字符都要使用一个空格分开
英文和数字直接要有空格分开
汉字和英文,数字要有空格分开
带有汉字的话要用全角字符
语言中不要混用全角和半角标点
在语言中,永远不要用“你”这个字,要做进一步的步骤描叙的时候,要多用“请”字
文字的缩略和折行:
输入框提交很长的字符,并且不折行,则提交后,页面有可能被拉的非常长,如果要将文字后面的一些文字处理为省略号,需要注意不要将中文截成半个字符
图片的显示和链接:
图片是否增加链接通常被开发人员忽略
图片的显示位置通常会显示不同像素大小和比例的图,所以要明确定义图片的处理策略
重复提交:
用户提交数据页面,用户有可能连续多次点击提交按钮,造成数据的重复提交
用户点击“提交”后,将按钮变成Disable状态
输入判断问题:
所有键盘输入的特殊字符,均可以正常保存
需要特别出处理英文单引号,英文双引号等引起的程序错误的问题
需要处理“<”“/” “\”等容易保存出错的符号
做出特殊模块的字符规划
多个IE同时访问的情况:
用户可能打开不同的IE使用相同的账户去进行操作,数据是否一致性和同步的问题
多个IE使用不同用户,cookie操作会不会出现用户信息混乱的问题
安全考虑:
不要把密码等敏感的用户信息明文的显示在url中
即使是传递密码参数,也不要用pwd,passpord这样的参数名称来进行传递,防止被截获
要在传递参数的操作中使用NoCache参数,防止将url参数进行缓存
防止Sql注入:
不要把数据库或程序的如何报错信息显示在页面上
最好程序能够将select、update、delete 这些关键字都过滤掉,不让用户提交包含这些数据的信息
数据库中设计到操作权限的表名和字段名别用很通俗易懂的名字
输入框尽量过滤掉“<>”这样的字符,防止javascript攻击
关于Cookie:
Cookie没有设定过期时间
IE不支持Cookie的时候没有如何提示信息
Cookie中的敏感信息没有进行加密
各种资源链接的释放:
有时候系统莫名访问不了,则有可能是数据库的链接没有释放
压力测试的时候,连接释放如果效率不高,则有可能出现大量连接超时失败
预防:系统资源的释放过程,最好通过代码review的方式来互相监督
关于Keepalive的设置:
如果需要在一个连接同时获取多个资源,则需要打开apache或resin的Keepalive参数为On,来提高系统的处理能力,减少多次建立连接所消耗的资源,如果大量的处理只是一次性连接,则不要打开
预防:在实际工作中,需要将keepalive分别设置为On或者Off来验证哪个设置的性能更好
系统上线后的log配置
上线以后,要关闭无用大量调试log信息,不要打开过多的log
想要了解更多测试内容可参考51Testing软件测试网(http://www.51testing.com),会让你收获更多~
用户故事验收标准的定义
“验收标准”和“满足条件”交替使用,可以清晰的定义价值主张、用户流程或解决方案的特点。
验收标准可作为测试用例的催化剂,应该是可验证的,并且能提供详细的要求范围,有助于团队理解用户故事的价值并进行合理的拆分。
满足条件则有助于在团队中确定他们应该考虑完成某项工作时的期望,并能帮助团队拆分任务中的用户故事,如果详细定义了验收标准,那么团队就能更好地对用户故事进行估算,从而使开发周期缩短、避免浪费。
用户故事验收标准如何写
验收标准是用户故事必备的。它是一个检查清单,用来确定用户故事的所有参数以及完成所需的工作量/时间。在开发将用户故事标记为“已完成“前,需要确保这个故事按照计划进行和测试,并且满足所有标准。
通常由PO负责制定每个用户故事的验收标准。一个完美的用户故事,验收标准将会使功能相当的透明,这有助于PO发现缺失点并验证假设。
敏捷验收标准示例
Scrum中并没有关于验收标准的模板,它是PO提出的对系统或功能的详尽描述,是对用户故事进行验证和测试的标准。
验收标准应该包含:
●功能的负面场景
●用户故事对其他功能的影响
●用户体验问题
●功能和非功能用例
●性能问题和指导方针
●系统和功能的用处
●功能系统不能和不应该做的事
●端到端的用户流
什么是验收标准不该有的?用户故事不该包含以下这些明显的内容:
●代码评审完成
●执行性能测试
●验收和功能测试完成
●上述清单还要包含DOD的一部分,在整个Sprint进程中,那些不应该是验收标准的一部分
用户故事和验收标准怎么写
验收标准应该描述得很清晰,简单来说就是对预期结果没有任何含糊之处。这可以确保测试员在接到验收标准是能成功的将其转化为手动或自动测试用例。
常用的用户故事模板是:
作为一名___,我想___,以便___
具有验收标准的用户故事实例
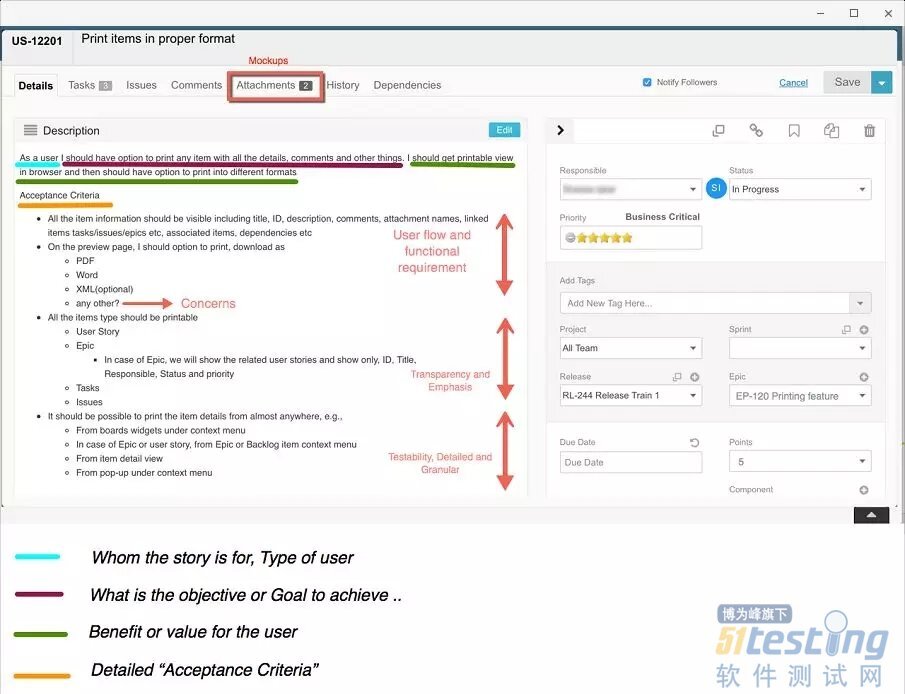
这是一个具有验收标准的用户故事的详细示例,是被称为打印的新功能实现的案例。这个新功能向用户提供了用户故事的打印格式,或者可显示格式的bug。
验收标准的实例
“作为用户我应该有一个选项来选择打印所有的细节、评论或其他东西。我应该可以在浏览器里看到打印视图,并且可以选择打印成不同的格式”
验收标准
●所有的项目信息都应该是可见的,包括标题、ID、描述、评论、附件名称、链接项目任务/事件/epics等、相关的项目、依赖性等等。
●在预览页面,我应该选择打印、下载为:
●PDF
●Word
●XML
●其他?
●所有项目类型都是可打印的
●用户故事
●Epic
在Epic中,我们将展示相关的用户故事,并且只显示ID、名称、义务、状态及优先项
●任务
●问题
应该可以从任何地方打印项目细节。例如:
●上下文菜单中的桌面小部件
●Epic或代办列表中的用户故事于epic
●项目细节视图
●上下文菜单里的弹窗
欢迎拍砖留言,当然想学习更多测试方面的文章,请前往51Testing软件测试网。(http://www.51testing.com)
当我们进行社招面试时,有一个问题几乎是必问的;当我们去企业参加面试时,也有一个问题是必须面对的:
那就是—你为什么要离开上一家公司?
其实这个问题主要是想试探一下求职者的核心诉求,并借此预估一下他在本公司工作的稳定性。常见的答案也无非就是这么几种:对薪酬不满意、干得不爽,或者是想换个环境。
小编恰巧在大学毕业碌碌无为时担任过半年的人事助理,知道员工离职不外乎不爽,至于离职报告上写的那些林林总总的千奇百怪的申请,只能是莞尔一笑了,总而言之就是不爽才走的。
然而,近几年,我遇到过好几个初次跳槽的求职者给出的答案是:「在原来的公司学不到技术」。
一听到这个,我就不由得叹口气,因为根据我的经验,这句话如果由工作不满两年的人说出来,很大概率这是个不会学习不会感恩又特别爱抱怨的人。我们来从几个方面分析下:
1、从早忙到晚能力却没有提升,这是为什么?
从早到晚,加班到深夜,蓦然回首,而你的职位却原地踏步,设定了目标,尽管拼了全力,却依然完不成;一直很努力的你,感觉自己忙忙碌碌,但是能力一直没有多大提升……
如果你也有类似的困扰,那么说明你遇到职业“瓶颈”了。如果一直无法突破自我,就只能原地踏步。
这是因为,随着工作内容的变化,你原有的知识体系和技能已经不匹配,对新环境和变化的适应能力不够,无法应对瞬息万变的工作。
这就好比盖一栋楼房,你需要打好地基,建立知识框架,然后才能一层层往上盖。
所有的工作和学习都是类似的,我们将盖楼对应到软件测试工作中会得出以下结论:
软件测试的概念与理论、WEB前端基础等知识是地基,它是你职业生涯的基础,而软件测试工具或框架是技能,是房子的框架,地基扎实,技能均衡,这栋楼才能不断往上盖。因此,你只有解决了这些问题,你的职业发展才能更上一层楼,进入新的阶段。
2、为什么会有“瓶颈”?“瓶颈”能否被我们突破?我们又将如何突破“瓶颈”?
这些问题,美国的学习顾问、企业家布里塞尼奥在TED的演讲让人深受启发。他不但指出了问题所在,还提供了一套行之有效的解决方案。
布里塞尼奥发现,那些牛人之所以厉害,是因为他们能够在生活中刻意地在两个区域中切换。一个是学习区,另一个是执行区。
学习区是用来学习的。在这块区域中,我们要做的是学习、尝试、更新、反馈、总结、反思,从而不断提高自己的能力。
执行区是我们的日常工作。比如测试员跟踪bug,程序员写代码。
这两个区域很好理解。如果你现在是一个菜鸟软件测试员,你的领导不断的安排你测试一个接一个的新项目,你每天努力工作,训练技能,几年之后,你的软件测试技术越来越熟练。
这里顺便谈一下软件测试职业发展的线路(通常分为下面4类):
从初级测试工程师→中级测试工程师→高级测试工程师→资深测试工程师;
初级测试工程师→中级测试工程师→高级测试开发工程师;
初级测试工程师→测试组长→测试经理→项目经理→项目总监;
初级测试工程师→质量保证人员→质量管理人员。
然而,随着互联网的飞快发展,IT行业出现了日新月异的变化,新的技术会不断出现,你熟练掌握的软件测试技术很快就过时了。慢慢地,你就会发现,之前的技术已经无法应付越来越复杂的项目,你该怎么办呢?
这个时候,你只有苦练软件测试行业的新技术,学习涉略新的编程语言,才能应对不断变化的行业趋势,获得更好的发展。
不断提升自己,让自己更强大的方法,就是在学习区与执行区之间相互切换,有目的地培养相关技能,然后再把这些技能应用到执行区。
总而言之,我们在学习区待得越久,提升就越大。所以,如果要突破自我,就要增加学习区的时间,而且要从各方面进行自我进修。在当今的社会,学习力和抗压力远远比才华和才能重要的多。
3、如何突破人生发展的“瓶颈”,获得更大的提升,在行业内成为万里挑一的行业大牛?
首先,你要走出舒适区,敢于折腾自己
我们都知道,最锻炼能力的,往往是难熬的项目。如果你每天做的都是自己再熟悉不过的事情,那么你很难获得成长。
专家研究表明,只有在学习区练习才最有成效。所以接触一些不熟悉的领域,尝试一些有挑战性的任务,让自己过得不那么舒服。
对于一个软件测试工程师来说,如果你对手工测试和测试流程很熟悉了,你可以去学习基于工具的自动化测试,基于工具的自动化测试用的很溜的话,可以学习一下python这门语言,为今后自主开发自动化脚本打下基础。
这样,对软件测试各个模块都有了一定的了解后,团队合作会更顺畅,你对很多事情的看法都会发生改变,做事的格局也大不一样。如果老守着自己会的那点儿东西,总有一天会坐吃山空。
其次,注重刻意练习
刻意练习,其实是从“熟练”到“生巧”的转换方法,对于一个人的提升来说非常重要。
心理学专家发现,有不少成功人士,都是用“刻意练习”的方法来完善自己。
他们把精力放在“次级技能”——也就是不太好的技能上,对其进行学习,然后通过学习、反馈、调整以及专业的指导来获得提升。
还是拿我们软件测试来说,如果你想学习接口测试这门技术,你每天花40—50分钟,聚精会神,进行有针对性的学习和实践,那么不出三个月你就可以很好的掌握接口测试这门技术。
这就是刻意练习的意义:补齐强化我们的短板,让技能均衡,从而继续往上盖楼,迈入人生新的高度。
最后,不要害羞,不耻下问永远是我们提升自我的唯一法门,找高人指路
那么,如何发现自己的短板和问题?这就需要高人指点了。
韩寒说过一句话:“也许你的极限,只是别人的起点。”有时候,高人的一句话,胜过我们几年摸索。
在你陷入困境的时候,你就需要高人指路。高人能够指出你存在的隐藏缺陷,告诉你当前的状态是一个必经过程,解除你的迷茫和困惑,为你指出正确和合适的努力方向。
那么,高人在哪里?
你可以从行业内、身边、互联网上去寻找。如今是一个信息化的社会,只要你用心,一定可以找到满意的答案。
对于软测行业来说,博为峰网校的精品在线课程不失为是引路的高人。网校推出的全栈式测试开发课程,适合对自己有高要求高起点的软件测试从业人员,高品质内容+全方位答疑服务+直播互动+专属交流圈子+助教实时帮助跟进+学习成果检验,让你真正学有所得突破人生瓶颈。
4、软件测试员最核心的竞争力究竟是什么?
那就是“学习力”,可能你有抗压能力,可能你有沟通能力,但是学习力可不是人皆有之的。
互联网时代的技术来得快,去得更快。就像Flash这样曾经雄霸天下多年的技术,都有被人人唾弃的一天。如果没有足够强的学习能力,就无法跟上变化,被淘汰只是迟早的事。想想看,你苦心钻研多年引以为傲的技术,一夜之间就没有用武之地了,难免会有一种「身体被掏空」的感觉,这可不是随便吃几个药喝几瓶红牛上几个公开课能解决的。
5、软件测试员该怎么突破瓶颈提升自我?
有的求职者觉得自己没学到技术,是因为公司不给机会,或者缺乏条件:
学习技术最有效的方式是阅读、实践和交流。公司没给你安排这方面的工作,那你自己都做了些什么呢?八小时之外的时间都用在哪了?有没有读源码?有没有看原版书?有没有泡技术社区?有没有尝试最新流行的技术?有没有尝试把它们用在公司的项目上?有没有主动去接触行业里使用这些技术的团队和大牛?
「看文档」其实是最快的学习方法。对于自己工作中常用到的技术,抽时间把官方文档通读一遍(其实篇幅都不大),绝对收获满满。没事的时候多浏览下博为峰网校图书馆里的各种专业资料,就能秒杀95%的同行,不开玩笑,如果太困可以泡一杯咖啡。
「折腾」是学习任何技术的必经之路。在有保护的环境下进行大量的试错,是最高效的学习方法,所谓“实践是检验真理的唯一标准”。最有价值的东西,就是实战的机会。你所学习的技术,最终需要通过工作来变现。你有机会接触到真实的数据,了解真实的用户,观察真实系统是怎样运转的,积累真实的经验……
学习技术不外乎以下两个方向:
1、广度:整个使用链条由哪些环节构成?每个环节的作用是什么?都有哪些类似的可替代方案?它们之间有什么区别?各自优劣点是什么?……
2、深度:这个「技术/产品」的本质是什么?都能做什么?运作原理是什么?底层是如何实现的?可以做怎样的改进?……
不管你在做什么工作,都应该先把自己每天都要用的核心技术做到一定深度,再去拓展广度。学习,是一辈子的事。就如同博为峰网校,是软测行业topone—博为峰十年磨一剑倾心打造,博为峰推出365天/24小时的博为峰网校在线学习平台,致力打造国内知名IT职业教育平台。平台汇聚了职业教育领域的优良师资,推出内容优质、生动实用的各类IT课程,配以博为峰多年来的培训就业经验指导,即可免去学员舟车劳顿之苦,利用碎片化时间提升自己,又可梳理职业生涯,优化职业发展道路。更有兴趣小组、特色班级打造趣味化学习环境,与共同目标或共同兴趣的同学一起互助成长!
博为峰网校将在未来提供更丰富的、满足不同需求、兴趣爱好、以及个人习惯的在线IT课程,为学员提供优质、高效的在线学习平台,提供更有价值的增值服务,让所有做IT技术的、或者希望了解IT技术的人都能在这里找到自己最需要的,对自己最有价值的成长之路。
欢迎加入博为峰网校大课堂QQ群495351733,技术探讨、行业交流、资料下载、课程试听,更多惊喜等你来!