2010年2月4日
#
2010年1月28日
#
Delphi中实现全角转半角
function SbctoDbc(s:string):string;
var
nlength,i:integer;
str,ctmp,c1,c2:string;
{
在windows中,中文和全角字符都占两个字节,
并且使用了ascii chart 2
(codes 128 - 255
)。
全角字符的第一个字节总是被置为163,
而第二个字节则是相同半角字符码加上128(不包括空格)。
如半角a为65,则全角a则是163(第一个字节)、
193 (第二个字节, 128 + 65 )。
而对于中文来讲,它的第一个字节被置为大于163,(
如 ' 阿 ' 为:
176 162 ),我们可以在检测到中文时不进行转换。
}
begin
nlength: =
length(s);
if (nlength = 0 ) then
exit;
str: = '' ;
setlength(ctmp,nlength + 1 );
ctmp: = s;
i: = 1 ;
while (i <=
nlength) do
begin
c1: =
ctmp[i];
c2: = ctmp[i + 1 ];
if (c1 = # 163 ) then // 如果是全角字符
begin
str: = str + chr(ord(c2[ 1 ]) - 128
);
inc(i, 2
);
continue ;
end;
if (c1 > # 163 ) then //
如果是汉字
begin
str:
= str + c1;
str: = str +
c2;
inc(i, 2
);
continue ;
end;
if (c1 = # 161 ) and (c2 = # 161 )
then // 如果是全角空格
begin
str: = str + ' '
;
inc(i, 2
);
continue ;
end;
str: = str + c1;
inc(i);
end;
result: = str;
end;
---
本文章使用“国华软件”出品的博客内容离线管理软件MultiBlogWriter撰写并发布
2010年1月25日
#
Oracle性能优化与Delphi代码 <转>
刚学了点oracle方面的知识,感觉以前写代码只凭喜好写,完全没有深究缘由,导致在内行人看来,写的都是垃圾代码,现在就把学到的一些东西写出来,也算是给刚入门的朋友一点帮助吧。
以前,写数据库访问代码,感觉很简单,不就是sql语句嘛,所以什么语句都是这样写:
A:
qry1.Close;
qry1.SQL.Text := edt1.Text ;
qry1.Open
;
感觉挺好,语句自己拼,拼好了,直接执行。
还有另外一种写法:
B:
qry1.Close;
qry1.SQL.Text := edt1.Text
;
qry1.Parameters.ParamByName('vvv').Value := edt2.Text ;
qry1.Open
;
感觉这样写也是达到一样的结果,而用参数的方法,感觉很麻烦,多余,edt1.Text里变量还都得写成参数,所以从来不这样写,似乎也看不出和A方法有什么区别,只是更多了些麻烦。
最近学了点oracle性能优化方面的知识,知道了oracle的共享池,及其对性能的影响。共享池保存的是最近使用的sql语句,如果有相同的sql语句在共享池中,就不会再做分析、生成执行计划,效率就会提高很多,但是select
* from tableA where aa='a'和select * from tableA where
AA='a',会被认为是不同的sql语句,oracle会检查共享池里有没有完全相同的语句,没有则分别做分析、生成执行计划,虽然实质上是一样的sql语句。
所以,可以通过绑定变量的方式,使这些只是条件不同的语句,可以使oracle能够重复利用执行计划。
测试一下。
在pl/sql里的sql windows里,执行语句:
select sql_text from v$sqlarea where sql_text
like '%select * from abc where%'
查看共享池中的sql语句,返回的结果只有一行:
select sql_text
from v$sqlarea where sql_text like '%select * from abc where%'
然后执行语句:
select * from abc where ff =
1234
然后再查看共享池中的sql语句,看到了,这回结果集有两行返回:
select sql_text from v$sqlarea where
sql_text like '%select * from abc where%'
select * from abc where ff =
1234
执行:
select * from abc where ff =
345
然后再查看共享池中的sql语句,看到了,这回结果集有三行返回:
select sql_text from v$sqlarea where
sql_text like '%select * from abc where%'
select * from abc where ff =
1234
select * from abc where ff = 345
可见,当条件ff的值在变化时,同一条sql语句会被认为是不同的语句,而每次都去分析执行计划,导致的结果就是,就这一条sql语句,反复执行,就可以吃光共享池,导致oracle性能下降。
通过绑定变量,可以解决这个问题。
在command windows窗口中执行:
SQL> variable vvv number;
SQL> exec :vvv
:=999;
SQL> select * from abc where ff = :vvv;
SQL> exec :vvv
:=888;
SQL> select * from abc where ff = :vvv;
ok,然后再查看共享池中的sql语句,结果以上两行,只有一条记录:
select * from abc where ff =
:vvv
可见,虽然ff值不同了,但oracle仍然把这两句当做相同sql语句,就可以利用已经生成的执行计划。
说了这么多,和delphi有什么关系呢?delphi怎么利用绑定变量的方法去提高sql语句的执行效率呢?其实就是用参数。
回到最初的A、B两种写法,执行的结果是不同的,A写法,条件如果发生变化,每次执行都会在oracle共享池中生成新的记录,并分析执行计划,执行多了,会对整个数据库的性能造成影响,而B写法,ado驱动会按绑定变量的代码去后台执行,会提高oracle的执行效率。
所以,结论就是,能用参数方法去执行sql语句就用参数的方法,而尽量少用写好的sql语句去执行,写好的sql语句其实就是垃圾代码,当用的多时,会降低整个数据库的执行效率。
可以在delphi写的数据库访问程序中用select * from abc where ff =
做个测试,当使用A方法,把ff变量值拼成语句执行时,ff值发生变化,共享池中就会多出相应的sql语句执行计划,而使用select * from abc
where ff = :vvv的方法(也就是B写法),无论:vvv代入的值怎么变化,在共享池中始终就只有一条记录。
ms和oracle在这里的区别:
ms的oracle ADO驱动,生成的语句是:select * from abc where ff =
:V00001
而oracle的ADO驱动,生成的语句是:select * from abc where ff = :1
---
本文章使用“国华软件”出品的博客内容离线管理软件MultiBlogWriter撰写并发布
2010年1月21日
#
对PE资源的研究 <转>
前言:没什么好说的,发现这方面的资料全是英文的,于是我一边研究,一边翻译,一边写出自己的心得。
希望大家尊重我的劳动成果,转贴保持完整。
资源一般使用树来保存,通常包含3层,在NT下,最高层是类型,然后是名字,最后是语言。
一个PE文件是否包含资源文件,通常检测块表(Section
Table)中是否含有'.rsrc',不过这个方法对有些PE文件无效。
一个类型表结构如下
——————————————————————————
| RESOURCE
DIRECTORY |
——————————————————————————
|
RESOURCE DATA |
——————————————————————————
资源表1(Resource File Layout)
其中的资源目录(RESOURCE DIRECTORY)结构如下:
——————————————————————————
|
RESOURCE FLAGS |
——————————————————————————
|
TIME/DATE STAMP |
——————————————————————————
| MAJOR
VERSION |MINOR VERSION |
——————————————————————————
| # NAME
ENTRY |# ID ENTRY |
——————————————————————————
|
RESOURCE DIR ENTRIES |
——————————————————————————
资源表2(Resource Table Entry)
在DELPHI中的申明
{ Resources }
PIMAGE_RESOURCE_DIRECTORY =
^IMAGE_RESOURCE_DIRECTORY;
IMAGE_RESOURCE_DIRECTORY = packed record
Characteristics : DWORD;
TimeDateStamp : DWORD;
MajorVersion : WORD;
MinorVersion : WORD;
NumberOfNamedEntries : WORD;
NumberOfIdEntries : WORD;
end
其中:
RESOURCE FLAGS
通常设置为0
TIME/DATE STAMP
资源编译器建立此资源的时间/日期,可能为0
MAJOR/MINOR VERSION
版本信息
# NAME ENTRY
使用名字的资源条目的个数,包含一个使用名字的目录条目的数组。
# ID ENTRY
使用ID数字的资源条目的个数,包含一个32位的整数ID号,同用名字一样。
这个目录紧接着会是一个不定长度的目录条目,不管用的名字还是ID,都是用升序排列。
这个不定长度的目录结构如下:
31
0
——————————————————————
| NAME RVA/INTEGER
ID |
——————————————————————
|
E | DATA ENTRY RVA/SUBDIR RVA |
——————————————————————
资源表3(Resource Directory Entry)
在DELPHI中的申明:
PIMAGE_RESOURCE_DIRECTORY_ENTRY =
^IMAGE_RESOURCE_DIRECTORY_ENTRY;
IMAGE_RESOURCE_DIRECTORY_ENTRY =
packed record
Name:
DWORD; // Or ID: Word (Union)
OffsetToData: DWORD;
INTEGER ID
包含一个识别资源的整数ID
如果在根目录,这个ID表示的意义如下
资源类型
1: cursor
2: bitmap
3: icon
4: menu
5: dialog
6: string table
7: font directory
8: font
9: accelerators
10: unformatted
resource data
11: message table
12: group cursor
14: group icon
16: version information
NAME RVA
名字的相对实际地址,包含一个31位的相对资源的Image Base的地址。表的形式见表4
E 一位的不可缺少的识别码(mask 80000000h)
如果这位为0,则为Resource Data Entries,其中DATA RVA =
31位的(mask 7fffffffh) 数据条目的地址。结构见表5
如果这位为1,则表示接另一个子目录(Subdirectory Entry)。
{ 此函数检验 offset 是一个字符串名还是一个目录 }
{ IMAGE_RESOURCE_NAME_IS_STRING
=
IMAGE_RESOURCE_DATA_IS_DIRECTORY
= $80000000 }
function HighBitSet(L:
Longint): Boolean;
begin
Result := (L and
IMAGE_RESOURCE_DATA_IS_DIRECTORY) <> 0;
end;
{ 下面两个函数用于去掉E位剩下的值或者指针 }
{IMAGE_OFFSET_STRIP_HIGH = $7FFFFFFF;}
function StripHighBit(L: Longint): Longint;
begin
Result := L
and IMAGE_OFFSET_STRIP_HIGH;
end;
function StripHighPtr(L: Longint): Pointer;
begin
Result :=
Pointer(L and IMAGE_OFFSET_STRIP_HIGH);
end;
每一个资源目录名为如下格式
——————————————————————
|
LENGTH | UNICODE STRING |
——————————————————————
| LENGTH |
UNICODE STRING |
——————————————————————
表4(Resource Directory String Entry)
在DELPHI中的申明
PIMAGE_RESOURCE_DIR_STRING_U =
^IMAGE_RESOURCE_DIR_STRING_U;
IMAGE_RESOURCE_DIR_STRING_U = packed
record
Length : WORD;
NameString : array [0..0]
of WCHAR;
end;
LENGTH
就是字符串的长度
UNICODE STRING
Unicode的字符串.
资源数据表结构:
—————————————
| DATA RVA
|
—————————————
| SIZE |
—————————————
| CODEPAGE |
—————————————
| RESERVED |
—————————————
表5(Resource Data Entry)
在DELPHI中的申明
PIMAGE_RESOURCE_DATA_ENTRY =
^IMAGE_RESOURCE_DATA_ENTRY;
IMAGE_RESOURCE_DATA_ENTRY = packed record
OffsetToData : DWORD;
Size : DWORD;
CodePage :
DWORD;
Reserved
: DWORD;
end;
DATA RVA
资源的相对实际地址,包含一个32位相对于资源Image Base的地址。
SIZE
资源的大小。
CODEPAGE
没什么说的,好像为译码方面设置的。
RESERVED
一定为0
---
本文章使用“国华软件”出品的博客内容离线管理软件MultiBlogWriter撰写并发布
电子书是怎样炼成的?
网络将信息直接送到每个人的身边,如果对如此多的信息用个词形容的话,那么“泛滥”是最恰当不过了。信息重复的太多,对于某类网站其实在国内找一两家就可以了,因为只有那么几个站是原创的,其他的多以扒抄、转载为主,完全是别人吃剩下的馍,没有什么嚼头。自己发表的文章贴在网上,仿佛天生就是让人抄的,不管你乐意不乐意,因此对于网上文字的知识产权保护就是个问题。
不过确实也没有什么特别好的办法,网页上所有的文字,文章也好、小说也好,只要“复制”、“粘贴”就完全OK了,我们阻止不了。不过现在流行的“电子书”(E-Book)可以帮助我们解决这个问题,在电子书制作过程中我们可以设置“不可复制”属性,让抄袭者无处下手。当然“电子书”并不是仅仅只有这一点好处,容量大、使用方便,便于检索和统计,质量优良都是它的优点。电子书是专门用于在计算机上阅读的电子文档,按文件格式大致可将常见的电子图书分类:
1.PDF格式
PDF格式是ADOBE公司推出的电子图书专用格式,它无论在何种机器、何种操作系统上都以制作者所希望的形式显示和打印出来,表现出跨平台的一致性,效果非常理想。PDF文件中可包含图形,声音等多媒体信息,还可建立主题间的跳转、注释、并且PDF文件的信息是“内含”的,甚至可以把字体“嵌入”文件中,从而使得PDF文件成为完全“自足”的电子文档。许多“高档”的电子图书都采用该格式。不过它制作起来比较麻烦需要一定专业水准,多为厂商使用。
建议单位制作电子书使用。
2.网页格式
超文本作为目前WWW上最流行的文件显示格式,许多电子小说也采用了这种格式。HTML格式的特点就是显示效果好,表现力强,且文件比较紧凑,不会占用太多的磁盘空间。另外,HTML文件格式的兼容性非常好,完全不用担心他人无法阅读的情况(只要安装了Windows即可阅读HTML文档)。建议个人制作电子书使用。
3.图像格式
所谓图像格式的电子图书实际上就是使用扫描仪把原有的印刷书籍扫描到计算机中,然后采用图像方式保存下来,此后用户必须借助于图形浏览软件或专门的图形方式阅读软件才能进行阅读,使用不太方便。同时,采用图形格式还有一个明显的缺点,那就是体积比较大(这就导致下载、阅读明显速度都很慢),显示效果也不太好。不建议使用,目前仅图书馆网站使用。
4.CHM格式
原来的软件大多数采用扩展名为HLP的帮助文件(WinHelp
),但随着互联网的发展,这种格式的帮助文件已经难以适应软件在线帮助的需要,以及更加人性化、更加简单易于查看的需要,因此一种全新的帮助文件系统HTML
Help由微软率先在Windows
98中使用了。由于它是一个经过压缩的网页集合,不但减小了文件的体积,更利于用户从Internet上下载,并且还支持HTML、Ac-tiveX、Java、JScript、Visual
Basic Scripting 和多种图像格式(.jpeg、.gif和.png 等)。建议单位、个人制作电子书使用。
5.EXE文件格式
这是目前比较流行也是被许多人青睐的一种电子读物文件格式,其实就是利用电子书制作软件将网页格式的电子书生成为可执行文件。它最大的特点就是阅读方便,制作简单,制作出来的电子读物相当精美,无需专门的阅读器支持就可以阅读。这种格式的电子读物对运行环境并无很高的要求。但是这种格式的电子图书也有一些不足之处,如多数相关制作软件制作出来的EXE文件都不支持Flash和Java及常见的音频视频文件,需要IE浏览器支持等。
批量电子书制作
电子书的制作其实一个非常机械的制作过程,没有什么需要动脑的,只需要反反复复地进行完全一致的操作过程。有没有什么办法将这些机械的工作一步完成呢?
“电子文档处理器”就可以解决这个问题,它是一款文档转换、文档处理软件,电子书批量制作工具(目前支持CHM和HELP格式)。
值得一提的是软件是由中国人开发的,完全中文化的菜单和操作习惯,使用者非常容易上手。
选取待处理文件:通过目录选择框选取待处理文件所在目录,目录里面的文件都将被转换。
设置“选项”
:针对你要执行的功能仔细设置与该功能对应的“选项”。我们可以就标题背景色、标题前景色、标题字体、正文背景色、正文前景色、正文字体进行选择,直到自己满意为止。
点击你要执行的功能: 可以将文本转化为HTML、CHM、文件格式,也可将网页文件转化为TXT、CHM文件。
当然电子书并非不让大家的文字不再出现于网络,而是防止我们的辛苦成果被别人轻易抄袭。
---
本文章使用“国华软件”出品的博客内容离线管理软件MultiBlogWriter撰写并发布
用VC进行COM编程所必须掌握的理论知识 <转>
这篇文章是给初学者看的,尽量写得比较通俗易懂,并且尽量避免编程细节。完全是根据我自己的学习体会写的,其中若有技术上的错误之处,请大家多多指正。
一、为什么要用COM
软件工程发展到今天,从一开始的结构化编程,到面向对象编程,再到现在的COM,编程,目标只有一个,就是希望软件能象积方块一样是累起来的,是组装起来的,而不是一点点编出来的。结构化编程是函数块的形式,通过把一个软件划分成许多模块,每个模块完成各自不同的功能,尽量做到高内聚低藕合,这已经是一个很好的开始,我们可以把不同的模块分给不同的人去做,然后合到一块,这已经有了组装的概念了。软件工程的核心就是要模块化,最理想的情况就是100%内聚0%藕合。整个软件的发展也都是朝着这个方向走的。结构化编程方式只是一个开始。
下一步就出现了面向对象编程,它相对于面向功能的结构化方式是一个巨大的进步。我们知道整个自然界都是由各种各样不同的事物组成的,事物之间存在着复杂的千丝万缕的关系,而正是靠着事物之间的联系、交互作用,我们的世界才是有生命力的才是活动的。我们可以认为在自然界中事物做为一个概念,它是稳定的不变的,而事物之间的联系是多变的、运动的。事物应该是这个世界的本质所在。面向对象的着眼点就是事物,就是这种稳定的概念。
每个事物都有其固有的属性,都有其固有的行为,这些都是事物本身所固有的东西,而面向对象的方法就是描述出这种稳定的东西。而面向功能的模块化方法它的着眼点是事物之间的联系,它眼中看不到事物的概念它只注重功能,我们平常在划分模块的时侯有没有想过这个函数与哪些对象有关呢?很少有人这么想,一个函数它实现一种功能,这个功能必定与某些事物想联系,我们没有去掌握事物本身而只考虑事物之间是怎么相互作用而完成一个功能的。说白了,这叫本末倒置,也叫急功近利,因为不是我们智慧不够,只是因为我们没有多想一步。
面向功能的结构化方法因为它注意的只是事物之间的联系,而联系是多变的,事物本身可能不会发生大的变化,而联系则是很有可能发生改变的,联系一变,那就是另一个世界了,那就是另一种功能了。如果我们用面向对象的方法,我们就可以以不变应万变,只要事先把事物用类描述好,我们要改变的只是把这些类联系起来方法只是重新使用我们的类库,而面向过程的方法因为它构造的是一个不稳定的世界,所以一点小小的变化也可能导致整个系统都要改变。然而面向对象方法仍然有问题,问题在于重用的方法。搭积木式的软件构造方法的基础是有许许多多各种各样的可重用的部件、模块。
我们首先想到的是类库,因为我们用面向对象的方法产生的直接结果就是许多的类。但类库的重用是基于源码的方式,这是它的重大缺陷。首先它限制了编程语言,你的类库总是用一种语言写的吧,那你就不能拿到别的语言里用了。其次你每次都必须重新编译,只有编译了才能与你自己的代码结合在一起生成可执行文件。在开发时这倒没什么,关键在于开发完成后,你的EXE都已经生成好了,如果这时侯你的类库提供厂商告诉你他们又做好了一个新的类库,功能更强大速度更快,而你为之心动又想把这新版的类库用到你自己的程序中,那你就必须重新编译、重新调试!这离我们理想的积木式软件构造方法还有一定差距,在我们的设想里希望把一个模块拿出来再换一个新的模块是非常方便的事,可是现在不但要重新编译,还要冒着很大的风险,因为你可能要重新改变你自己的代码。另一种重用方式很自然地就想到了是DLL的方式。Windows里到处是DLL,它是Windows的基础,但DLL也有它自己的缺点。总结一下它至少有四点不足:
(1)函数重名问题
DLL里是一个一个的函数,我们通过函数名来调用函数,那如果两个DLL里有重名的函数怎么办?
(2)各编译器对C++函数的名称修饰不兼容问题
对于C++函数,编译器要根据函数的参数信息为它生成修饰名,DLL库里存的就是这个修饰名,但是不同的编译器产生修饰的方法不一样,所以你在VC里编写的DLL在BC里就可以用不了。不过也可以用extern
"C";来强调使用标准的C函数特性,关闭修饰功能,但这样也丧失了C++的重载多态性功能。
(3)路径问题
放在自己的目录下面,别人的程序就找不到,放在系统目录下,就可能有重名的问题。而真正的组件应该可以放在任何地方甚至可以不在本机,用户根本不需考虑这个问题。
(4)DLL与EXE的依赖问题
我们一般都是用隐式连接的方式,就是编程的时侯指明用什么DLL,这种方式很简单,它在编译时就把EXE与DLL绑在一起了。如果DLL发行了一个新版本,我们很有必要重新链接一次,因为DLL里面函数的地址可能已经发生了改变。DLL的缺点就是COM的优点。
首先我们要先把握住一点,COM和DLL一样都是基于二进制的代码重用,所以它不存在类库重用时的问题。另一个关键点是,COM本身也是DLL,既使是ActiveX控件.ocx它实际上也是DLL,所以说DLL在还是有重用上有很大的优势,只不过我们通过制订复杂的COM协议,通COM本身的机制改变了重用的方法,以一种新的方法来利用DLL,来克服DLL本身所固有的缺陷,从而实现更高一级的重用方法。
COM没有重名问题,因为根本不是通过函数名来调用函数,而是通过虚函数表,自然也不会有函数名修饰的问题。路径问题也不复存在,因为是通过查注册表来找组件的,放在什么地方都可以,即使在别的机器上也可以。也不用考虑和EXE的依赖关系了,它们二者之间是松散的结合在一起,可以轻松的换上组件的一个新版本,而应用程序混然不觉。
二、用VC进行COM编程,必须要掌握哪些COM理论知识
我见过很多人学COM,看完一本书后觉得对COM的原理比较了解了,COM也不过如此,可是就是不知道该怎么编程序,我自己也有这种情况,我经历了这样的阶段走过来的。要学COM的基本原理,我推荐的书是《COM技术内幕》。但仅看这样的书是远远不够的,我们最终的目的是要学会怎么用COM去编程序,而不是拼命的研究COM本身的机制。所以我个人觉得对COM的基本原理不需要花大量的时间去追根问底,没有必要,是吃力不讨好的事。其实我们只需要掌握几个关键概念就够了。这里我列出了一些我自己认为是用VC编程所必需掌握的几个关键概念。(这里所说的均是用C语言条件下的COM编程方式)
(1)
COM组件实际上是一个C++类,而接口都是纯虚类。组件从接口派生而来我们可以简单的用纯粹的C++的语法形式来描述COM是个什么东西:
class IObject
{
public:
virtual Function1(...) =
0;
virtual Function2(...) = 0;
....
};
class
MyObject : public IObject
{
public:
virtual
Function1(...){...}
virtual
Function2(...){...}
....
};
看清楚了吗?IObject就是我们常说的接口,MyObject就是所谓的COM组件。切记切记接口都纯虚类,它所包含的函数都是纯虚函数,而且它没有成员变量。而COM组件就是从这些纯虚类继承下来的派生类,它实现了这些虚函数,仅此而已。从上面也可以看出,COM组件是以C++为基础的,特别重要的是虚函数和多态性的概念,COM中所有函数都是虚函数,都必须通过虚函数表VTable来调用,这一点是无比重要的,必需时刻牢记在心。
(2)
COM组件有三个最基本的接口类,分别是IUnknown、IClassFactory、IDispatchCOM规范规定任何组件、任何接口都必须从IUnknown继承,IUnknown包含三个函数,分别是QueryInterface、AddRef、Release。这三个函数是无比重要的,而且它们的排列顺序也是不可改变的。QueryInterface用于查询组件实现的其它接口,说白了也就是看看这个组件的父类中还有哪些接口类,AddRef用于增加引用计数,Release用于减少引用计数。引用计数也是COM中的一个非常重要的概念。大体上简单的说来可以这么理解,COM组件是个DLL,当客户程序要用它时就要把它装到内存里。
另一方面,一个组件也不是只给你一个人用的,可能会有很多个程序同时都要用到它。但实际上DLL只装载了一次,即内存中只有一个COM组件,那COM组件由谁来释放?由客户程序吗?不可能,因为如果你释放了组件,那别人怎么用,所以只能由COM组件自己来负责。所以出现了引用计数的概念,COM维持一个计数,记录当前有多少人在用它,每多一次调用计数就加一,少一个客户用它就减一,当最后一个客户释放它的时侯,COM知道已经没有人用它了,它的使用已经结束了,那它就把它自己给释放了。
引用计数是COM编程里非常容易出错的一个地方,但所幸VC的各种各种的类库里已经基本上把AddRef的调用给隐含了,在我的印象里,我编程的时侯还从来没有调用过AddRef,我们只需在适当的时侯调用Release。至少有两个时侯要记住调用Release,第一个是调用了QueryInterface以后,第二个是调用了任何得到一个接口的指针的函数以后,记住多查MSDN以确定某个函数内部是否调用了AddRef,如果是的话那调用Release的责任就要归你了。
IUnknown的这三个函数的实现非常规范但也非常烦琐,容易出错,所幸的事我们可能永远也不需要自己来实现它们。
IClassFactory的作用是创建COM组件。我们已经知道COM组件实际上就是一个类,那我们平常是怎么实例化一个类对象的?是用‘new’命令!很简单吧,COM组件也一样如此。但是谁来new它呢?不可能是客户程序,因为客户程序不可能知道组件的类名字,如果客户知道组件的类名字那组件的可重用性就要打个大大的折扣了,事实上客户程序只不过知道一个代表着组件的128位的数字串而已,这个等会再介绍。所以客户无法自己创建组件,而且考虑一下,如果组件是在远程的机器上,你还能new出一个对象吗?所以创建组件的责任交给了一个单独的对象,这个对象就是类厂。
每个组件都必须有一个与之相关的类厂,这个类厂知道怎么样创建组件,当客户请求一个组件对象的实例时,实际上这个请求交给了类厂,由类厂创建组件实例,然后把实例指针交给客户程序。这个过程在跨进程及远程创建组件时特别有用,因为这时就不是一个简单的new操作就可以的了,它必须要经过调度,而这些复杂的操作都交给类厂对象去做了。
IClassFactory最重要的一个函数就是CreateInstance,顾名思议就是创建组件实例,一般情况下我们不会直接调用它,API函数都为我们封装好它了,只有某些特殊情况下才会由我们自己来调用它,这也是VC编写COM组件的好处,使我们有了更多的控制机会,而VB给我们这样的机会则是太少太少了。
IDispatch叫做调度接口。它的作用何在呢?这个世上除了C++还有很多别的语言,比如VB、VJ、VBScript、JavaScript等等。可以这么说,如果这世上没有这么多乱七八糟的语言,那就不会有IDispatch。:-)
我们知道COM组件是C++类,是靠虚函数表来调用函数的,对于VC来说毫无问题,这本来就是针对C++而设计的,以前VB不行,现在VB也可以用指针了,也可以通过VTable来调用函数了,VJ也可以,但还是有些语言不行,那就是脚本语言,典型的如VBScript、JavaScript。不行的原因在于它们并不支持指针,连指针都不能用还怎么用多态性啊,还怎么调这些虚函数啊。唉,没办法,也不能置这些脚本语言于不顾吧,现在网页上用的都是这些脚本语言,而分布式应用也是COM组件的一个主要市场,它不得不被这些脚本语言所调用,既然虚函数表的方式行不通,我们只能另寻他法了。时势造英雄,IDispatch应运而生。:-)
调度接口把每一个函数每一个属性都编上号,客户程序要调用这些函数属性的时侯就把这些编号传给IDispatch接口就行了,IDispatch再根据这些编号调用相应的函数,仅此而已。当然实际的过程远比这复杂,当给一个编号就能让别人知道怎么调用一个函数那不是天方夜潭吗,你总得让别人知道你要调用的函数要带什么参数,参数类型什么以及返回什东西吧,而要以一种统一的方式来处理这些问题是件很头疼的事。IDispatch接口的主要函数是Invoke,客户程序都调用它,然后Invoke再调用相应的函数,如果看一看MS的类库里实现Invoke的代码就会惊叹它实现的复杂了,因为你必须考虑各种参数类型的情况,所幸我们不需要自己来做这件事,而且可能永远也没这样的机会。:-)
(3)
dispinterface接口、Dual接口以及Custom接口
这一小节放在这里似乎不太合适,因为这是在ATL编程时用到的术语。我在这里主要是想谈一下自动化接口的好处及缺点,用这三个术语来解释可能会更好一些,而且以后迟早会遇上它们,我将以一种通俗的方式来解释它们,可能并非那么精确,就好象用伪代码来描述算法一样。-:)
所谓的自动化接口就是用IDispatch实现的接口。我们已经讲解过IDispatch的作用了,它的好处就是脚本语言象VBScript、
JavaScript也能用COM组件了,从而基本上做到了与语言无关它的缺点主要有两个,第一个就是速度慢效率低。这是显而易见的,通过虚函数表一下子就可以调用函数了,而通过Invoke则等于中间转了道手续,尤其是需要把函数参数转换成一种规范的格式才去调用函数,耽误了很多时间。所以一般若非是迫不得已我们都想用VTable的方式调用函数以获得高效率。
第二个缺点就是只能使用规定好的所谓的自动化数据类型。如果不用IDispatch我们可以想用什么数据类型就用什么类型,VC会自动给我们生成相应的调度代码。而用自动化接口就不行了,因为Invoke的实现代码是VC事先写好的,而它不能事先预料到我们要用到的所有类型,它只能根据一些常用的数据类型来写它的处理代码,而且它也要考虑不同语言之间的数据类型转换问题。所以VC自动化接口生成的调度代码只适用于它所规定好的那些数据类型,当然这些数据类型已经足够丰富了,但不能满足自定义数据结构的要求。你也可以自己写调度代码来处理你的自定义数据结构,但这并不是一件容易的事。
考虑到IDispatch的种种缺点(它还有一个缺点,就是使用麻烦,现在一般都推荐写双接口组件,称为dual接口,实际上就是从IDispatch继承的接口。我们知道任何接口都必须从IUnknown继承,IDispatch接口也不例外。那从IDispatch继承的接口实际上就等于有两个基类,一个是IUnknown,一个是IDispatch,所以它可以以两种方式来调用组件,可以通过IUnknown用虚函数表的方式调用接口方法,也可以通过IDispatch::Invoke自动化调度来调用这就有了很大的灵活性,这个组件既可以用于C++的环境也可以用于脚本语言中,同时满足了各方面的需要。
相对比的,dispinterface是一种纯粹的自动化接口,可以简单的就把它看作是IDispatch接口(虽然它实际上不是的),这种接口就只能通过自动化的方式来调用,COM组件的事件一般都用的是这种形式的接口。
Custom接口就是从IUnknown接口派生的类,显然它就只能用虚函数表的方式来调用接口了
(4)
COM组件有三种,进程内、本地、远程。对于后两者情况必须调度接口指针及函数参数。
COM是一个DLL,它有三种运行模式。它可以是进程内的,即和调用者在同一个进程内,也可以和调用者在同一个机器上但在不同的进程内,还可以根本就和调用者在两台机器上。
这里有一个根本点需要牢记,就是COM组件它只是一个DLL,它自己是运行不起来的,必须有一个进程象父亲般照顾它才行,即COM组件必须在一个进程内.那谁充当看护人的责任呢?
先说说调度的问题。调度是个复杂的问题,以我的知识还讲不清楚这个问题,我只是一般性的谈谈几个最基本的概念。我们知道对于WIN32程序,每个进程都拥有4GB的虚拟地址空间,每个进程都有其各自的编址,同一个数据块在不同的进程里的编址很可能就是不一样的,所以存在着进程间的地址转换问题。这就是调度问题。对于本地和远程进程来说,DLL和客户程序在不同的编址空间,所以要传递接口指针到客户程序必须要经过调度。Windows经提供了现成的调度函数,就不需要我们自己来做这个复杂的事情了。对远程组件来说函数的参数传递是另外一种调度。
DCOM是以RPC为基础的,要在网络间传递数据必须遵守标准的网上数据传输协议,数据传递前要先打包,传递到目的地后要解包,这个过程就是调度,这个过程很复杂,不过Windows已经把一切都给我们做好了,一般情况下我们不需要自己来编写调度DLL。
我们刚说过一个COM组件必须在一个进程内。对于本地模式的组件一般是以EXE的形式出现,所以它本身就已经是一个进程。对于远程DLL,我们必须找一个进程,这个进程必须包含了调度代码以实现基本的调度。这个进程就是dllhost.exe。这是COM默认的DLL代理。实际上在分布式应用中,我们应该用MTS来作为DLL代理,因为MTS有着很强大的功能,是专门的用于管理分布式DLL组件的工具。
调度离我们很近又似乎很远,我们编程时很少关注到它,这也是COM的一个优点之一,既平台无关性,无论你是远程的、本地的还是进程内的,编程是一样的,一切细节都由COM自己处理好了,所以我们也不用深究这个问题,只要有个概念就可以了,当然如果你对调度有自己特殊的要求就需要深入了解调度的整个过程了,这里推荐一本《COM+技术内幕》,这绝对是一本讲调度的好书。
(5)
COM组件的核心是IDL。
我们希望软件是一块块拼装出来的,但不可能是没有规定的胡乱拼接,总是要遵守一定的标准,各个模块之间如何才能亲密无间的合作,必须要事先共同制订好它们之间交互的规范,这个规范就是接口。我们知道接口实际上都是纯虚类,它里面定义好了很多的纯虚函数,等着某个组件去实现它,这个接口就是两个完全不相关的模块能够组合在一起的关键试想一下如果我们是一个应用软件厂商,我们的软件中需要用到某个模块,我们没有时间自己开发,所以我们想到市场上找一找看有没有这样的模块,我们怎么去找呢?也许我们需要的这个模块在业界已经有了标准,已经有人制订好了标准的接口,有很多组件工具厂商已经在自己的组件中实现了这个接口,那我们寻找的目标就是这些已经实现了接口的组件,我们不关心组件从哪来,它有什么其它的功能,我们只关心它是否很好的实现了我们制订好的接口。这种接口可能是业界的标准,也可能只是你和几个厂商之间内部制订的协议,但总之它是一个标准,是你的软件和别人的模块能够组合在一起的基础,是COM组件通信的标准。
COM具有语言无关性,它可以用任何语言编写,也可以在任何语言平台上被调用。但至今为止我们一直是以C++的环境中谈COM,那它的语言无关性是怎么体现出来的呢?或者换句话说,我们怎样才能以语言无关的方式来定义接口呢?前面我们是直接用纯虚类的方式定义的,但显然是不行的,除了C++谁还认它呢?正是出于这种考虑,微软决定采用IDL来定义接口。说白了,IDL实际上就是一种大家都认识的语言,用它来定义接口,不论放到哪个语言平台上都认识它。我们可以想象一下理想的标准的组件模式,我们总是从IDL开始,先用IDL制订好各个接口,然后把实现接口的任务分配不同的人,有的人可能善长用VC,有的人可能善长用VB,这没关系,作为项目负责人我不关心这些,我只关心你最后把DLL拿给我。这是一种多么好的开发模式,可以用任何语言来开发,也可以用任何语言也欣赏你的开发成果。
(6)
COM组件的运行机制,即COM是怎么跑起来的。
这部分我们将构造一个创建COM组件的最小框架结构,然后看一看其内部处理流程是怎样的
IUnknown *pUnk=NULL;
IObject
*pObject=NULL;
CoInitialize(NULL);
CoCreateInstance(CLSID_Object,
CLSCTX_INPROC_SERVER, NULL,
IID_IUnknown,
(void**)&pUnk);
pUnk->QueryInterface(IID_IOjbect,
(void**)&pObject);
pUnk->Release();
pObject->Func();
pObject->Release();
CoUninitialize();
CoCreateInstance身上,让我们来看看它内部做了一些什么事情。以下是它内部实现的一个伪代码:
CoCreateInstance(....)
{
.......
IClassFactory *pClassFactory=NULL;
CoGetClassObject(CLSID_Object, CLSCTX_INPROC_SERVER, NULL,
IID_IClassFactory,
(void **)&pClassFactory);
pClassFactory->CreateInstance(NULL, IID_IUnknown,
(void**)&pUnk);
pClassFactory->Release();
........
}
这段话的意思就是先得到类厂对象,再通过类厂创建组件从而得到IUnknown指针。
继续深入一步,看看CoGetClassObject的内部伪码:
CoGetClassObject(.....)
{
//通过查注册表CLSID_Object,得知组件DLL的位置、文件名
//装入DLL库
//使用函数GetProcAddress(...)得到DLL库中函数DllGetClassObject的函数指针。
//调用DllGetClassObject
}
DllGetClassObject是干什么的,它是用来获得类厂对象的。只有先得到类厂才能去创建组件.
下面是DllGetClassObject的伪码:
DllGetClassObject(...)
{
......
CFactory*
pFactory= new CFactory;
//类厂对象
pFactory->QueryInterface(IID_IClassFactory,
(void**)&pClassFactory);
//查询IClassFactory指针
pFactory->Release();
......
}
CoGetClassObject的流程已经到此为止,现在返回CoCreateInstance,看看CreateInstance的伪码:
CFactory::CreateInstance(.....)
{
...........
CObject
*pObject = new CObject; //组件对象
pObject->QueryInterface(IID_IUnknown,
(void**)&pUnk);
pObject->Release();
...........
}
(7) 一个典型的自注册的COM
DLL所必有的四个函数
DllGetClassObject:用于获得类厂指针
DllRegisterServer:注册一些必要的信息到注册表中
DllUnregisterServer:卸载注册信息
DllCanUnloadNow:系统空闲时会调用这个函数,以确定是否可以卸载DLL
DLL还有一个函数是DllMain,这个函数在COM中并不要求一定要实现它,但是在VC生成的组件中自动都包含了它,它的作用主要是得到一个全局的实例对象。
(8)
注册表在COM中的重要作用
首先要知道GUID的概念,COM中所有的类、接口、类型库都用GUID来唯一标识,GUID是一个128位的字串,根据特制算法生成的GUID可以保证是全世界唯一的。
COM组件的创建,查询接口都是通过注册表进行的。有了注册表,应用程序就不需要知道组件的DLL文件名、位置,只需要根据CLSID查就可以了。当版本升级的时侯,只要改一下注册表信息就可以神不知鬼不觉的转到新版本的DLL。
本文是本人一时兴起的涂鸭之作,讲得并不是很全面,还有很多有用的体会没写出来,以后如果有时间有兴趣再写出来。希望这篇文章能给大家带来一点用处,那我一晚上的辛苦就没有白费了。-:)
---
本文章使用“国华软件”出品的博客内容离线管理软件MultiBlogWriter撰写并发布
2010年1月19日
#
某高级程序员的几点建议
我始终认为,对一个初学者来说,IT界的技术风潮是不可以追赶的,而且也没有能力去追赶。我时常看见自己的DDMM们把课本扔了,去卖些价格不菲的诸如C#,
VB.Net
这样的大部头,这让我感到非常痛心。而许多搞不清指针是咋回事的BBS站友眉飞色舞的讨论C#里面可以不用指针等等则让我觉得好笑。C#就象当年的ASP一样,“忽如一夜春风来,千树万树梨花开”,结果许多学校的信息学院成了“Web
学院”。96,97级的不少大学生都去做Web
了。当然我没有任何歧视某一行业的意识。我只是觉得如果他们把追赶这些时髦技术的时间多花一点在基础的课程上应该是可以走得更远的。
几个误区
初学者对C#风潮的追赶其实也只是学习过程中经常遇到的几个误区之一。我将用一些实际的例子来说明这些现象,你可以按部就班的看看自己是不是属于其中的一种或者几种:
认为计算机技术等于编程技术:
有些人即使没有这个想法,在潜意识中也有这样的冲动。让我奇怪的是,许多信息学院的学生也有这样的念头。认为计算机专业就是编程专业,与编程无关的,或者不太相关的课程他统统都不管,极端的学生只要书上没带“编程”两个字他就不看。
其实编程只是计算机技术应用过程中一种复杂性最低的劳动,这就是为什么IT业最底层的人是程序员(CODER)。计算机技术包括了多媒体,计算机网络,人工智能,模式识别,管理信息系统等等这些方面。编程工作只是在这些具体技术在理论研究或者工程实践的过程中表达算法的过程。编程的人不一定对计算机技术的了解就一定很高。而一个有趣的现象是,不少大师级的计算机技术研究者是不懂编程的。网上的炒作和现实中良好的工作待遇把编程这种劳动神秘化了。其实每一个程序员心里都明白,自己这些东西,学的时候并不比其它专业难,所以自然也不会高档到哪里去。
咬文嚼字的孔已己作风:
我见过一本女生的《计算机网络原理》教材,这个女生像小学生一样在书上划满了横杠杠,笔记做得满满的,打印出来一定比教材还厚。我不明白的是,像计算机网络原理这样的课程有必要做笔记?我们的应试教育的确害了不少学生,在上《原理》这一类课程的时候许多学生像学《马列原理》一样逐字背诵记忆。这乃是我见过的最愚蠢的行为。所谓《原理》,即是需要掌握它为什么这样做,学习why,而不是how(怎样做)。极端认真的学生背下以太网的网线最大长度,数据帧的长度,每个字段的意义,IP报头的格式等等,但是忘了路由的原则,忘了TCP/IP协议设计的宗旨。总之许多人花了大量的时间把书背得滚瓜烂熟却等于什么也没学。
在学习编程的时候这些学生也是这样,他们确切的记得C++语法的各个细节。看完了C++教程后看《Thinking in
C++》(确实是好书),《Inside C++》,《C++ reference》,this C++, that
C++……,然后是网上各种各样的关于C++语法的奇闻逸事,然后发现自己又忘了C++的一些语法,最后回头继续恶补…。有个师弟就跟我说:“C++
太难了,学了这里忘了那里,学了继承忘了模板。”我的回答道:“你不去学就容易了”。我并没有教坏他,只是告诉他,死抠C++的语法就和孔已己炫耀茴香豆的茴字有几种写法一样毫无意义。你根本不需要对的C++语法太关心,动手编程就是了,有不记得的地方一查MSDN就立马搞定。我有个结论就是,实际的开发过程中对程序语法的了解是最微不足道的知识。这是为什么我在为同学用Basic(我以前从没有学过它)写一个小程序的时候,只花了半个小时看了看语法,然后再用半个小时完成了程序,而一个小时后我又完全忘记了Basic
的所有关键字。
不顾基础,盲目追赶时髦技术:
终于点到题目上来了。大多数的人都希望自己的东西能够马上跑起来,变成钱。这种想法对一个已经进入职业领域的程序员或者项目经理来说是合理的,而且IT技术进步是如此的快,不跟进就是失业。但是对于初学者来说(尤其是时间充裕的大中专在校生),这种想法是另人费解的。一个并未进入到行业竞争中来的初学者最大的资本便是他有足够的时间沉下心来学习基础性的东西,学习why
而不是how。时髦的技术往往容易掌握,而且越来越容易掌握,这是商业利益的驱使,为了最大化的降低软件开发的成本。但在IT领域内的现实就是这样,越容易掌握的东西,学习的人越多,而且淘汰得越快。每一次新的技术出来,都有许多初学者跟进,这些初学者由于缺乏必要的基础而使得自己在跟进的过程中花费大量的时间,而等他学会了,这种技术也快淘汰了。基础的课程,比方数据结构,操作系统原理等等虽然不能让你立马就实现一个linux(这是许多人嘲笑理论课程无用的原因),但它们能够显著的减少你在学习新技术时学习曲线的坡度。而且对于许多关键的技术(比方Win32
SDK 程序的设计,DDK的编程)来说甚至是不可或缺的。
一个活生生的例子是我和我的一个同学,在大一时我还找不到开机按纽,他已经会写些简单的汇编程序了。我把大二的所有时间花在了汇编,计算机体系结构,数据结构,操作系统原理等等这些课程的学习上,而他则开始学习HTML和VB,并追赶ASP的潮流。大三的时候我开始学习Windows
操作系统原理,学习SDK编程,时间是漫长的,这时我才能够用VC开发出象模象样的应用程序。我曾一度因为同学的程序已经能够运行而自己还在学习如何创建对话框而懊恼不已,但临到毕业才发现自己的选择是何等的正确。和我谈判的公司开出的薪水是他的两倍还多。下面有一个不很恰当的比方:假设学习VB编程需要4个月,学习基础课程和VC的程序设计需要1年。那么如果你先学VB,再来学习后者,时间不会减少,还是1年,而反过来,如果先学习后者,再来学VB,也许你只需要1个星期就能学得非常熟练。
几个重要的基础课程
如果你是学生,或者如果你有充足的时间。我建议你仔细的掌握下面的知识。我的建议是针对那些希望在IT技术上有所成就的初学者。同时我还列出了一些书目,这些书应该都还可以在书店买到。说实在的,我在读其他人的文章时最大的心愿就是希望作者列出一个书单。
大学英语-不要觉得好笑。我极力推荐这门课程是因为没有专业文档的阅读能力是不可想象的。中文的翻译往往在猴年马月才会出来,而现在的许多出版社干脆就直接把E文印刷上去。学习的方法是强迫自己看原版的教材,开始会看不懂,用多了自然熟练。吃得苦下得狠心绝对是任何行业都需要的品质。
计算机体系结构和汇编语言-关于体系结构的书遍地都是,而且也大同小异,倒是汇编有一本非常好的书《80x86汇编语言程序设计教程》(清华大学出版社,黑色封面,杨季文著)。你需要着重学习386后保护模式的程序设计。否则你在学习现代操作系统底层的一些东西的时候会觉得是在看天书。
计算机操作系统原理-我们的开发总是在特定的操作系统上进行,如果不是,只有一种可能:你在自己实现一个操作系统。无论如何,操作系统原理是必读的。这就象我们为一个芯片制作外围设备时,芯片基本的工作时序是必需了解的。这一类书也很多,我没有发现哪一本书非常出众。只是觉得在看完了这些书后如果有空就应该看看《Inside
Windows 2000》(微软出版社,我看的是E文版的,中文的书名想必是Windows 2000
技术内幕之类吧)。关于学习它的必要性,ZDNET上的另一篇文章已经有过论述。
数据结构和算法-这门课程能够决定一个人程序设计水平的高低,是一门核心课程。我首选的是清华版的(朱战立,刘天时)。很多人喜欢买C++版的,但我觉得没有必要。C++的语法让算法实现过程变得复杂多了,而且许多老师喜欢用模块这一东西让算法变得更复杂。倒是在学完了C版的书以后再来浏览一下C++的版的书是最好的。
软件工程-这门课程是越到后来就越发现它的重要,虽然刚开始看时就象看马哲一样不知所云。我的建议是看《实用软件工程》(黄色,清华)。不要花太多的时间去记条条框框,看不懂就跳过去。在每次自己完成了一个软件设计任务(不管是练习还是工作)以后再来回顾回顾,每次都会有收获。
Windows 程序设计-《北京大学出版社,Petzold著》我建议任何企图设计Windows
程序的人在学习VC以前仔细的学完它。而且前面的那本《Inside Windows
2000》也最好放到这本书的后面读。在这本书中,没有C++,没有GUI,没有控件。有的就是如何用原始的C语言来完成Windows
程序设计。在学完了它以后,你才会发现VC其实是很容易学的。千万不要在没有看完这本书以前提前学习VC,你最好碰都不要碰。我知道的许多名校甚至都已经用它作为教材进行授课。可见其重要。
上面的几门课程我认为是必学的重要课程(如果你想做Windows 程序员)。
对于其它的课程有这样简单的选择方法:如果你是计算机系的,请学好你所有的专业基础课。如果不是,请参照计算机系的课程表。如果你发现自己看一本书时无法看下去了,请翻到书的最后,看看它的参考文献,找到它们并学习它们,再回头看这本书。如果一本书的书名中带有“原理”两个字,你一定不要去记忆它其中的细节,你应该以一天至少50页的速度掌握其要领。尽可能多的在计算机上实践一种理论或者算法。
你还可以在CSDN上阅读到许多书评。这些书评能够帮助你决定读什么样的书
一日三省
每天读的书太多,容易让人迷失方向。一定要在每天晚上想想自己学了些什么,还有些什么相关的东西需要掌握,自己对什么最感兴趣,在一本书上花的时间太长还是不够等等。同时也应该多想想未来最有可能出现的应用,这样能够让你不是追赶技术潮流而是引领技术潮流。同时,努力使用现在已经掌握的技术和理论去制作具有一定新意的东西。坚持这样做能够让你真正成为一个软件“研发者”而不仅仅是一个CODER。
把最多的时间花在学习上
这是对初学者最后的忠告。把每个星期玩CS或者CS的时间压缩到最少,不玩它们是最好的。同时,如果你的ASP技术已经能够来钱,甚至有公司请你兼职的话,这就证明你的天分能够保证你在努力的学习之后取得更好的收益,你应该去做更复杂的东西。眼光放长远一些,这无论是对谁都是适用的。
---
本文章使用“国华软件”出品的博客内容离线管理软件MultiBlogWriter撰写并发布
[ 批处理压缩好助手:压缩圣手Zipghost ]
--------------------------------------------------------------------------------
编者按:
在日常的学习工作中,我们会经常用到压缩软件,它可以帮我们节省更多的硬盘空间。但有时我们需要一次性进行大量的软件压缩工作,这时传统的压缩软件就显得有点力不从心了。
--------------------------------------------------------------------------------
在日常的学习工作中,我们会经常用到压缩软件,它可以帮我们节省更多的硬盘空间。但有时我们需要一次性进行大量的软件压缩工作,这时传统的压缩软件就显得有点力不从心了。
不过我们可以使用一款叫做Zipghost(压缩圣手)的小软件来完成批量压缩文件的任务,它在批处理压缩方面设计得很好,能满足我们大多数的压缩需求。
下载Zipghost(压缩圣手),将软件安装好后运行
1.把整个文件夹压缩成一个ZIP文件
这个功能是我们平时最常用的,只要在软件主界面的左边选择一文件夹,然后在“ZIP压缩选项”中选择“只生成惟一一个ZIP文件”和“在原文件名后添加.zip”两个选项,就可以把文件夹压缩成一个ZIP文件。
2.把每个文件各压缩成一个ZIP文件
如果我们要将文件夹下的每个文件各自压缩成一个ZIP文件,那么要在“ZIP压缩选项”中选择“每个文件分别生成ZIP文件”,如果我们选择的文件夹下还有子文件夹,那么可以选择“包含所有子目录”,这样连子文件夹内包含的文件也会被各自压缩成单独的ZIP文件了。
3.把各子目录压缩成ZIP文件
如果我们要批量压缩的不是单独的文件,而是选中的文件夹下的各个子目录,那么我们可以在ZIP压缩选项中先选择“包含所有子目录”选项,然后再选择“每个目录各生成一个ZIP文件”选项即可。
(作者:傲剑)
文章出处:《中国电脑教育报》
---
本文章使用“国华软件”出品的博客内容离线管理软件MultiBlogWriter撰写并发布
2010年1月18日
#
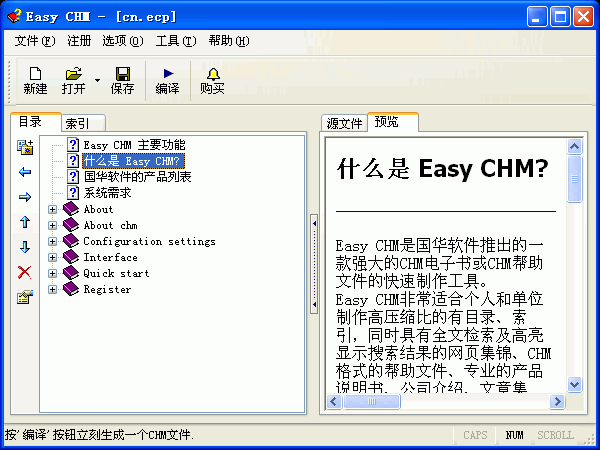
Easy CHM是国华软件推出的一款强大的CHM电子书或CHM帮助文件的快速制作工具。
使用EasyCHM只需要三个步骤就可以完成CHM的制作:
1、用户指定一个目录,EasyCHM会自动导入全部目录及文件;
2、设置CHM编译选项;
3、开始制作。
EasyCHM非常适合个人和单位制作高压缩比的带有全文检索及高亮显
示搜索结果的网页集锦、CHM帮助文件、专业的产品说明、公司介绍、CHM电子书等等。
EasyCHM主要产品功能:
全自动的目录及文件导入(可以包括子目录);
EasyCHM支持导入任意的文件类型;
EasyCHM操作速度快,性能稳定,EasyCHM因为上手容易深得广大用户好评;
EasyCHM自动生成CHM的目录列表并自动生成所有目录项;
为CHM的目录列表自动添加多级编号;
在编辑目录项、索引项时用到的移动、拖拽、替换等操作中Easy
CHM完全支持多选操作,避免了一项一项地操作,极大的减少用户手工 - 非常适合企业维护CHM帮助文档;
支持批量查找替换多级目录各项的标题文字内容;
允许用户指定从文本文件的第N行自动截取标题;
易用的目录编辑器;
EasyCHM具有丰富实用的CHM制作选项帮助用户制作更加个性化的专业CHM电子书或CHM帮助文件;
EasyCHM自动生成输出Alias和Map头文件;
EasyCHM自动生成上下文相关的帮助文件(ContextID),适合于制作专业的支持Help Context ID的专业帮助文件;
EasyCHM可以保存工程文件,方便企业用户编辑维护文档。
批量更换CHM目录各项的图标;
EasyCHM内嵌CHM反编译工具;
EasyCHM未注册版本的主要限制:
EasyCHM的未注册版本可以制作带任意层级目录的CHM,但是每个CHM的工具栏上都会自动添加一个ABOUT按钮,以提醒用户注册。注册版本不会添加ABOUT按钮。
EasyCHM的未注册版本无法保存CHM的通用工程文件,如*.HHP、*.HHC、*.HHK等文件,未注册版本的EasyCHM会自动删除*.HHP、*.HHC、*.HHK这几个文件。
下载地址:
http://www.zipghost.com/cn/download.html
软件介绍:
http://www.zipghost.com/cn/easychm.html
截图:
http://www.zipghost.com/images/EasyCHM_Main_Screen_CN.gif
软件加密时保护软件著作权要注意避免的思路误区
一、问题的提出
首先引用有关“ECC加密算法”介绍的原文结尾部分内容:
“七、椭圆曲线在软件注册保护的应用
.......
软件验证过程如下:(软件中存有椭圆曲线Ep(a,b),和基点G,公开密钥K)
.......
4、如果H=Hash 则注册成功。如果H≠Hash ,则注册失败。
.......
Cracker要想制作注册机,只能通过软件中的Ep(a,b),点G,公开密钥K ,
并利用K=kG这个关系获得k后才可以。而求k是很困难的。
练习:
.......
软件验证过程如下:(软件中存有椭圆曲线Ep(a,b),和基点G,公开密钥K)
.......
5、如果v=x’ 则注册成功。如果v≠x’,则注册失败。”
一般说来,如果编码算法本身具有起码的强度,而且没有变形(等价)算法等漏洞,被该编码算法保护的软件,解密者的确不大可能在短期内有针对性地开发出实用的注册机,前提是无法改动被保护软件代码。问题是国内外的Cracker是很聪明的,如果发现不能很快地破解出“有效”的注册码,就会直接或间接“篡改”被“Crack”的软件代码,比如将上述
“ 4、如果H=Hash 则注册成功。如果H≠Hash
,则注册失败。”
“ 5、如果v=x’ 则注册成功。如果v≠x’ ,则注册失败。”
所涉及的显式或隐式条件判断语句“转向”而让程序代码违背软件作者的意愿“流动”。
所以,简单地通过条件判断语句来“甄别”合法用户,可能是保护软件著作权思路里普遍存在的一个明显误区!而且由来已久,特别是在用C语言编写的软件里,这样的例子不胜枚举。
一旦进入这个误区,那么不论应用软件的认证模块里使用何等保护强度的编码算法,也不论该编码算法是基于对称密匙还是非对称密匙,都难逃被“Crack”的命运,原因就在于“简单地通过条件判断语句来‘甄别’合法用户”导致应用软件著作权的保护异常脆弱!
就连专业公司都存在这样的安全隐患,国内某专业生产微机安全产品的公司,在其号称异常“坚固”的加密组件里,尽管是基于RSA编码体系,遗憾的是,由于存在上述思路误区,仅仅只花了2天时间,竟然在一台Pentium
150MHz的机器上被破解。
可见目前这个误区普遍没有引起足够的重视,情况令人担忧。
大家都知道,对用户输入的涉及著作权的各项认证信息,软件作者都会将这些认证信息作为原始算子,参与认证模块里软件作者“处心积虑”构造的越来越复杂的运算,甚至罕见的特殊指令都被应用了。目的只有一个,就是通过异常严格的认证过程来保护自己的软件著作权,问题是如此“费尽心思”得到的认证结果,被简单地应用在一次条件判断语句上,判断一结束,认证结果也随即丢弃了,顶多也就是在软件的其它模块里再“依葫芦画瓢”地多来几次相同的条件判断。比如上述原文里的“H”及“v”只是简单地参与了一次条件判断就可能被丢弃了!如果“H”及“v”能得到更好地“应用”将使得该保护更强壮。
可能有同行会说,为防止Cracker直接“篡改”软件代码,对软件加上保护“壳”好了,但是大家要知道,加保护“壳”的做法实际上并不可靠,这体现在二个方面:
1、这是以牺牲被保护软件的性能甚至稳定性为代价的,被层层“包裹”了保护“壳”的软件(似乎获此“待遇”的往往是应用软件),在此微机可以运行,换一台微机特别是基于不同处理器体系结构的微机上却运行不稳定甚至不能运行,越是“强悍”的保护“壳”就越容易遇到这样的问题。
上述问题的原因在于标称“强悍”的保护“壳”为防止被“调试”而在该保护“壳”的解码过程里,对其有读写“权限”的硬件寄存器/系统核心数据表等重要系统资源持续“复位/篡改”,真可谓“各显神通,无所不用其极”!而这些做法,稍有疏漏或因为计算环境的变化,被保护软件就可能运行错误甚至导致操作系统瘫痪。如果被保护软件连稳定运行(可再现计算结果)这个起码要求都打折扣,保护“壳”还有意义么?
2、再“强悍”的保护“壳”最后还是要在其解码的过程里“还原”被保护软件的,而不论其是逐步还原或是一次性全部还原。这就应了“以己之矛攻己之盾”的老话,所以不管如何“强悍”的保护“壳”,一经推出,很快就会出现解除该保护“壳”的软件,而不论该软件是通用的或是有针对性的。公开发行特别是通过互联网发行的软件,面对的是国内外的潜在用户群,其著作权(商业秘密)保护思路(方式)面临的挑战也将直接来自国内外技术一流的Cracker。
可见,用保护“壳”来保护软件著作权,不能真正可靠地保护软件著作权!至少在防止Cracker“篡改”软件代码方面。
当然,有能力开发保护“壳”的程序员水平都是一流的!行业主管部门在这些方面也是鼓励“百花齐放、百家争鸣”的,自然界里同样存在“生物多样性”。可执行文件的保护与破解本来就是矛盾的一体二面,保护“壳”的推陈出新也直接促进了相关技术的长足发展,如果将这些“对抗性实战”案例作为“基础教育”予以普及一定可以培养更多的后起之秀。
问题是我们更要将注意力放在主要方面,要思考最“根本”的问题,毕竟保护“壳”技术只是计算机信息安全领域里很小的一个方面。大家是否还记得海南“军机”碰撞引发的Hacker大战?大家就一定明白我们自己的弱势在哪里了!少数西方发达国家对我们实施技术封锁,不管这些技术是民用还是军用。比如加密强度稍大些的设备(软件)就被其列入所谓的“战略物资”名单实施出口管制,每次我国推出自行研制的新型“超级”计算机,西方发达国家就不得不相应放宽其出口管制。“落后就要挨打”只有“自强不息”才能“振兴中华”!
明白了保护软件著作权思路里普遍存在的一个明显误区,那么如何才能避免走入这个误区?怎样才能更有效地保护我们的软件著作权(商业秘密)?
二、问题的解决
我们知道,每一套应用软件都有其作者值得骄傲或特别着力的地方,具体体现在软件里有限的几个核心功能上,而这些核心功能的代码正是其作者需要花大力气保护的,前述“千辛万苦”得到认证结果,既然不能简单应用在一次条件判断语句上,那么怎样才能更好地应用这个“来之不易”的认证结果呢?从而使我们的应用软件著作权(商业秘密)得到更有效的保护!
关键在于认证工作的“继承”上,如何继承——
“不论前述认证结果正确与否,都将该认证结果再次作为算子,经过必要运算后对发行前已受保护的软件核心功能代码进行解码”。
当然,我们强调软件核心功能代码在发行前已被保护,而且是被长度至少为128位即16个字节的单向HasH密匙保护(相应地采用经广泛测试的稳健的算子长度至少为128位的编码算法如128位MD5等)。应用软件如果没有正式注册,核心功能代码自然未被解码,用户也会被提示“功能受限,建议注册”。
如此保护后,如果编码算法没有明显漏洞,要想“Crack”如此加密强度的被保护软件除了穷举,可能短期内很难找到其它的实用方法,这样的保护壁垒会让相当一部分使用常规手段的Cracker望而却步了——要知道算子长度至少为128位的稳健编码算法,要破解之需要大功率计算机或者性能优异的并行算法,而这些对于注册费用低廉的Shareware来说,已经没有意义了。而“穷举”又具有相当的难度!
万一128位单向HasH密匙泄露,软件作者只需“简单”地在新版本里改用新的128位单向HasH密匙重新对核心功能代码进行编码保护后再发行即可!保护“壳”方法可没有如此简单的“快速反应机制”。
即使退一万步,如此保护的软件还是被一个“天才”一夜之间成功破解,那么软件作者只要再次“简单”地在新版本里改用256位甚至更长的单向HasH密匙重新对核心功能代码进行编码保护即可!保护“壳”方法同样没有如此简单的“快速反应机制”。
通过上述对软件著作权的有效保护,软件作者可以将工作重点完全放在如何开发功能更强大的应用软件或完善软件的核心功能,而不再每次发行一个新版本之前都必须“煞费苦心”地设计保护软件著作权的认证模块,这将有力地促进我国应用软件的品质达标!而且应用软件的非核心功能的代码完全可以“明码”出现——不需要“保护”,只要Cracker愿意,想反汇编就反汇编好了,想逆向工程就逆向工程好了。这也最大限度地保证应用软件的测试进而保证应用软件的稳定性,因为程序里未被保护的“常规”指令都在相当“常规”地被处理器逐一执行,被保护前的软件核心功能也是由“常规”指令实现的,而单向解码指令又是相当“常规”的“移位”、“异或”以及四则运算等!所有的这些“常规”就意味着软件代码的“简单”——“简单就意味着效率,简单就意味着稳定”!
惟独被保护的核心功能代码,在解码前只能是“一团乱麻”不具可读性,而技术一流的Cracker面对的不是保护软件著作权技术参差不齐的应用软件程序员,而是面对经过广泛测试的世界级的成熟密码学实践成果,“义无返顾”地破解,结果要么是Cracker震惊世界密码学界,要么则是让Cracker无功而返。当单向密匙长度超过1024位的时候,恐怕只有.......才有兴趣,才有能力破解。
对于成功破解128位或以上单向密匙的Cracker,我个人认为,只要这位Cracker不扩散因成功破解而得到的128位甚至更长的单向密匙!作为软件作者对其的奖励,尽管放心让这位“天才”Cracker“合法”使用这个破解的“注册”版本好了,因为面对其成功破解,软件作者也不得不表示佩服!
可能有人会说,那只要向软件作者“正式”注册一次(对于注册提供“网上支付”的软件甚至使用“黑”信用卡)不就得到那令人“梦寐以求”的128位甚至长度更长的单向HasH密匙了?你还别说,这“损”招还真的管用,只是这对于稍有个性的Cracker来说,却是不屑的。
结论
关于如何更有效地保护软件著作权,我的个人建议(仅供参考):
a、公开发行的应用软件里的核心功能代码被长度至少为128位即16个字节的单向密匙保护(必须采用严格的128位或以上的编码算法);
b、对用户输入的各项认证信息进行认证后产生一个长度至少为128位即16个字节的单向HasH密匙;
c、产生的单向HasH密匙整体不参与任何条件比较,不论其正确与否都在合适的时候作为算子经必要单向运算后参与核心功能代码的解码;
d、核心功能代码被解码后,如果是真正的“合法”用户,核心功能自然顺利执行,否则应用软件提示出错(肯定会出错的)。
至于如此保护后是否还需要为公开发行的软件加上保护“壳”呢?这点随个人习惯好了。
如此这般地说了一通,只是想表达一些自己很早就有了的看法,希望通过贵学院,转告即将成为Cracker的后期之秀,是可以让其少走弯路的,希望不久的将来,计算机信息安全这个行当不再由外国人唱独角戏了。
我来说两句。
ECC签名算法ECDSA是用来防写注册机的,即便是注册用户,也无法写出注册机。
他比DSA有许多优点,比如密钥短而加密强度高。
162bit的ECC密钥
相当于1024bit的RSA密钥的加密强度。
可以说ECDSA或RSA可以在很长的时间内,从根本上杜绝注册机的出现(前提是随机数没有问题)
这当然是基于现有的CPU速度而言的。
ECC是防注册机,不是防爆破的。如果所有的软件都使用签名算法,KeyGen这东西基本上就要消失了。
关于防爆破问题,从理论上说,只要软件可以在机器上正常运行所有功能一次,这个软件就可以有爆破版,因此无论你如何做,也无法防止正版用户的破解。
这也是就是说,随着保密技术的不断加强,Cracker业余爱好者将无软件可pj
因为pj模式会变成这样
1、D版商或Cracker业余爱好者从软件作者那里购得软件正确的注册码或Keyfile
2、实行pj
3、将pj版发布到网上供他人下载
因为要涉及到购买环节,所以说Cracker为了自己的爱好,很难不和盗版商勾结。(不幸)
我认为彻底解决这个问题只有Server-Client模式
将关键代码做成接口,放在服务端。客户端只有输入正确的用户名和密码,服务器才会运行这个接口,并将结果返回给客户程序。当然客户端增多,会加大服务器的负担。
这样所有的Cracker就要转行当hacker了
---
本文章使用“国华软件”出品的博客内容离线管理软件MultiBlogWriter撰写并发布